Migração S3 - Azure Blob Storage com Ansible e Azure Data Factory
Em um projeto de migração real, precisamos mover os dados de dezenas de buckets S3 de clientes para o Azure Blob Storage. O processo manual - criar o ADF no portal, configurar cada linked service, montar a pipeline, disparar e monitorar - era repetitivo e propenso a erro. A solução foi um único playbook Ansible que provisiona toda a infraestrutura e executa a cópia de ponta a ponta.
Objetivo do Lab
Construir um playbook Ansible que automatiza completamente a migração de dados de um bucket AWS S3 para um container no Azure Blob Storage, usando o Azure Data Factory como motor de cópia. O playbook cria todos os recursos necessários, dispara a pipeline e faz polling do status até confirmar o sucesso (ou falha explícita).
Tecnologias Utilizadas
Ansible é uma ferramenta de automação de infraestrutura sem agente. Ela executa tarefas em sequência, em formato YAML, sem precisar instalar nada nos servidores de destino. É amplamente usada para provisionar recursos em nuvem via CLI, configurar servidores e orquestrar fluxos de deploy.
Azure Data Factory (ADF) é o serviço de integração de dados da Microsoft. Ele permite criar pipelines visuais (ou via API/CLI) que copiam, transformam e movem dados entre fontes heterogêneas - como AWS S3 e Azure Blob Storage. O ADF escala automaticamente, tem retry nativo e gera logs detalhados para cada execução.
AWS S3 (Simple Storage Service) é o serviço de armazenamento de objetos da Amazon. Os dados ficam organizados em buckets, e o acesso externo é controlado por IAM com AccessKey e SecretKey.
Azure Blob Storage é o equivalente ao S3 na Azure. Dados são armazenados em containers dentro de uma Storage Account. Suporta acesso via connection string, Managed Identity ou SAS token.
az CLI é a interface de linha de comando da Azure. Permite criar e gerenciar recursos diretamente do terminal, sem usar o portal. O Ansible chama o az CLI via módulo command, que é a forma mais direta e sem dependências extras.
Arquitetura
┌─────────────────────────────────────────────────────────────────┐
│ AWS Account │
│ ┌─────────────┐ │
│ │ S3 Bucket │ ← s3:GetObject + s3:GetObjectVersion │
│ └──────┬──────┘ │
└─────────┼───────────────────────────────────────────────────────┘
│
│ HTTPS (LinkedService_S3 - AccessKey)
▼
┌─────────────────────────────────────────────────────────────────┐
│ Azure (Resource Group) │
│ │
│ ┌─────────────────────────────────────────────────────────┐ │
│ │ Azure Data Factory (ADF) │ │
│ │ │ │
│ │ Dataset_S3 ──[CopyActivity]──► Dataset_Blob │ │
│ │ (BinarySource) (BinarySink) │ │
│ │ parallelCopies=4 / DIU=4 │ │
│ └──────────────────────────┬──────────────────────────────┘ │
│ │ │
│ │ LinkedService_BlobStorage │
│ ▼ │
│ ┌──────────────────────────────────────────────────────────┐ │
│ │ Storage Account: stdadosmigrados │ │
│ │ └── Container: dados-migrados │ │
│ └──────────────────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────────────────┘
▲
│ ansible-playbook playbook.yml -e @vars.yml
│
┌─────────┴──────────┐
│ Control Node │
│ Ansible + az CLI │
└────────────────────┘
| Componente | Função |
|---|---|
| S3 Bucket | Origem dos dados. IAM com s3:GetObject e s3:GetObjectVersion |
| Azure Data Factory | Orquestra a cópia. Gerencia linked services, datasets e pipeline |
| LinkedService_S3 | Credencial do ADF para autenticar no S3 (AccessKey) |
| LinkedService_Blob | Credencial do ADF para gravar no Blob (connection string) |
| Dataset_S3 | Define o caminho de origem: bucket + prefixo |
| Dataset_Blob | Define o destino: storage account + container |
| Pipeline CopyActivity | Executa a cópia com parallelCopies=4 e DIU=4 |
| Storage Account | Conta de armazenamento Azure que recebe os dados |
| Container | Namespace dentro da Storage Account (equivale a um bucket) |

Como as Partes se Conectam
O ADF age como intermediário inteligente: ele autentica no S3 usando as credenciais do IAM, lê os objetos (recursivamente, se configurado), e grava em paralelo no Blob Storage usando a connection string da Storage Account. A pipeline usa formato Binary em ambos os lados - isso preserva os arquivos como estão, sem transformação, o que é exatamente o que queremos em uma migração de dados brutos.
O Ansible não move nenhum dado diretamente. Ele é responsável por orquestrar o provisionamento de todos os recursos no az CLI e, ao final, fazer polling do runId da pipeline até receber Succeeded ou Failed.
Estrutura do Projeto
ansible-adf-migrate-s3-azure/
├── playbook.yml # playbook principal - tudo em um só arquivo
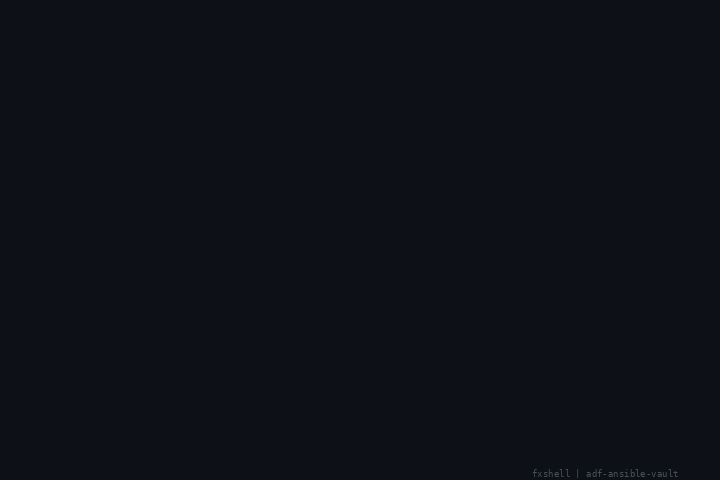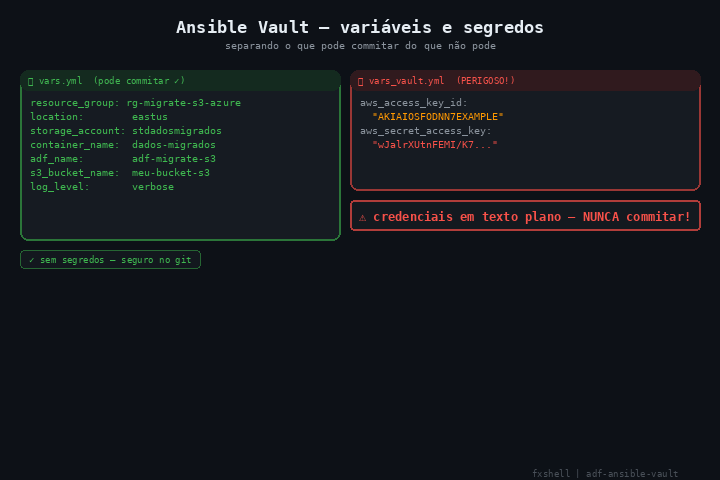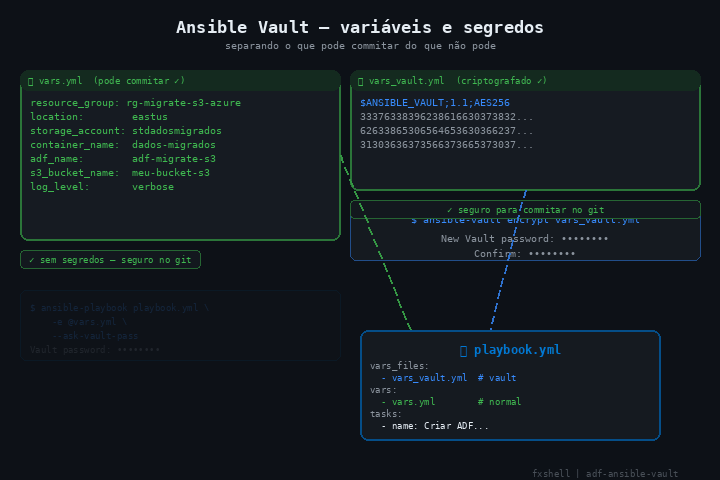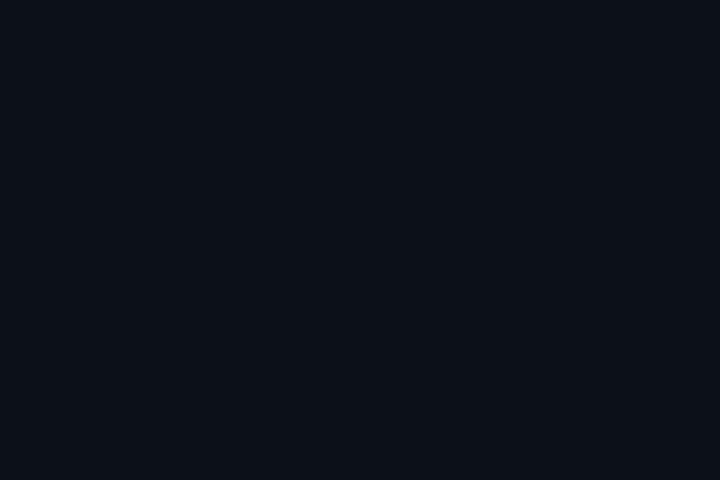
├── vars.yml # variáveis não-sensíveis (pode commitar)
├── vars_vault.yml # credenciais AWS - criptografar com ansible-vault
└── diagrama/
├── gerar_gif.py
├── ansible-adf-migrate-s3-azure.gif
└── ansible-adf-migrate-s3-azure.html
Pré-requisitos
Antes de executar, você precisa:
- az CLI instalado e autenticado (
az login) - Ansible instalado (
pip install ansible) - IAM user na AWS com permissões:
s3:GetObjects3:GetObjectVersion
- ansible-vault para criptografar as credenciais AWS
Preparando as Variáveis
vars.yml - configure com os valores do seu ambiente:
resource_group: "rg-migrate-s3-azure"
location: "eastus"
storage_account_name: "stdadosmigrados"
container_name: "dados-migrados"
adf_name: "adf-migrate-s3"
adf_pipeline_name: "pipeline-s3-to-blob"
s3_bucket_name: "meu-bucket-s3"
s3_region: "us-east-1"
s3_prefix: "" # vazio = copia tudo; ou "pasta/" para subdiretório
log_level: verbose
vars_vault.yml - nunca commitar sem criptografia:
aws_access_key_id: "AKIAIOSFODNN7EXAMPLE"
aws_secret_access_key: "wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY"
Criptografar antes de qualquer commit:
ansible-vault encrypt vars_vault.yml
Playbook - Explicação por Bloco
O playbook está dividido em 9 tasks principais mais pre_tasks e post_tasks.
pre_tasks - Verificação de Ambiente
pre_tasks:
- name: Verificar az CLI instalado
command: az --version
changed_when: false
failed_when: az_check.rc != 0
- name: Verificar login na Azure
command: az account show
changed_when: false
failed_when: az_account.rc != 0
Falha imediatamente se o az CLI não estiver instalado ou se não houver sessão ativa. Economiza tempo debugando tasks que viriam depois.
Tasks 1-2 - Resource Group e Storage Account
- name: "[ 1/9 ] Criar Resource Group"
command: >
az group create
--name {{ resource_group }}
--location {{ location }}
--output none
- name: "[ 2/9 ] Criar Storage Account"
command: >
az storage account create
--name {{ storage_account_name }}
--resource-group {{ resource_group }}
--sku Standard_LRS
--kind StorageV2
--access-tier Hot
--output none
- name: "[ 2/9 ] Criar container com acesso privado"
command: >
az storage container create
--name {{ container_name }}
--account-name {{ storage_account_name }}
--public-access off
--auth-mode login
--output none
O container é criado com public-access off - o acesso é controlado pelo ADF via connection string, não por URL pública. Isso é diferente de quando você quer servir arquivos via CDN (nesse caso, --public-access blob).
Tasks 3-5 - ADF e Linked Services
- name: "[ 3/9 ] Criar Azure Data Factory"
command: >
az datafactory factory create
--factory-name {{ adf_name }}
--resource-group {{ resource_group }}
--location {{ location }}
- name: "[ 4/9 ] Criar Linked Service - AWS S3"
command: >
az datafactory linked-service create
--factory-name {{ adf_name }}
--linked-service-name {{ adf_linked_s3_name }}
--properties '{
"type": "AmazonS3",
"typeProperties": {
"accessKeyId": "{{ aws_access_key_id }}",
"secretAccessKey": {
"type": "SecureString",
"value": "{{ aws_secret_access_key }}"
},
"authenticationType": "AccessKey"
}
}'
no_log: true # nunca logar credenciais
O no_log: true garante que a task não apareça em logs de auditoria com as credenciais expostas. Sempre usar em tasks que passam segredos como argumento de CLI.

Tasks 6-7 - Datasets e Pipeline
Os datasets definem o “onde” da cópia: o S3 como AmazonS3Location com bucketName e folderPath, e o Blob como AzureBlobStorageLocation com container. Ambos usam tipo Binary - sem transformação de dados.
A pipeline usa parallelCopies: 4 e dataIntegrationUnits: 4, que é o mínimo para extrair performance razoável em objetos médios. Para migrações de terabytes, aumentar para 32 DIUs.
Tasks 8-9 - Execução e Polling
- name: "[ 8/9 ] Executar pipeline"
command: >
az datafactory pipeline create-run
--factory-name {{ adf_name }}
--name {{ adf_pipeline_name }}
register: pipeline_run
- name: "[ 9/9 ] Aguardar conclusão (polling 30s)"
command: >
az datafactory pipeline-run show
--run-id {{ run_id }}
--query status --output tsv
until: pipeline_status.stdout.strip() in ['Succeeded', 'Failed', 'Cancelled']
retries: 120
delay: 30
O until com retries: 120 e delay: 30 cobre até 1 hora de execução. Para buckets muito grandes, aumentar retries.

Executando
# 1. criptografar credenciais AWS
ansible-vault encrypt vars_vault.yml
# 2. executar o playbook
ansible-playbook playbook.yml -e @vars.yml --ask-vault-pass
# 3. verificar o resultado no portal
# https://adf.azure.com
Para testar sem criar recursos (dry-run não funciona com az CLI, mas você pode checar a sintaxe YAML):
ansible-playbook playbook.yml --syntax-check
Após a migração, verificar os blobs via CLI:
az storage blob list \
--container-name dados-migrados \
--account-name stdadosmigrados \
--auth-mode login \
--query "[].name" \
--output table
Monitoramento e Troubleshooting
| Sintoma | Causa provável | Solução |
|---|---|---|
AuthorizationFailure no linked service S3 |
IAM sem s3:GetObject |
Adicionar a policy no IAM user da AWS |
StorageErrorCode: AuthorizationFailure no Blob |
az CLI sem role no storage | Atribuir Storage Blob Data Contributor ao usuário |
Pipeline travada em InProgress |
DIU insuficiente para o volume | Aumentar dataIntegrationUnits na pipeline |
Pipeline terminated with status: Failed |
Erro na cópia de objeto específico | Verificar logs no ADF Monitor: https://adf.azure.com |
az: command not found |
az CLI não instalado | curl -sL https://aka.ms/InstallAzureCLIDeb | sudo bash |
retries exceeded no polling |
Pipeline demorou mais de 1h | Aumentar retries no playbook |
Para Que Serve no Mercado
Migrações de cloud são comuns em contextos de aquisição de empresa, mudança de provedor, ou consolidação de infraestrutura. Ter um playbook parametrizado para esse fluxo permite que o time de DevOps ou SRE replique a operação para N buckets com mínima intervenção - só ajusta s3_bucket_name, container_name e roda.
O ADF também é usado para sincronização contínua com triggers agendados, não só migração one-shot. O mesmo playbook pode ser adaptado para provisionar um trigger no ADF que executa a pipeline periodicamente.
Conclusão
A combinação Ansible + ADF é mais robusta do que scripts de shell com aws s3 sync + azcopy porque o ADF gerencia o estado da cópia, faz retry automático em falhas transitórias e dá visibilidade detalhada no portal. O Ansible garante que toda a infraestrutura é declarativa, versionada e reproduzível - rodar duas vezes não cria recursos duplicados.
A migração real que deu origem a este lab copiou 10GB em aproximadamente 9 minutos com configuração padrão de 4 DIUs.
Referências
- Azure Data Factory - documentação oficial
- Copiar dados do Amazon S3 para o Azure Blob Storage
- az datafactory - referência CLI
- Ansible command module
- Azure Blob Storage - documentação
Playbook Completo
---
# =============================================================================
# Migração S3 → Azure Blob Storage via Azure Data Factory
# Playbook: playbook.yml
# Autor: fxshell
# Uso: ansible-playbook playbook.yml -e @vars.yml --ask-vault-pass
# =============================================================================
- name: Migração S3 → Azure Blob Storage via ADF
hosts: localhost
connection: local
gather_facts: false
vars_files:
- vars_vault.yml # arquivo criptografado com ansible-vault
vars:
resource_group: "rg-migrate-s3-azure"
location: "eastus"
storage_account_name: "stdadosmigrados"
container_name: "dados-migrados"
adf_name: "adf-migrate-s3"
adf_pipeline_name: "pipeline-s3-to-blob"
adf_linked_s3_name: "LinkedService_S3"
adf_linked_blob_name: "LinkedService_BlobStorage"
adf_dataset_s3_name: "Dataset_S3"
adf_dataset_blob_name: "Dataset_Blob"
s3_bucket_name: "meu-bucket-s3"
s3_region: "us-east-1"
# Prefixo de objetos a migrar (vazio = tudo)
s3_prefix: ""
# Nível de log: verbose | normal
log_level: normal
# ---------------------------------------------------------------------------
# PRÉ-REQUISITOS: verificar dependências antes de qualquer task
# ---------------------------------------------------------------------------
pre_tasks:
- name: Verificar az CLI instalado
command: az --version
register: az_check
changed_when: false
failed_when: az_check.rc != 0
- name: Verificar login na Azure (az account show)
command: az account show
register: az_account
changed_when: false
failed_when: az_account.rc != 0
- name: Exibir subscription ativa
debug:
msg: "Subscription ativa: {{ (az_account.stdout | from_json).name }}"
when: log_level == "verbose"
# ---------------------------------------------------------------------------
# BLOCO 1 - Resource Group
# ---------------------------------------------------------------------------
tasks:
- name: "[ 1/9 ] Criar Resource Group {{ resource_group }}"
command: >
az group create
--name {{ resource_group }}
--location {{ location }}
--output none
register: rg_result
changed_when: '"Succeeded" in rg_result.stdout or rg_result.rc == 0'
# ---------------------------------------------------------------------------
# BLOCO 2 - Storage Account + Container
# ---------------------------------------------------------------------------
- name: "[ 2/9 ] Criar Storage Account {{ storage_account_name }}"
command: >
az storage account create
--name {{ storage_account_name }}
--resource-group {{ resource_group }}
--location {{ location }}
--sku Standard_LRS
--kind StorageV2
--access-tier Hot
--output none
register: sa_result
changed_when: sa_result.rc == 0
- name: "[ 2/9 ] Obter connection string do Storage Account"
command: >
az storage account show-connection-string
--name {{ storage_account_name }}
--resource-group {{ resource_group }}
--query connectionString
--output tsv
register: sa_conn_string
changed_when: false
no_log: true
- name: "[ 2/9 ] Criar container '{{ container_name }}' com acesso privado"
command: >
az storage container create
--name {{ container_name }}
--account-name {{ storage_account_name }}
--public-access off
--auth-mode login
--output none
register: container_result
changed_when: container_result.rc == 0
# ---------------------------------------------------------------------------
# BLOCO 3 - Azure Data Factory
# ---------------------------------------------------------------------------
- name: "[ 3/9 ] Criar Azure Data Factory {{ adf_name }}"
command: >
az datafactory factory create
--factory-name {{ adf_name }}
--resource-group {{ resource_group }}
--location {{ location }}
--output none
register: adf_result
changed_when: adf_result.rc == 0
- name: "[ 3/9 ] Obter ID do Storage Account para ADF"
command: >
az storage account show
--name {{ storage_account_name }}
--resource-group {{ resource_group }}
--query id
--output tsv
register: sa_id
changed_when: false
# ---------------------------------------------------------------------------
# BLOCO 4 - Linked Service: AWS S3
# ADF precisa de access key + secret key com permissões s3:GetObject
# e s3:GetObjectVersion no bucket de origem
# ---------------------------------------------------------------------------
- name: "[ 4/9 ] Criar Linked Service - AWS S3"
command: >
az datafactory linked-service create
--factory-name {{ adf_name }}
--resource-group {{ resource_group }}
--linked-service-name {{ adf_linked_s3_name }}
--properties '{
"type": "AmazonS3",
"typeProperties": {
"serviceUrl": "https://s3.amazonaws.com",
"accessKeyId": "{{ aws_access_key_id }}",
"secretAccessKey": {
"type": "SecureString",
"value": "{{ aws_secret_access_key }}"
},
"authenticationType": "AccessKey"
}
}'
register: ls_s3_result
changed_when: ls_s3_result.rc == 0
no_log: true
# ---------------------------------------------------------------------------
# BLOCO 5 - Linked Service: Azure Blob Storage
# ---------------------------------------------------------------------------
- name: "[ 5/9 ] Criar Linked Service - Azure Blob Storage"
command: >
az datafactory linked-service create
--factory-name {{ adf_name }}
--resource-group {{ resource_group }}
--linked-service-name {{ adf_linked_blob_name }}
--properties '{
"type": "AzureBlobStorage",
"typeProperties": {
"connectionString": "{{ sa_conn_string.stdout | trim }}"
}
}'
register: ls_blob_result
changed_when: ls_blob_result.rc == 0
no_log: true
# ---------------------------------------------------------------------------
# BLOCO 6 - Datasets (origem S3 + destino Blob)
# ---------------------------------------------------------------------------
- name: "[ 6/9 ] Criar Dataset origem - S3 Binary"
command: >
az datafactory dataset create
--factory-name {{ adf_name }}
--resource-group {{ resource_group }}
--dataset-name {{ adf_dataset_s3_name }}
--properties '{
"type": "Binary",
"linkedServiceName": {
"referenceName": "{{ adf_linked_s3_name }}",
"type": "LinkedServiceReference"
},
"typeProperties": {
"location": {
"type": "AmazonS3Location",
"bucketName": "{{ s3_bucket_name }}",
"folderPath": "{{ s3_prefix }}"
}
}
}'
register: ds_s3_result
changed_when: ds_s3_result.rc == 0
- name: "[ 6/9 ] Criar Dataset destino - Blob Binary"
command: >
az datafactory dataset create
--factory-name {{ adf_name }}
--resource-group {{ resource_group }}
--dataset-name {{ adf_dataset_blob_name }}
--properties '{
"type": "Binary",
"linkedServiceName": {
"referenceName": "{{ adf_linked_blob_name }}",
"type": "LinkedServiceReference"
},
"typeProperties": {
"location": {
"type": "AzureBlobStorageLocation",
"container": "{{ container_name }}"
}
}
}'
register: ds_blob_result
changed_when: ds_blob_result.rc == 0
# ---------------------------------------------------------------------------
# BLOCO 7 - Pipeline de cópia S3 → Blob
# ---------------------------------------------------------------------------
- name: "[ 7/9 ] Criar Pipeline de migração {{ adf_pipeline_name }}"
command: >
az datafactory pipeline create
--factory-name {{ adf_name }}
--resource-group {{ resource_group }}
--name {{ adf_pipeline_name }}
--pipeline '{
"activities": [
{
"name": "CopyS3ToBlob",
"type": "Copy",
"inputs": [
{
"referenceName": "{{ adf_dataset_s3_name }}",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "{{ adf_dataset_blob_name }}",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "BinarySource",
"storeSettings": {
"type": "AmazonS3ReadSettings",
"recursive": true
}
},
"sink": {
"type": "BinarySink",
"storeSettings": {
"type": "AzureBlobStorageWriteSettings"
}
},
"parallelCopies": 4,
"dataIntegrationUnits": 4,
"enableStaging": false
}
}
]
}'
register: pipeline_result
changed_when: pipeline_result.rc == 0
# ---------------------------------------------------------------------------
# BLOCO 8 - Disparar execução da pipeline
# ---------------------------------------------------------------------------
- name: "[ 8/9 ] Executar pipeline de migração"
command: >
az datafactory pipeline create-run
--factory-name {{ adf_name }}
--resource-group {{ resource_group }}
--name {{ adf_pipeline_name }}
register: pipeline_run
changed_when: pipeline_run.rc == 0
- name: "[ 8/9 ] Capturar Run ID"
set_fact:
run_id: "{{ (pipeline_run.stdout | from_json).runId }}"
- name: "[ 8/9 ] Exibir Run ID"
debug:
msg: "Pipeline iniciada - Run ID: {{ run_id }}"
# ---------------------------------------------------------------------------
# BLOCO 9 - Aguardar conclusão e verificar status
# Polling a cada 30s, timeout de 120 tentativas (≈ 1h)
# ---------------------------------------------------------------------------
- name: "[ 9/9 ] Aguardar conclusão da pipeline (polling 30s)"
command: >
az datafactory pipeline-run show
--factory-name {{ adf_name }}
--resource-group {{ resource_group }}
--run-id {{ run_id }}
--query status
--output tsv
register: pipeline_status
until: pipeline_status.stdout.strip() in ['Succeeded', 'Failed', 'Cancelled']
retries: 120
delay: 30
changed_when: false
- name: "[ 9/9 ] Falhar se a pipeline não completou com sucesso"
fail:
msg: >
Pipeline terminou com status: {{ pipeline_status.stdout.strip() }}.
Acesse https://adf.azure.com para detalhes do erro.
when: pipeline_status.stdout.strip() != 'Succeeded'
- name: "[ 9/9 ] Exibir resultado final"
debug:
msg: |
============================================================
Migração concluída com sucesso!
Origem : s3://{{ s3_bucket_name }}/{{ s3_prefix }}
Destino : {{ storage_account_name }}/{{ container_name }}
Run ID : {{ run_id }}
ADF URL : https://adf.azure.com/en-us/home?factory=%2FresourceGroups%2F{{ resource_group }}%2Fproviders%2FMicrosoft.DataFactory%2Ffactories%2F{{ adf_name }}
============================================================
# ---------------------------------------------------------------------------
# PÓS-TASKS: limpeza opcional de recursos temporários
# ---------------------------------------------------------------------------
post_tasks:
- name: "[ CLEANUP ] Listar blobs migrados para validação"
command: >
az storage blob list
--container-name {{ container_name }}
--account-name {{ storage_account_name }}
--auth-mode login
--query "[].name"
--output table
register: blob_list
changed_when: false
when: log_level == "verbose"
- name: "[ CLEANUP ] Exibir blobs migrados"
debug:
msg: "{{ blob_list.stdout }}"
when: log_level == "verbose" and blob_list is defined