Redhat RH124

Red Hat System Administration I
O curso Red Hat System Administration I (RH124) foi desenvolvido para profissionais de TI sem experiência anterior em administração de sistemas Linux. O recurso tem como objetivo fornecer aos alunos “habilidades de sobrevivência” de administração do Linux, com foco em tarefas centrais de administração. O Red Hat System Administration I também oferece uma base para os alunos que planejam se tornar administradores de sistemas Linux em tempo integral, apresentando os principais conceitos de linha de comando e ferramentas de nível corporativo. Esses conceitos serão mais desenvolvidos no próximo curso, Red Hat System Administration II (RH134).
Fedora
Fedora é um projeto comunitário que produz e lança um sistema operacional completo, gratuito e baseado em Linux. A Red Hat patrocina a comunidade e trabalha com representantes da comunidade para integrar o mais recente software upstream a uma distribuição rápida e segura. O projeto Fedora contribui com tudo de volta para o mundo open source livre, e qualquer pessoa pode participar.
No entanto, o Fedora se concentra na inovação e na excelência, e não na estabilidade de longo prazo. Novas atualizações importantes acontecem a cada seis meses e podem trazer mudanças significativas. O Fedora é compatível somente com lançamentos por cerca de um ano (duas atualizações principais), o que o torna menos adequado para uso empresarial.
Red Hat Enterprise Linux
O Red Hat Enterprise Linux (RHEL) é a distribuição do Linux da Red Hat pronta para empresas e com suporte comercial. É a plataforma líder para computação open source, não apenas uma coleção de projetos open source maduros. O RHEL é extensivamente testado, tem um grande ecossistema de suporte de parceiros, certificações de hardware e software, serviços de consultoria, treinamento e suporte de vários anos e garantias de manutenção.
A Red Hat baseia suas principais versões do RHEL no Fedora. No entanto, em função disso, a Red Hat pode escolher quais pacotes incluir, fazer outras melhorias (contribuiu com os projetos de upstream e Fedora) e tomar decisões de configuração que atendam às necessidades dos clientes. A Red Hat ajuda os fornecedores e clientes a se envolverem com a comunidade de open source e a trabalhar com o desenvolvimento upstream para desenvolver soluções e corrigir problemas.
O Red Hat Enterprise Linux usa um modelo de distribuição baseado em subscrição. Como este é um software open source, esta não é uma taxa de licença. Em vez disso, ela paga o suporte, a manutenção, as atualizações, patches de segurança, acesso à base de conhecimento no Red Hat Customer Portal (http://access.redhat.com/), certificações e assim por diante. O cliente está pagando por suporte e expertise de longo prazo, comprometimento e assistência quando necessário.
Quando grandes atualizações são disponibilizadas, os clientes podem implementá-las quando for mais conveniente para eles e sem pagar mais. Isso simplifica o gerenciamento das atualizações de sistema nos aspectos econômico e prático.
CentOS
O CentOS é uma distribuição Linux orientada pela comunidade e derivada em grande parte da base de código open source da Red Hat Enterprise Linux e outras fontes. É gratuito, fácil de instalar e conta com equipe e suporte de uma comunidade ativa de voluntários que opera independentemente da Red Hat.
Introdução ao ambiente GNOME de área de trabalho
O ambiente de desktop é a interface gráfica do usuário em um sistema Linux. O ambiente de área de trabalho padrão no Red Hat Enterprise Linux 8 é fornecido pelo GNOME 3. Ele fornece aos usuários uma área de trabalho integrada, além de uma plataforma de desenvolvimento unificada fornecida pelo Wayland (por padrão) ou pelo X Window System legado.
O GNOME Shell oferece as principais funções de interface de usuário do ambiente GNOME de área de trabalho. O aplicativo GNOME Shell é altamente personalizável. O padrão do Red Hat Enterprise Linux 8 para a aparência do GNOME Shell é o tema “Padrão”, que é usado nesta seção. O padrão do Red Hat Enterprise Linux 7 era um tema alternativo chamado “Clássico”, que estava mais perto da aparência de versões mais antigas do GNOME. O tema pode ser selecionado de modo persistente no login, clicando o ícone de engrenagem ao lado do botão Sign In depois de selecionar a conta e antes de digitar a senha.
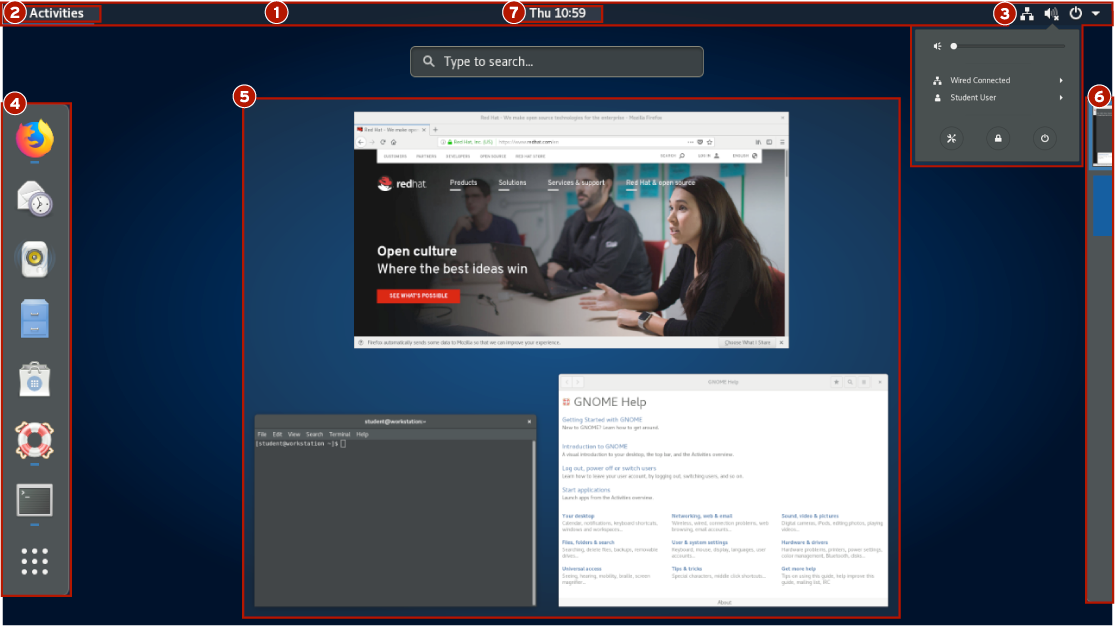
Partes do GNOME Shell
Os elementos do GNOME Shell incluem as seguintes partes, conforme ilustrado por esta captura de tela do GNOME Shell no modo de visão geral Activities:
-
Barra superior: a barra que fica no topo da tela. Ela é exibido na visão geral Activities e nos espaços de trabalho. A barra superior oferece o botão Activities, além dos controles de volume, rede, acesso ao calendário e a alternância entre os métodos de entrada de teclado (se mais de uma estiver configurada).
-
Activities overview: este é um modo especial que ajuda um usuário a organizar janelas e iniciar aplicativos. A visão geral Activities pode ser inserida clicando no botão Activities no canto superior esquerdo da barra superior ou pressionando a tecla Super. A tecla Super (às vezes chamada de tecla do Windows ou a tecla Command), fica perto do canto inferior esquerdo de um PC IBM de 104/105 teclas ou de um teclado Apple. As três áreas principais da visão geral Activities são o dash, à esquerda da tela, a windows overview, no centro da tela, e o workspace selector, no lado direito da tela.
-
System menu: o menu no canto superior direito na barra superior fornece controle para ajustar o brilho da tela e para ativar ou desativar as conexões de rede. Abaixo do submenu do nome de usuário estão as opções para ajustar das configurações de conta e fazer o logout do sistema ou desligar. O menu do sistema também oferece botões para abrir a janela Settings, bloquear a tela ou desligar o sistema.
-
Dash: é uma lista configurável de ícones dos aplicativos favoritos do usuário, dos aplicativos que estão em execução e um botão de grid na parte inferior do dash que pode ser usado para selecionar aplicativos arbitrários. Você pode iniciar os aplicativos clicando em um dos ícones ou usando a grade para encontrar um aplicativo menos usado. O dash também é, às vezes, chamado de dock.
-
Windows overview: uma área no centro da visão geral Activities, que exibe miniaturas de todas as janelas ativas na área de trabalho atual. Isso permite que as janelas sejam mais facilmente colocadas em primeiro plano em um espaço de trabalho desordenado ou movidas para outro espaço de trabalho.
-
Workspace selector: uma área à direita da visão geral Activities, que exibe miniaturas de todas as áreas de trabalho ativas e permite que as áreas de trabalho sejam selecionadas e as janelas sejam movidas de uma área de trabalho para outra.
-
Bandeja de mensagens: oferece uma maneira de acessar as notificações enviadas por aplicativos ou componentes do sistema ao GNOME. Se uma notificação ocorrer, normalmente, ela será exibida primeiro brevemente como uma única linha na parte superior da tela e um indicador persistente aparecerá no centro da barra superior ao lado do relógio para informar o usuário sobre as notificações que foram recebidas recentemente. Você pode abrir a bandeja de mensagens para analisar essas notificações clicando no relógio na barra superior ou pressionando Super+m. Você pode fechar a bandeja de mensagens clicando no relógio na barra superior ou pressionando Esc ou Super+M novamente.
Você pode visualizar e editar os atalhos de teclado do GNOME usados por sua conta. Abra o menu do sistema no lado direito da barra superior. Clique no botão Settings na parte inferior do menu à esquerda. Na janela do aplicativo que é aberta, selecione Devices → Keyborad no painel esquerdo. O painel direito exibirá suas configurações de atalho atuais.
Nota
Pode ser difícil enviar alguns atalhos de teclado, como as teclas de função ou a tecla Super, para uma máquina virtual. Isso ocorre porque as teclas especiais usadas por esses atalhos podem ser capturadas pelo sistema operacional local ou pelo aplicativo que você está usando para acessar a área de trabalho gráfica de sua máquina virtual.
Importante
Nos ambientes de treinamento virtual e individualizado atuais da Red Hat, usar a tecla Super pode ser um pouco complicado. Você provavelmente não poderá usar a tecla Super do teclado porque ela, muitas vezes, não é passada para a máquina virtual no ambiente de sala de aula pelo seu navegador da web.
Na parte superior da janela do navegador que exibe a interface da sua máquina virtual, deve haver um ícone de teclado no lado direito. Se você clicar nele, será aberto um teclado na tela. Clicando novamente, o teclado na tela será fechado.
O teclado na tela trata a Super como uma tecla modificadora que é frequentemente pressionada com outra tecla. Se você clicar nela uma vez, ela ficará amarela, indicando que está sendo pressionada. Então, para pressionar Super+M no teclado na tela, clique em Super e em M.
Se você desejar apenas pressionar e soltar Super no teclado na tela, deverá clicar duas vezes nela. O primeiro clique mantém a tecla Super pressionada, e o segundo clique a libera.
As outras teclas tratadas como teclas modificadoras (como a Super) pelo teclado na tela são Shift, Ctrl, Alt e Caps. As teclas Esc e Menu são tratadas como teclas normais e não como teclas modificadoras.
Espaços de trabalho
Os espaços de trabalho são telas separadas que têm janelas de aplicativo diferentes. Eles podem ser usados para organizar seu ambiente de trabalho agrupando janelas de aplicativo abertas por tarefas. Por exemplo, janelas usadas para executar uma determinada atividade de manutenção do sistema (como a configuração de um novo servidor remoto) podem ser agrupadas em um espaço de trabalho, enquanto e-mails e outros aplicativos de comunicação podem ser agrupados em outro espaço de trabalho.
Há dois métodos simples para alternar entre espaços de trabalho. um método, talvez o mais rápido, é pressionar Ctrl+Alt+seta para cima ou Ctrl+Alt+seta para baixo para alternar entre espaços de trabalho em sequência. O segundo é alternar para a visão geral Activities desejada e clicar no espaço de trabalho.
Uma vantagem de usar a visão geral Activities é que as janelas podem ser clicadas e arrastadas entre o espaço de trabalho usando o workspace selector à direita da tela, e a windows overview, no centro da tela.
Importante
Assim como a Super, nos ambientes atuais de treinamento virtual e individualizado da Red Hat, as combinações de teclas Ctrl+Alt não são geralmente passadas para a máquina virtual no ambiente de sala de aula pelo seu navegador da web.
Você pode inserir essas combinações de teclas para alternar espaços de trabalho usando o teclado na tela. Pelo menos dois espaços de trabalho precisam estar em uso. Abra o teclado na tela e clique em Ctrl, Alt e, em seguida, na seta para cima ou na seta para baixo.
No entanto, nesses ambientes de treinamento, geralmente é mais simples evitar os atalhos de teclado e o teclado na tela. Alterne espaços de trabalho clicando no botão Activities e, em seguida, no seletor de área de trabalho à direita da visão geral Activities, clicando no espaço de trabalho para o qual você deseja alternar.
Inicialização de um terminal
Para obter um prompt do shell no GNOME, inicie um aplicativo de terminal gráfico, como o GNOME Terminal. Há várias maneiras de fazer isso. Os dois métodos mais usados estão listados abaixo:
Na visão geral Activities, selecione Terminal no dash (na área dos favoritos, encontrando-o com o botão de grade (no agrupamento Utilities) ou usando o campo de pesquisa na parte superior da windows overview).
Pressione a combinação de teclas Alt+F2 para abrir Enter a Command e digite gnome-terminal.
Quando uma janela de terminal for aberta, um prompt do shell será exibido ao usuário que iniciou o programa de terminal gráfico. O prompt do shell e a barra de título da janela de terminal indicam o nome de usuário atual, o nome do host e o diretório de trabalho.
Bloqueio de tela ou logout
É possível bloquear a tela ou fazer o logout totalmente a partir do menu de sistema no lado direito da barra superior.
Para bloquear a tela, no menu do sistema no canto superior direito, clique no botão de bloqueio na parte inferior do menu ou pressione Super+L (que pode ser mais fácil de lembrar como Windows+L). A tela também é bloqueada se a sessão gráfica ficar inativa por alguns minutos.
Uma lock screen curtain (cortina de tela de bloqueio) aparece, mostrando a hora do sistema e o nome do usuário conectado. Para desbloquear a tela, pressione Enter ou espaço para levantar a cortina de bloqueio de tela; em seguida, insira a senha do usuário na tela de bloqueio.
Para fazer o logout e finalizar a sessão de login gráfico atual, selecione o menu do sistema no canto superior direito da barra superior e clique em (User) → Log Out. Uma janela é exibida, oferecendo a opção de Cancel ou confirmar a ação Log out.
Desligamento ou reinicialização do sistema
Para desligar o sistema, no menu do sistema no canto superior direito, clique no botão liga/desliga na parte inferior do menu ou pressione Ctrl+Alt+Del. Na caixa de diálogo exibida, você pode escolher Power Off (Desligar) ou Restart (Reiniciar) a máquina; ou Cancel (Cancelar) a operação. Se você não fizer uma escolha, o sistema será desligado automaticamente após 60 segundos.
Sintaxe básica de comandos
O GNU Bourne-Again Shell (bash) é um programa que interpreta comandos digitados pelo usuário. Cada string digitada no shell pode ter até três partes: o comando, as opções (que geralmente começam com - ou –) e os argumentos. Cada palavra digitada no shell é separada por espaços. Comandos são os nomes dos programas que estão instalados no sistema. Cada comando tem suas próprias opções e argumentos.
Quando estiver pronto para executar um comando, pressione a tecla Enter. Digite cada comando em uma linha separada. A saída do comando é exibida antes que o próximo prompt do shell seja exibido.
[user@host]$ whoami
user
[user@host]$
Se quiser digitar mais de um comando em uma única linha, use um ponto e vírgula (;) como separador de comandos. Um ponto e vírgula é um membro de uma classe de caracteres chamada metacaracteres que tem significados especiais para o bash. Nesse caso, a saída de ambos os comandos será exibida antes de o próximo prompt shell aparecer.
O exemplo a seguir mostra como combinar dois comandos (command1 e command2) na linha de comando.
[user@host]$ command1;command2
Exemplos de comandos simples
O comando date mostra a data e a hora atuais. Ele também pode ser usado pelo superusuário para ajustar o relógio do sistema. Um argumento que começa por um sinal de mais (+) define a string de formatação para o comando date.
[user@host ~]$ date
Sat Jan 26 08:13:50 IST 2019
[user@host ~]$ date +%R
08:13
[user@host ~]$ date +%x
01/26/2019
O comando passwd altera a senha do próprio usuário. A senha original da conta deverá ser indicada para que uma alteração seja permitida. Por padrão, passwd está configurado para solicitar uma senha segura, composta por letras minúsculas, maiúsculas, números e símbolos e que não seja baseada em uma palavra do dicionário. O superusuário pode usar o comando passwd para alterar as senhas de outros usuários.
[user@host ~]$ passwd
Changing password for user user.
Current password: old_password
New password: new_password
Retype new password: new_password
passwd: all authentication tokens updated successfully.
O Linux não exige extensões de nome de arquivo para classificar arquivos por tipo. O comando file varre o início do conteúdo de um arquivo e exibe seu tipo. Os arquivos a serem classificados serão passados como argumentos ao comando.
[user@host ~]$ file /etc/passwd
/etc/passwd: ASCII text
[user@host ~]$ file /bin/passwd
/bin/passwd: setuid ELF 64-bit LSB shared object, x86-64, version 1
(SYSV), dynamically linked, interpreter /lib64/ld-linux-x86-64.so.2,
for GNU/Linux 3.2.0, BuildID[sha1]=a3637110e27e9a48dced9f38b4ae43388d32d0e4, stripped
[user@host ~]$ file /home
/home: directory
Visualização do conteúdo dos arquivos
Um dos comandos mais simples e frequentemente usados no Linux é o cat. O comando cat permite criar múltiplos arquivos ou arquivos únicos, visualizar o conteúdo dos arquivos, concatenar o conteúdo de vários arquivos e redirecionar o conteúdo do arquivo a um terminal ou a arquivos.
O exemplo mostra como visualizar o conteúdo do arquivo /etc/passwd.
[user@host ~]$ cat /etc/passwd
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
...output omitted...
Use o comando a seguir para exibir o conteúdo de vários arquivos.
[user@host ~]$ cat file1 file2
Hello World!!
Introduction to Linux commands.
Alguns arquivos são muito longos e podem ocupar mais espaço para serem exibidos do que o fornecido pelo terminal. O comando cat não exibe o conteúdo de um arquivo como páginas. O comando less exibe uma página de um arquivo de cada vez e permite que você percorra as páginas.
O comando less permite que você avance e volte nas páginas por meio de arquivos mais compridos que cabem em uma janela de terminal. Use as teclas de seta para cima e seta para baixo para rolar para cima e para baixo. Pressione q para sair do comando.
Os comandos head e tail exibem o início e o fim de um arquivo, respectivamente. Por padrão, esses comandos exibem 10 linhas do arquivo, mas ambos têm uma opção -n que permite especificar um número diferente de linhas. O arquivo a ser exibido será passado como um argumento para esses comandos.
[user@host ~]$ head /etc/passwd
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
operator:x:11:0:operator:/root:/sbin/nologin
[user@host ~]$ tail -n 3 /etc/passwd
gdm:x:42:42::/var/lib/gdm:/sbin/nologin
gnome-initial-setup:x:977:977::/run/gnome-initial-setup/:/sbin/nologin
avahi:x:70:70:Avahi mDNS/DNS-SD Stack:/var/run/avahi-daemon:/sbin/nologin
O comando wc conta linhas, palavras e caracteres em um arquivo. É preciso de uma opção -l, -w ou -c para exibir apenas linhas, palavras ou caracteres, respectivamente.
[user@host ~]$ wc /etc/passwd
45 102 2480 /etc/passwd
[user@host ~]$ wc -l /etc/passwd ; wc -l /etc/group
45 /etc/passwd
70 /etc/group
[user@host ~]$ wc -c /etc/group /etc/hosts
966 /etc/group
516 /etc/hosts
1482 total
Preenchimento com Tab
O preenchimento com Tab permite que o usuário complete comandos ou nomes de arquivo rapidamente depois de digitar uma parte suficiente no prompt para torná-los exclusivos. Se os caracteres digitados não forem únicos, pressionar a tecla Tab duas vezes mostra todos os comandos iniciados pelos caracteres já digitados.
[user@host ~]$ pas1Tab+Tab
passwd paste pasuspender
[user@host ~]$ pass2Tab
[user@host ~]$ passwd
Changing password for user user.
Current password:
1 Pressione Tab duas vezes.
2 Pressione Tab uma vez.
O preenchimento com Tab pode ser usado para completar os nomes de arquivo ao digitá-los como argumentos de comandos. Quando a tecla Tab é pressionada, ela preenche o nome do arquivo, tanto quanto possível. Pressionar Tab uma segunda vez fará com que o shell liste todos os arquivos que correspondam ao padrão atual. Digite caracteres adicionais até o nome ser exclusivo e use o preenchimento com Tab para completar o comando.
[user@host ~]$ ls /etc/pas1Tab
[user@host ~]$ ls /etc/passwd2Tab
passwd passwd-
1 2 Pressione Tab uma vez.
É possível corresponder argumentos e opções usando o preenchimento com Tab para muitos comandos. O comando useradd é usado pelo superusuário, root, para criar usuários adicionais no sistema. Muitas opções podem ser usadas para controlar como esse comando se comporta. O preenchimento com Tab após uma opção parcial pode ser utilizado para concluir a opção sem precisar digitar muito.
[root@host ~]## useradd --1Tab+Tab
--base-dir --groups --no-log-init --shell
--comment --help --non-unique --skel
--create-home --home-dir --no-user-group --system
--defaults --inactive --password --uid
--expiredate --key --root --user-group
--gid --no-create-home --selinux-user
[root@host ~]## useradd --
1 Pressione Tab duas vezes.
Continuação de um longo comando em outra linha
Comandos com muitas opções e argumentos podem rapidamente se tornar longos e são automaticamente envolvidos pela janela de comando quando o cursor atinge a margem direita. Em vez disso, para facilitar a legibilidade do comando, você pode digitar um comando longo usando mais de uma linha.
Para fazer isso, você usará um caractere de barra invertida (), referido como o caractere escape, para ignorar o significado do caractere imediatamente após a barra invertida. Você aprendeu que inserir um caractere de nova linha, pressionando a tecla Enter, informa ao shell que a entrada do comando está completa e que o comando deve ser executado. Ao usar o escape para o caractere de nova linha, o shell é instruído a mudar para uma nova linha de comando sem o executar. O shell reconhece a solicitação exibindo um prompt de continuação, chamado de prompt secundário, usando o caractere maior do que (>) por padrão em uma nova linha vazia. Os comandos podem ser continuados em muitas linhas.
[user@host]$ head -n 3 \
> /usr/share/dict/words \
> /usr/share/dict/linux.words
==> /usr/share/dict/words <==
1080
10-point
10th
==> /usr/share/dict/linux.words <==
1080
10-point
10th
[user@host ~]$
Importante
O exemplo de tela anterior mostra como um comando continuado aparece para um usuário típico. No entanto, promover esse realismo em materiais didáticos, como este livro, geralmente causa confusão. Os novos alunos podem inserir por engano o caractere maior do que adicional como parte do comando digitado. O shell interpreta um caractere maior do que digitado como redirecionamento de processo, o que não era o objetivo do usuário. O redirecionamento de processos é discutido em um próximo capítulo.
Para evitar essa confusão, este livro não mostrará prompts secundários nas saídas da tela. Um usuário ainda verá o prompt secundário em sua janela do shell, mas o material do curso exibe intencionalmente apenas caracteres para serem digitados, conforme demonstrado no exemplo abaixo. Compare com o exemplo de tela anterior.
[user@host]$ head -n 3 \
/usr/share/dict/words \
/usr/share/dict/linux.words
==> /usr/share/dict/words <==
1080
10-point
10th
==> /usr/share/dict/linux.words <==
1080
10-point
10th
[user@host ~]$
Histórico de comandos
O comando history exibe uma lista de comandos executados anteriormente precedidos por um número.
O caractere ponto de exclamação (!) é um metacaractere usado para expandir comandos anteriores sem precisar redigitá-los. O comando !number expande o comando que corresponde ao número indicado. O comando !string expande o comando mais recente que começa com a string especificada.
[user@host ~]$ history
...output omitted...
23 clear
24 who
25 pwd
26 ls /etc
27 uptime
28 ls -l
29 date
30 history
[user@host ~]$ !ls
ls -l
total 0
drwxr-xr-x. 2 user user 6 Mar 29 21:16 Desktop
...output omitted...
[user@host ~]$ !26
ls /etc
abrt hosts pulse
adjtime hosts.allow purple
aliases hosts.deny qemu-ga
...output omitted...
As teclas de seta podem ser usadas para navegar pelos comandos anteriores no histórico do shell. A seta para cima edita o comando anterior na lista do histórico. A seta para baixo edita o próximo comando na lista do histórico. A seta para a esquerda e a seta para a direita movem o cursor para a esquerda e para a direita no comando atual da lista de histórico, para que você possa editá-lo antes de executá-lo.
Você pode usar a combinação de teclas Esc+. ou Alt+. para inserir a última palavra do comando anterior na localização atual do cursor. O uso repetido da combinação de teclas substituirá esse texto pela última palavra dos comandos anteriores do histórico. A combinação de teclas Alt+. é particularmente conveniente porque você pode segurar Alt e pressionar . repetidamente para percorrer facilmente pelos comandos anteriores.
Edição da linha de comando
Quando usado de forma interativa, bash tem um recurso de edição de linha de comando. Isso permite que o usuário utilize os comandos do editor de texto para se mover e modificar o comando atual sendo digitado. O movimento no comando atual e a passagem pelo histórico de comandos usando as teclas de seta foram introduzidos anteriormente nesta sessão. Comandos de edição mais poderosos são apresentados na tabela a seguir.
Atalho = Descrição
Ctrl+A => Ir para o início da linha de comando.
Ctrl+E => Ir para o final da linha de comando.
Ctrl+U => Limpar do cursor ao início da linha de comando.
Ctrl+K => Limpar do cursor até o final da linha de comando.
Ctrl+seta => para a esquerda Ir para o início da palavra anterior na linha de comando.
Ctrl+seta => para a direita Ir para o final da próxima palavra na linha de comando.
Ctrl+R => Pesquisar um padrão na lista de histórico de comandos.
Há vários outros comandos de edição de linha de comando disponíveis, mas esses são os comandos mais úteis para novos usuários. Os outros comandos podem ser encontrados na página do man bash
- Use o comando date para exibir a data e a hora atuais
[student@workstation ~]$ date
Thu Jan 22 10:13:04 PDT 2019
- Mostrar a hora atual no formato de 12 horas (por exemplo, 11:42:11 AM). Dica: a string de formato que exibe a saída é %r.
[student@workstation ~]$ date +%r
10:14:07 AM
- Qual tipo de arquivo é /home/student/zcat? Ele é legível?
➜ ~ file /usr/bin/zcat
/usr/bin/zcat: POSIX shell script, ASCII text executable
- Use o comando wc e os atalhos do Bash para exibir o tamanho de zcat.
➜ ~ wc /usr/bin/zcat
51 299 1984 /usr/bin/zcat
- Exiba as 10 primeiras linhas de zcat.
➜ ~ head h10 /usr/bin/zcat
head: não foi possível abrir 'h10' para leitura: Arquivo ou diretório inexistente
==> /usr/bin/zcat <==
#!/bin/sh
# Uncompress files to standard output.
# Copyright (C) 2007, 2010-2018 Free Software Foundation, Inc.
# This program is free software; you can redistribute it and/or modify
# it under the terms of the GNU General Public License as published by
# the Free Software Foundation; either version 3 of the License, or
# (at your option) any later version.
- Exiba as 10 últimas linhas do arquivo zcat.
➜ ~ tail -n 10 /usr/bin/zcat
With no FILE, or when FILE is -, read standard input.
Report bugs to <bug-gzip@gnu.org>."
case $1 in
--help) printf '%s\n' "$usage" || exit 1; exit;;
--version) printf '%s\n' "$version" || exit 1; exit;;
esac
exec gzip -cd "$@"
- Repita o comando anterior exato pressionando as teclas três vezes ou menos.
Repita o comando anterior exato. Pressione a tecla de seta para cima uma vez para voltar no histórico do comando e pressione Enter (duas vezes), ou digite o comando de atalho !! e, depois, pressione Enter (três vezes) para executar o comando mais recente no histórico de comandos. (Tente usar ambos.)
[student@workstation]$ !!
tail zcat
With no FILE, or when FILE is -, read standard input.
Report bugs to <bug-gzip@gnu.org>."
case $1 in
--help) printf '%s\n' "$usage" || exit 1;;
--version) printf '%s\n' "$version" || exit 1;;
esac
exec gzip -cd "$@"
- Repita o comando anterior, mas use a opção -n 20 para exibir as últimas 20 linhas no arquivo. Use a edição de linha de comando para fazer isso com o mínimo de pressionamento de teclas.
➜ ~ tail -n 20 /usr/bin/zcat
-l, --list list compressed file contents
-q, --quiet suppress all warnings
-r, --recursive operate recursively on directories
-S, --suffix=SUF use suffix SUF on compressed files
--synchronous synchronous output (safer if system crashes, but slower)
-t, --test test compressed file integrity
-v, --verbose verbose mode
--help display this help and exit
--version display version information and exit
With no FILE, or when FILE is -, read standard input.
Report bugs to <bug-gzip@gnu.org>."
case $1 in
--help) printf '%s\n' "$usage" || exit 1; exit;;
--version) printf '%s\n' "$version" || exit 1; exit;;
esac
exec gzip -cd "$@"
- Use o histórico do shell para executar o comando date +%r novamente.
[student@workstation ~]$ history
1 date
2 date +%r
3 file zcat
4 wc zcat
5 head zcat
6 tail zcat
7 tail -n 20 zcat
8 history
[student@workstation ~]$ !2
date +%r
10:49:56 AM
=> O shell Bash é um interpretador de comandos que solicita aos usuários interativos que especifiquem os comandos do Linux.
=> Muitos comandos têm uma opção –help que exibe uma tela ou mensagem de uso.
=> A utilização de espaços de trabalho facilita a organização de várias janelas de aplicativos.
=> O botão Activities no canto superior esquerdo da barra superior fornece um modo de visão geral que ajuda o usuário a organizar janelas e iniciar aplicativos.
=> O comando file varre o início do conteúdo de um arquivo e exibe seu tipo.
=> Os comandos head e tail exibem o início e o fim de um arquivo, respectivamente.
=> Você pode usar o preenchimento Tab para preencher nomes de arquivos ao digitá-los como argumentos para os comandos.
https://rha.ole.redhat.com/rha/app/courses/rh124-8.2/pages/ch03
Capítulo 3. Gerenciamento de arquivos na linha de comando
A hierarquia do sistema de arquivos
Todos os arquivos em um sistema Linux são armazenados em sistemas de arquivos, que são organizados em uma única árvore de diretório invertida, conhecida como hierarquia do sistema de arquivos. Essa árvore é invertida porque dizemos que a raiz dela está na parte superior da hierarquia e os ramos de diretórios e subdiretórios se estendem abaixo da raiz (root).
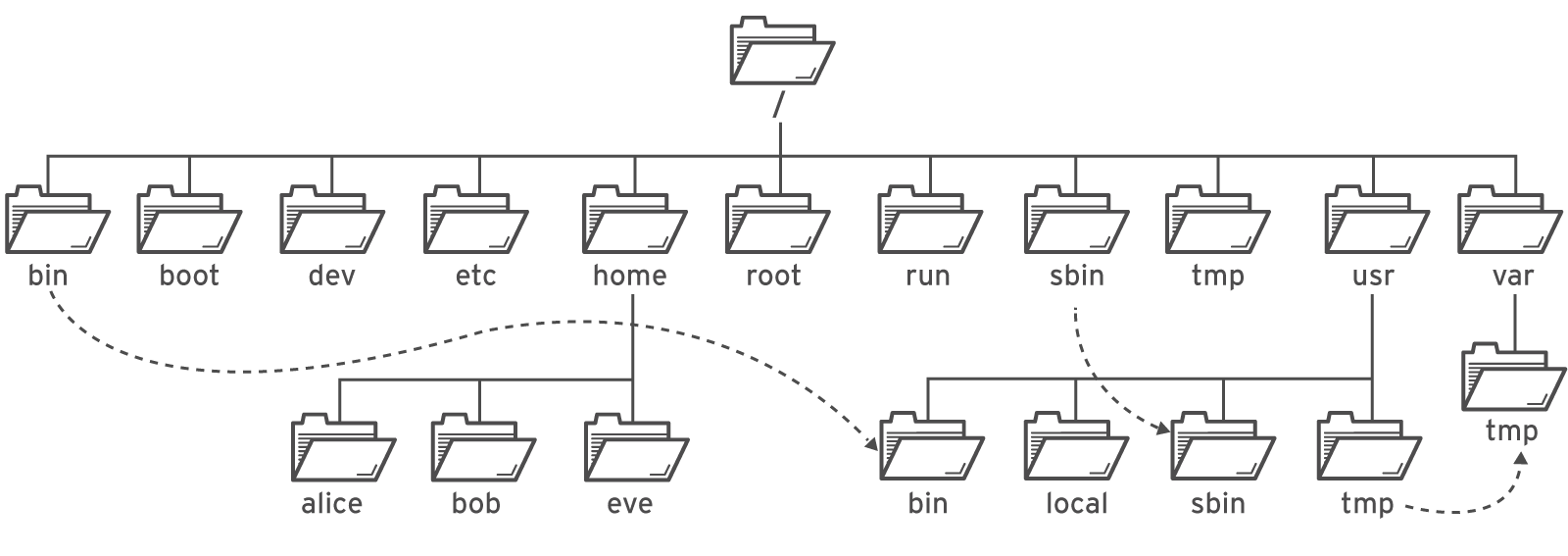
O diretório / é o diretório root no topo da hierarquia do sistema de arquivos. O caractere / também é usado como separador de diretórios nos nomes de arquivos. Por exemplo, se etc for um subdiretório do diretório /, é possível chamá-lo de /etc. Do mesmo modo, se o diretório /etc contiver um arquivo chamado issue, é possível referir-se ao arquivo como /etc/issue.
Os subdiretórios de / são usados com fins padronizados para organizar arquivos por tipo e finalidade. Assim, fica mais fácil encontrar arquivos. Por exemplo, no diretório root, o subdiretório /boot é utilizado para armazenar os arquivos necessários para o boot do sistema.
Nota
Os seguintes termos ajudam a descrever o conteúdo do diretório do sistema de arquivos:
=> O conteúdo estático permanece inalterado até que seja editado ou reconfigurado.
=> O conteúdo dinâmico ou variável pode ser modificado ou inserido pelos processos ativos.
=> O conteúdo persistente permanece após uma reinicialização, como definições de configuração.
=> O conteúdo de tempo de execução é específico de processos ou sistemas e é excluído por uma reinicialização.
Diretórios importantes do Red Hat Enterprise Linux
/usr
Software instalado, bibliotecas compartilhadas, arquivos incluídos e dados de programas somente leitura. Subdiretórios importantes incluem:
/usr/bin: comandos de usuário.
/usr/sbin: comandos de administração do sistema.
/usr/local: software personalizado localmente.
/etc
Arquivos de configuração específicos deste sistema.
/var
Dados variáveis específicos deste sistema que devem persistir entre boots do sistema. Os arquivos que mudam de modo dinâmico; por exemplo, bancos de dados, diretórios de cache, arquivos de log, documentos com spool de impressora e conteúdo de sites podem ser encontrados em /var.
/run
Dados de tempo de execução de processos iniciados desde o último boot. Isso inclui arquivos de ID de processos e arquivos de bloqueio, entre outros. O conteúdo desse diretório é recriado na reinicialização. Este diretório consolida /var/run e /var/lock de versões anteriores do Red Hat Enterprise Linux.
/home
Diretórios pessoais são os locais onde os usuários normais armazenam seus dados pessoais e arquivos de configuração.
/root
Diretório pessoal do superusuário administrativo, root.
/tmp
Um espaço gravável para arquivos temporários. Arquivos não acessados, alterados nem modificados por 10 dias são excluídos automaticamente desse diretório. Há outro diretório temporário, /var/tmp, no qual os arquivos que não tiverem sido acessados, alterados ou modificados por mais de 30 dias serão excluídos automaticamente.
/boot
Arquivos necessários para começar o processo de boot.
/dev
Contém arquivos de dispositivos especiais que são usados pelo sistema para acessar o hardware.
Importante
No Red Hat Enterprise Linux 7 e posteriores, quatro diretórios mais antigos em / têm o mesmo conteúdo de suas contrapartes localizadas em /usr:
/bin e /usr/bin
/sbin e /usr/sbin
/lib e /usr/lib
/lib64 e /usr/lib64
Em versões anteriores do Red Hat Enterprise Linux, esses diretórios eram diferentes e continham conjuntos distintos de arquivos.
No Red Hat Enterprise Linux 7 e posteriores, os diretórios em / são links simbólicos para as pastas correspondentes em /usr.
Especificação de arquivos por nome
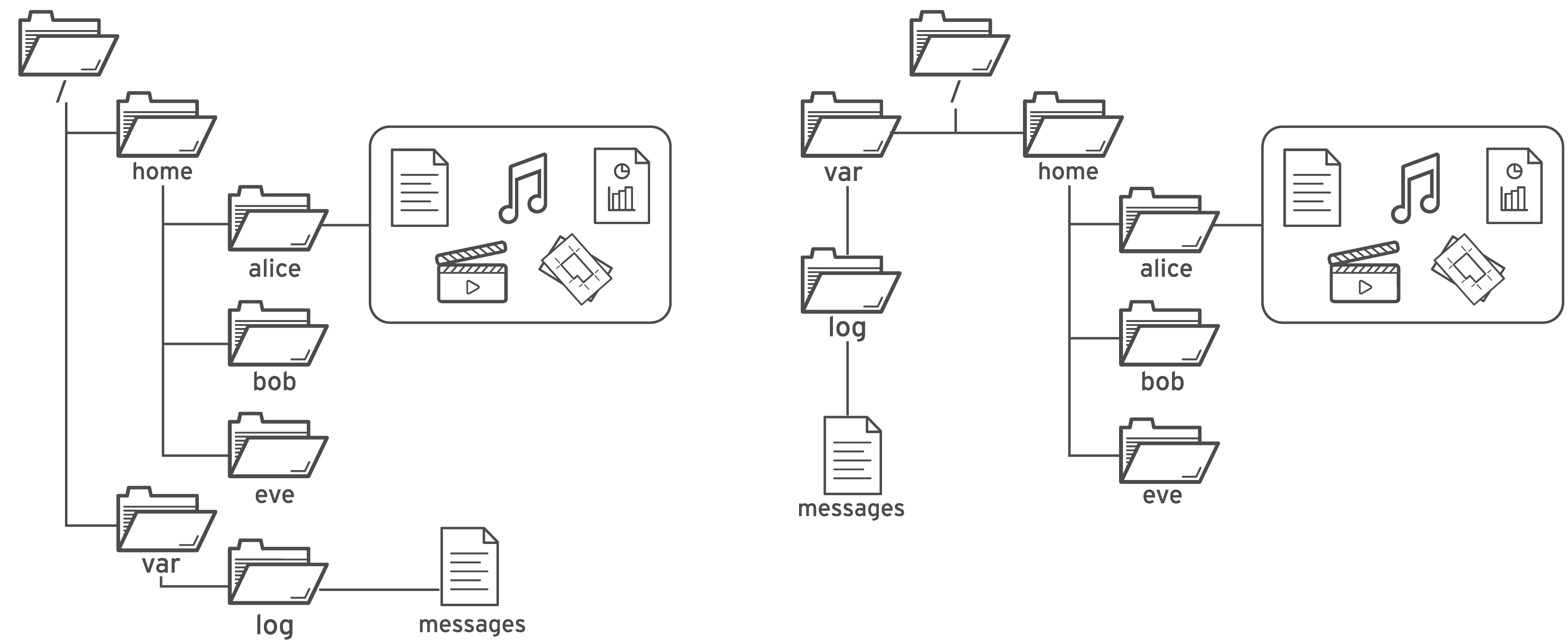
A visualização do navegador de arquivos comum (à esquerda) é equivalente à visualização descendente (à direita).
O caminho de um arquivo ou diretório especifica o local exclusivo no sistema de arquivos. Seguir o caminho de um arquivo atravessa um ou mais subdiretórios nomeados, delimitados por uma barra (/), até chegar ao destino. Os diretórios, também chamados de pastas, contêm outros arquivos e outros subdiretórios. Eles podem ser referenciados da mesma maneira que os arquivos.
Importante
Um caractere de espaço é aceitável como parte de um nome de arquivo do Linux. No entanto, espaços também são usados pelo shell para separar opções e argumentos na linha de comando. Se você inserir um comando que inclua um arquivo que tenha um espaço no nome, o shell poderá interpretar erroneamente o comando e entender que você deseja iniciar um novo nome de arquivo ou outro argumento no espaço.
É possível evitar isso colocando nomes de arquivos entre aspas. No entanto, se você não precisar usar espaços em nomes de arquivos, pode ser mais simples simplesmente evitá-los.
=> Caminhos absolutos
Um caminho absoluto é um nome totalmente qualificado, especificando a localização exata dos arquivos na hierarquia do sistema de arquivos. Ele começa no diretório raiz (/) e especifica cada subdiretório que deve ser percorrido para alcançar o arquivo específico. Cada arquivo em um sistema de arquivos tem um nome de caminho absoluto exclusivo, reconhecido por uma regra simples: um nome de arquivo com uma barra (/) como primeiro caractere é um nome de caminho absoluto. Por exemplo, o nome de caminho absoluto do arquivo de log do sistema de mensagens é /var/log/messages. Nomes de caminhos absolutos podem ser longos, por isso, os arquivos também podem ser localizados em relação ao diretório de trabalho atual para o prompt do shell.
=> O diretório de trabalho atual e caminhos relativos
Quando um usuário fizer login e abrir uma janela de comando, normalmente a localização inicial será o diretório pessoal do usuário. Os processos do sistema também têm um diretório inicial. Usuários e processos navegam a outros diretórios, conforme necessário; os termos diretório de trabalho ou diretório de trabalho atual são referentes ao local atual.
Assim como um caminho absoluto, um caminho relativo identifica um único arquivo, especificando somente o caminho necessário para acessar o arquivo no diretório de trabalho local. O reconhecimento de nomes de caminho relativos segue uma regra simples: um nome de caminho com qualquer caractere diferente de uma barra como primeiro caractere é um nome de caminho relativo. Um usuário no diretório /var pode fazer referência ao arquivo de log de mensagens de modo relativo como log/messages.
Sistemas de arquivos Linux, incluindo, entre outros, ext4, XFS, GFS2 e GlusterFS, diferenciam maiúsculas de minúsculas. A criação de FileCase.txt e filecase.txt no mesmo diretório resulta em dois arquivos exclusivos.
Sistemas de arquivos que não são do Linux podem funcionar de modo diferente. Por exemplo, o VFAT, o NTFS da Microsoft e o HFS+ da Apple, têm um comportamento de preservação de maiúsculas e minúsculas. Embora esses sistemas de arquivos não diferenciem maiúsculas de minúsculas, eles exibem os nomes de arquivo com as letras originais usada durante a criação do arquivo. Portanto, se você tentou criar os arquivos no exemplo anterior em um sistema de arquivos VFAT, ambos os nomes seriam tratados como apontando para o mesmo arquivo em vez de dois arquivos diferentes.
Caminhos de navegação
O comando pwd exibe o nome do caminho completo do diretório de trabalho atual para esse shell. Isso pode ajudar você a determinar a sintaxe para acessar arquivos usando nomes de caminho relativos. O comando ls lista o conteúdo do diretório especificado ou, caso um diretório não seja fornecido, do diretório de trabalho atual.
[user@host ~]$ pwd
/home/user
[user@host ~]$ ls
Desktop Documents Downloads Music Pictures Public Templates Videos
[user@host ~]$
Use o comando cd para alterar o diretório de trabalho atual do shell. Se você não especificar nenhum argumento para o comando, ele será alterado para o diretório pessoal.
No exemplo a seguir, uma mistura de caminhos absolutos e relativos é usada com o comando cd para alterar o diretório de trabalho atual para o shell.
[user@host ~]$ pwd
/home/user
[user@host ~]$ cd Videos
[user@host Videos]$ pwd
/home/user/Videos
[user@host Videos]$ cd /home/user/Documents
[user@host Documents]$ pwd
/home/user/Documents
[user@host Documents]$ cd
[user@host ~]$ pwd
/home/user
[user@host ~]$
Como você pode ver no exemplo anterior, o prompt de shell padrão também exibe o último componente do caminho absoluto para o diretório de trabalho atual.
Por exemplo, para /home/user/Videos, somente Videos é exibido. O prompt exibe o caractere til ‘~’ quando o diretório de trabalho atual é o diretório pessoa.
O comando touch normalmente atualiza o carimbo de data e hora de um arquivo para a data e a hora atuais, sem modificá-lo. Isso é útil para a criação de arquivos vazios, que podem ser usados para prática, pois o uso desse comando em um nome de arquivo que não existe faz com que o arquivo seja criado. No exemplo a seguir, o comando touch cria arquivos de prática nos subdiretórios Documents e Videos.
[user@host ~]$ touch Videos/blockbuster1.ogg
[user@host ~]$ touch Videos/blockbuster2.ogg
[user@host ~]$ touch Documents/thesis_chapter1.odf
[user@host ~]$ touch Documents/thesis_chapter2.odf
[user@host ~]$
O comando ls tem várias opções para a exibição de atributos nos arquivos. As mais comuns e úteis são -l (formato de listagem longa), -a (todos os arquivos, incluindo os ocultos) e -R (recursão, para incluir o conteúdo de todos os subdiretórios).
[user@host ~]$ ls -l
total 15
drwxr-xr-x. 2 user user 4096 Feb 7 14:02 Desktop
drwxr-xr-x. 2 user user 4096 Jan 9 15:00 Documents
drwxr-xr-x. 3 user user 4096 Jan 9 15:00 Downloads
drwxr-xr-x. 2 user user 4096 Jan 9 15:00 Music
drwxr-xr-x. 2 user user 4096 Jan 9 15:00 Pictures
drwxr-xr-x. 2 user user 4096 Jan 9 15:00 Public
drwxr-xr-x. 2 user user 4096 Jan 9 15:00 Templates
drwxr-xr-x. 2 user user 4096 Jan 9 15:00 Videos
[user@host ~]$ ls -la
total 15
drwx------. 16 user user 4096 Feb 8 16:15 .
drwxr-xr-x. 6 root root 4096 Feb 8 16:13 ..
-rw-------. 1 user user 22664 Feb 8 00:37 .bash_history
-rw-r--r--. 1 user user 18 Jul 9 2013 .bash_logout
-rw-r--r--. 1 user user 176 Jul 9 2013 .bash_profile
-rw-r--r--. 1 user user 124 Jul 9 2013 .bashrc
drwxr-xr-x. 4 user user 4096 Jan 20 14:02 .cache
drwxr-xr-x. 8 user user 4096 Feb 5 11:45 .config
drwxr-xr-x. 2 user user 4096 Feb 7 14:02 Desktop
drwxr-xr-x. 2 user user 4096 Jan 9 15:00 Documents
drwxr-xr-x. 3 user user 4096 Jan 25 20:48 Downloads
drwxr-xr-x. 11 user user 4096 Feb 6 13:07 .gnome2
drwx------. 2 user user 4096 Jan 20 14:02 .gnome2_private
-rw-------. 1 user user 15190 Feb 8 09:49 .ICEauthority
drwxr-xr-x. 3 user user 4096 Jan 9 15:00 .local
drwxr-xr-x. 2 user user 4096 Jan 9 15:00 Music
drwxr-xr-x. 2 user user 4096 Jan 9 15:00 Pictures
drwxr-xr-x. 2 user user 4096 Jan 9 15:00 Public
drwxr-xr-x. 2 user user 4096 Jan 9 15:00 Templates
drwxr-xr-x. 2 user user 4096 Jan 9 15:00 Videos
[user@host ~]$
Os dois diretórios especiais no topo da lista se referem ao diretório atual (.) e ao diretório pai (..). Esses diretórios especiais existem em todos os diretórios do sistema. Você descobrirá a utilidade deles quando começar a usar comandos de gerenciamento de arquivos.
Importante
Nomes de arquivos começando com um ponto (.) indicam arquivos ocultos; não é possível visualizá-los na exibição normal usando ls e outros comando. Esse não é um recurso de segurança. Os arquivos ocultos impedem que os arquivos de configuração do usuário necessários sobrecarreguem diretórios pessoais. Muitos comandos processam arquivos ocultos apenas com opções de linha de comando especificas, evitando que a configuração de um usuário seja acidentalmente copiada para outros diretórios ou usuários.
Proteger o conteúdo dos arquivos de visualizações inadequadas exige o uso de permissões de arquivo.
[user@host ~]$ ls -R
.:
Desktop Documents Downloads Music Pictures Public Templates Videos
./Desktop:
./Documents:
thesis_chapter1.odf thesis_chapter2.odf
./Downloads:
./Music:
./Pictures:
./Public:
./Templates:
./Videos:
blockbuster1.ogg blockbuster2.ogg
[user@host ~]$
O comando cd tem várias opções. Algumas são tão úteis que é importante praticá-las o mais cedo possível e usá-las com frequência. O comando cd - passa para o diretório anterior, no qual o usuário estava antes do diretório atual. O exemplo a seguir ilustra esse comportamento, alternando entre dois diretórios, o que é útil ao processar uma série de tarefas semelhantes.
[user@host ~]$ cd Videos
[user@host Videos]$ pwd
/home/user/Videos
[user@host Videos]$ cd /home/user/Documents
[user@host Documents]$ pwd
/home/user/Documents
[user@host Documents]$ cd -
[user@host Videos]$ pwd
/home/user/Videos
[user@host Videos]$ cd -
[user@host Documents]$ pwd
/home/user/Documents
[user@host Documents]$ cd -
[user@host Videos]$ pwd
/home/user/Videos
[user@host Videos]$ cd
[user@host ~]$
O comando cd .. usa o diretório oculto .. para subir um nível até o diretório pai sem precisar saber o nome exato desse diretório. O outro diretório oculto (.) especifica o diretório atual nos comandos em que a localização atual é o argumento de origem ou de destino, evitando a necessidade de digitar o nome de caminho absoluto do diretório.
[user@host Videos]$ pwd
/home/user/Videos
[user@host Videos]$ cd .
[user@host Videos]$ pwd
/home/user/Videos
[user@host Videos]$ cd ..
[user@host ~]$ pwd
/home/user
[user@host ~]$ cd ..
[user@host home]$ pwd
/home
[user@host home]$ cd ..
[user@host /]$ pwd
/
[user@host /]$ cd
[user@host ~]$ pwd
/home/user
[user@host ~]$
Gerenciamento de arquivos usando ferramentas de linha de comando
Para gerenciar arquivos, você precisa ser capaz de criar, remover, copiar e mover os arquivos. Você também precisa organizá-los logicamente em diretórios, os quais você também precisa ser capaz de criar, remover, copiar e mover.
A tabela a seguir resume alguns dos comandos mais comuns de gerenciamento de arquivos. O restante desta seção discutirá maneiras de usar esses comandos em mais detalhes.
Atividade => Sintaxe do comando Criar um novo diretório => mkdir directory Copiar um arquivo => cp file new-file Copiar um diretório e seu conteúdo => cp -r directory new-directory Mover ou renomear um arquivo ou diretório => mv file new-file Remover um arquivo => rm file Remover um diretório contendo arquivos => rm -r directory Remover um diretório vazio => rmdir directory
Criação de diretórios
O comando mkdir cria um ou mais diretórios ou subdiretórios. Ele considera como argumentos uma lista de caminhos para os diretórios que você deseja criar.
O comando mkdir falhará com um erro se o diretório já existir ou se você estiver tentando criar um subdiretório em um diretório que não existe. A opção -p (pai) cria diretórios pais ausentes para o destino solicitado. Tenha cautela ao usar o comando mkdir -p pois erros de digitação acidentais podem criar diretórios não pretendidos sem gerar mensagens de erro.
No exemplo a seguir, digamos que você está tentando criar um diretório no Videosdiretório nomeadoWatched, mas acidentalmente deixou a letra “s” em Videos no comando mkdir.
[user@host ~]$ mkdir Video/Watched
mkdir: cannot create directory `Video/Watched': No such file or directory
O comando mkdir falhou porque Videos foi digitado incorretamente e o diretório Video não existe. Se você tivesse usado o comando mkdir com a opção -p, o diretório Video seria criado, o que não era o pretendido, e o subdiretório Watched seria criado nesse diretório incorreto.
Depois de escrever corretamente o diretório pai Videos, a criação do subdiretório Watched será bem-sucedida.
[user@host ~]$ mkdir Videos/Watched
[user@host ~]$ ls -R Videos
Videos/:
blockbuster1.ogg blockbuster2.ogg Watched
Videos/Watched:
No exemplo a seguir, os arquivos e diretórios são organizados abaixo do diretório /home/user/Documents. Use o comando mkdir e uma lista de nomes de diretórios separada por espaços para criar vários diretórios.
[user@host ~]$ cd Documents
[user@host Documents]$ mkdir ProjectX ProjectY
[user@host Documents]$ ls
ProjectX ProjectY
Use o comando mkdir -p e caminhos relativos separados por espaços para cada um dos nomes de subdiretórios para criar vários diretórios pai com subdiretórios.
[user@host Documents]$ mkdir -p Thesis/Chapter1 Thesis/Chapter2 Thesis/Chapter3
[user@host Documents]$ cd
[user@host ~]$ ls -R Videos Documents
Documents:
ProjectX ProjectY Thesis
Documents/ProjectX:
Documents/ProjectY:
Documents/Thesis:
Chapter1 Chapter2 Chapter3
Documents/Thesis/Chapter1:
Documents/Thesis/Chapter2:
Documents/Thesis/Chapter3:
Videos:
blockbuster1.ogg blockbuster2.ogg Watched
Videos/Watched:
O último comando mkdir criou subdiretórios de três subdiretórios ChapterN com um comando. A opção -p criou o diretório pai Thesis ausente.
Cópia de arquivos
O comando cp copia um arquivo, criando um novo arquivo no diretório atual ou em um diretório especificado. Ele também pode copiar vários arquivos para um diretório.
Atenção
Se o arquivo de destino já existir, o comando cp substitui o arquivo.
[user@host ~]$ cd Videos
[user@host Videos]$ cp blockbuster1.ogg blockbuster3.ogg
[user@host Videos]$ ls -l
total 0
-rw-rw-r--. 1 user user 0 Feb 8 16:23 blockbuster1.ogg
-rw-rw-r--. 1 user user 0 Feb 8 16:24 blockbuster2.ogg
-rw-rw-r--. 1 user user 0 Feb 8 16:34 blockbuster3.ogg
drwxrwxr-x. 2 user user 4096 Feb 8 16:05 Watched
[user@host Videos]
Ao copiar vários arquivos com um comando, o último argumento deverá ser um diretório. Os arquivos copiados mantêm seus nomes originais no novo diretório. Se um arquivo com o mesmo nome existir no diretório de destino, o arquivo existente será substituído. Por padrão, o cp não copia diretórios, mas os ignora.
No exemplo a seguir, dois diretórios são listados, Thesis e ProjectX. Apenas o último argumento, ProjectX, é válido como destino. O diretório Thesis é ignorado.
[user@host Videos]$ cd ../Documents
[user@host Documents]$ cp thesis_chapter1.odf thesis_chapter2.odf Thesis ProjectX
cp: omitting directory `Thesis'
[user@host Documents]$ ls Thesis ProjectX
ProjectX:
thesis_chapter1.odf thesis_chapter2.odf
Thesis:
Chapter1 Chapter2 Chapter3
No primeiro comando cp, a cópia do diretório Thesis falhou, mas os arquivos thesis_chapter1.odf e thesis_chapter2.odf foram copiados com êxito.
Se você desejar copiar um arquivo para o diretório de trabalho atual, poderá usar o diretório .:
[user@host ~]$ cp /etc/hostname .
[user@host ~]$ cat hostname
host.example.com
[user@host ~]$
Use o comando copy com a opção -r (recursiva) para copiar o diretório Thesis e seu conteúdo para o diretório ProjectX.
[user@host Documents]$ cp -r Thesis ProjectX
[user@host Documents]$ ls -R ProjectX
ProjectX:
Thesis thesis_chapter1.odf thesis_chapter2.odf
ProjectX/Thesis:
Chapter1 Chapter2 Chapter3
ProjectX/Thesis/Chapter1:
ProjectX/Thesis/Chapter2:
thesis_chapter2.odf
ProjectX/Thesis/Chapter3:
Movimentação de arquivos
O comando mv move arquivos de um local para outro. Se você pensar no caminho absoluto para um arquivo como seu nome completo, mover um arquivo será efetivamente o mesmo que renomear um arquivo. O conteúdo do arquivo permanecerá inalterado.
Use o comando mv para renomear um arquivo.
[user@host Videos]$ cd ../Documents
[user@host Documents]$ ls -l thesis*
-rw-rw-r--. 1 user user 0 Feb 6 21:16 thesis_chapter1.odf
-rw-rw-r--. 1 user user 0 Feb 6 21:16 thesis_chapter2.odf
[user@host Documents]$ mv thesis_chapter2.odf thesis_chapter2_reviewed.odf
[user@host Documents]$ ls -l thesis*
-rw-rw-r--. 1 user user 0 Feb 6 21:16 thesis_chapter1.odf
-rw-rw-r--. 1 user user 0 Feb 6 21:16 thesis_chapter2_reviewed.odf
Use o comando mv para mover um arquivo para outro diretório.
[user@host Documents]$ ls Thesis/Chapter1
[user@host Documents]$
[user@host Documents]$ mv thesis_chapter1.odf Thesis/Chapter1
[user@host Documents]$ ls Thesis/Chapter1
thesis_chapter1.odf
[user@host Documents]$ ls -l thesis*
-rw-rw-r--. 1 user user 0 Feb 6 21:16 thesis_chapter2_reviewed.odf
Remoção de arquivos e diretórios
O comando rm remove arquivos. Por padrão, rm não removerá diretórios que contenham arquivos, a menos que você adicione as opções -r ou –recursive.
Importante
Não existe um recurso de cancelamento de exclusão na linha de comando ou uma Lixeira da qual restaurar arquivos programados para exclusão.
É uma boa ideia verificar seu diretório de trabalho atual antes de remover um arquivo ou diretório.
[user@host Documents]$ pwd
/home/student/Documents
Use o comando rm para remover um único arquivo do seu diretório de trabalho.
[user@host Documents]$ ls -l thesis*
-rw-rw-r--. 1 user user 0 Feb 6 21:16 thesis_chapter2_reviewed.odf
[user@host Documents]$ rm thesis_chapter2_reviewed.odf
[user@host Documents]$ ls -l thesis*
ls: cannot access 'thesis*': No such file or directory
Se você tentar usar o comando rm para remover um diretório sem usar a opção -r, o comando falhará.
[user@host Documents]$ rm Thesis/Chapter1
rm: cannot remove `Thesis/Chapter1': Is a directory
Use o comando rm -r para remover um subdiretório e seu conteúdo.
[user@host Documents]$ ls -R Thesis
Thesis/:
Chapter1 Chapter2 Chapter3
Thesis/Chapter1:
thesis_chapter1.odf
Thesis/Chapter2:
thesis_chapter2.odf
Thesis/Chapter3:
[user@host Documents]$ rm -r Thesis/Chapter1
[user@host Documents]$ ls -l Thesis
total 8
drwxrwxr-x. 2 user user 4096 Feb 11 12:47 Chapter2
drwxrwxr-x. 2 user user 4096 Feb 11 12:48 Chapter3
O comando rm -r percorre cada subdiretório primeiro, removendo individualmente seus arquivos antes de remover cada diretório. Você pode usar o comando rm -ri para solicitar interativamente a confirmação antes da exclusão. Isso é essencialmente o oposto de usar a opção -f, que força a remoção sem solicitar a confirmação do usuário.
[user@host Documents]$ rm -ri Thesis
rm: descend into directory `Thesis'? y
rm: descend into directory `Thesis/Chapter2'? y
rm: remove regular empty file `Thesis/Chapter2/thesis_chapter2.odf'? y
rm: remove directory `Thesis/Chapter2'? y
rm: remove directory `Thesis/Chapter3'? y
rm: remove directory `Thesis'? y
[user@host Documents]$
Atenção
Se você especificar as opções -i e -f, a opção -f tem prioridade e você não será solicitado para confirmação antes que rm exclua arquivos.
No exemplo a seguir, o comando rmdir remove apenas o diretório que está vazio. Assim como no exemplo anterior, você deve usar o comando rm -r para remover um diretório que contenha conteúdo.
[user@host Documents]$ pwd
/home/student/Documents
[user@host Documents]$ rmdir ProjectY
[user@host Documents]$ rmdir ProjectX
rmdir: failed to remove `ProjectX': Directory not empty
[user@host Documents]$ rm -r ProjectX
[user@host Documents]$ ls -lR
.:
total 0
[user@host Documents]$
O comando rm sem opções não pode remover um diretório vazio. Você deve usar os comandos rmdir, rm -d (que é equivalente a rmdir) ou rm -r.
Criação de links entre arquivos
É possível criar vários nomes que apontam para o mesmo arquivo. Existem duas maneiras de fazer isso: criando um link físico para o arquivo ou criando um link simbólico (às vezes chamado de ligação simbólica) para o arquivo. Cada um tem suas vantagens e desvantagens.
Criação de links físicos
Todo arquivo inicia com um único link físico, desde seu nome inicial até os dados no sistema de arquivos. Quando você cria um novo link físico para um arquivo, cria outro nome que aponta para os mesmos dados. O novo link físico age exatamente como o nome do arquivo original. Uma vez criado, você não verá diferença entre o novo link físico e o nome original do arquivo.
Você pode descobrir se um arquivo tem vários links físicos com o comando ls -l. Uma das coisas que ele relata é a contagem de links de cada arquivo, o número de links físicos que o arquivo possui.
[user@host ~]$ pwd
/home/user
[user@host ~]$ ls -l newfile.txt
-rw-r--r--. 1 user user 0 Mar 11 19:19 newfile.txt
No exemplo anterior, a contagem de links de newfile.txt é 1. Ele tem exatamente um caminho absoluto, que é /home/user/newfile.txt .
Você pode usar o comando ln para criar um novo link físico (outro nome) que aponte para um arquivo existente. O comando precisa de pelo menos dois argumentos, um caminho para o arquivo existente e o caminho para o link físico que você deseja criar.
O exemplo a seguir cria um link físico chamado newfile-link2.txt para o arquivo existente newfile.txt no diretório /tmp.
[user@host ~]$ ln newfile.txt /tmp/newfile-hlink2.txt
[user@host ~]$ ls -l newfile.txt /tmp/newfile-hlink2.txt
-rw-rw-r--. 2 user user 12 Mar 11 19:19 newfile.txt
-rw-rw-r--. 2 user user 12 Mar 11 19:19 /tmp/newfile-hlink2.txt
Se você desejar descobrir se dois arquivos são links físicos um do outro, uma maneira é usar a opção -i com o comando ls para listar o número de inode dos arquivos. Se os arquivos estiverem no mesmo sistema de arquivos (discutido a seguir) e seus números de inode forem os mesmos, os arquivos são links físicos apontando para os mesmos dados.
[user@host ~]$ ls -il newfile.txt /tmp/newfile-hlink2.txt
8924107 -rw-rw-r--. 2 user user 12 Mar 11 19:19 newfile.txt
8924107 -rw-rw-r--. 2 user user 12 Mar 11 19:19 /tmp/newfile-hlink2.txt
Importante
Todos os links físicos que fazem referência ao mesmo arquivo terão as mesmas permissões, contagem de links, propriedade de usuário e grupo, carimbos de data e hora e conteúdo de arquivo. Se uma dessas informações for alterada em um link físico, todos os outros links físicos que apontem para o mesmo arquivo também exibirão a nova informação. Isso ocorre porque cada link físico aponta para os mesmos dados no dispositivo de armazenamento.
Mesmo que o arquivo original seja excluído, o conteúdo do arquivo ainda estará disponível, desde que pelo menos um link físico exista. Os dados só são excluídos do armazenamento quando o último link físico é excluído.
[user@host ~]$ rm -f newfile.txt
[user@host ~]$ ls -l /tmp/newfile-hlink2.txt
-rw-rw-r--. 1 user user 12 Mar 11 19:19 /tmp/newfile-hlink2.txt
[user@host ~]$ cat /tmp/newfile-hlink2.txt
Hello World
Limitações de links físicos
Os links físicos têm algumas limitações. Em primeiro lugar, os links físicos só podem ser usados com arquivos regulares. Você não pode usar ln para criar um link físico para um diretório ou arquivo especial.
Em segundo lugar, os links físicos só podem ser usados se ambos os arquivos estiverem no mesmo sistema de arquivos. A hierarquia do sistema de arquivos pode ser composta de vários dispositivos de armazenamento. Dependendo da configuração do sistema, quando você mudar para um novo diretório, esse diretório e seu conteúdo poderão ser armazenados em um sistema de arquivos diferente.
Você pode usar o comando df para listar os diretórios que estão em sistemas de arquivos diferentes. Por exemplo, você pode ver a saída desta maneira:
[user@host ~]$ df
Filesystem 1K-blocks Used Available Use% Mounted on
devtmpfs 886788 0 886788 0% /dev
tmpfs 902108 0 902108 0% /dev/shm
tmpfs 902108 8696 893412 1% /run
tmpfs 902108 0 902108 0% /sys/fs/cgroup
/dev/mapper/rhel_rhel8--root 10258432 1630460 8627972 16% /
/dev/sda1 1038336 167128 871208 17% /boot
tmpfs 180420 0 180420 0% /run/user/1000
[user@host ~]$
Arquivos em dois diretórios “montados em” diferentes e seus subdiretórios estão em sistemas de arquivos diferentes. (A correspondência mais específica vence.) Assim, no sistema deste exemplo, você pode criar um link físico entre /var/tmp/link1 e /home/user/file porque ambos são subdiretórios de / mas não de qualquer outro diretório na lista. No entanto, você não pode criar um link físico entre /boot/test/badlink e /home/user/file porque o primeiro arquivo está em um subdiretório de /boot (na lista “montado em”) e o segundo arquivo não.
Criação de softlinks
O comando ln -s cria um softlink, também chamado de “link simbólico”. Um link simbólico não é um arquivo normal, mas um tipo especial de arquivo que aponta para outro arquivo ou diretório existente.
Os links simbólicos têm algumas vantagens sobre links físicos:
=> Eles podem vincular dois arquivos em diferentes sistemas de arquivos.
=> Eles podem apontar para um diretório ou arquivo especial, não apenas um arquivo comum.
No exemplo a seguir, o comando ln -s é usado para criar um novo link flexível para o arquivo existente /home/user/newfile-link2.txt que será nomeado /tmp/newfile-symlink.txt.
[user@host ~]$ ln -s /home/user/newfile-link2.txt /tmp/newfile-symlink.txt
[user@host ~]$ ls -l newfile-link2.txt /tmp/newfile-symlink.txt
-rw-rw-r--. 1 user user 12 Mar 11 19:19 newfile-link2.txt
lrwxrwxrwx. 1 user user 11 Mar 11 20:59 /tmp/newfile-symlink.txt -> /home/user/newfile-link2.txt
[user@host ~]$ cat /tmp/newfile-symlink.txt
Soft Hello World
No exemplo anterior, o primeiro caractere da listagem longa para /tmp/newfile-symlink.txt é l, em vez de -. Isso indica que o arquivo é um link simbólico e não um arquivo normal. (Um d indicaria que o arquivo é um diretório.)
Quando o arquivo regular original é excluído, o link simbólico continua apontando para o arquivo, mas o destino some. Um link simbólico que esteja apontando para um arquivo ausente é denominado “link simbólico pendente”.
[user@host ~]$ rm -f newfile-link2.txt
[user@host ~]$ ls -l /tmp/newfile-symlink.txt
lrwxrwxrwx. 1 user user 11 Mar 11 20:59 /tmp/newfile-symlink.txt -> /home/user/newfile-link2.txt
[user@host ~]$ cat /tmp/newfile-symlink.txt
cat: /tmp/newfile-symlink.txt: No such file or directory
Importante
Um efeito colateral do link simbólico pendente no exemplo anterior é que, se você criar posteriormente um novo arquivo com o mesmo nome do arquivo excluído (/home/user/newfile-link2.txt), o link não estará mais “pendurado” e apontará para o novo arquivo.
Os links físicos não funcionam assim. Se você excluir um link físico e, em seguida, usar ferramentas normais ( ao invés de ln) para criar um novo arquivo com o mesmo nome, o novo arquivo não será vinculado ao arquivo antigo.
Uma maneira de comparar links físicos e links simbólicos que pode ajudar você a entender como eles funcionam:
=> Um link físico aponta um nome para dados em um dispositivo de armazenamento
=> Um link simbólico aponta um nome para outro nome, que aponta para dados em um dispositivo de armazenamento
Um link simbólico pode apontar para um diretório. Nesse caso, o link simbólico atuará como um diretório. Alterar para o link simbólico com cd fará com que o diretório de trabalho atual seja o diretório vinculado. Algumas ferramentas podem acompanhar o fato de você ter seguido um link simbólico para chegar lá. Por exemplo, por padrão cd atualizará seu diretório de trabalho atual usando o nome do link simbólico, em vez do nome do diretório real. (Existe uma opção, -P, que o atualizará com o nome do diretório real.)
No exemplo a seguir, um link simbólico denominado /home/user/configfiles é criado que aponta para o diretório /etc.
[user@host ~]$ ln -s /etc /home/user/configfiles
[user@host ~]$ cd /home/user/configfiles
[user@host configfiles]$ pwd
/home/user/configfiles
Correspondência de nomes de arquivos com expansões de shell
O shell Bash apresenta várias maneiras de expandir uma linha de comando, incluindo a correspondência de padrões, a expansão de diretório pessoal, a expansão de string e a substituição de variável. Talvez a mais poderosa delas seja a capacidade de correspondência de nome de caminhos, historicamente chamada de globbing. O recurso de globbing do Bash, por vezes chamado de “wildcards”, facilita o gerenciamento de grandes números de arquivos. Ao usar metacaracteres que se “expandem” para corresponder a nomes de caminho e de arquivo que são procurados, os comandos são executados em um conjunto específico de arquivos de uma só vez.
Correspondência de padrões
Globbing é uma operação de análise de comandos do shell que expande um padrão de caracteres curinga em uma lista de nomes de caminho correspondentes. Metacaracteres de linha de comando são substituídos pela lista de correspondência antes da execução do comando. Os padrões que não retornam correspondências exibem a solicitação de padrão original como texto literal. Os itens a seguir são metacaracteres e classes de padrões comuns.
Tabela 3.3. Tabela de metacaracteres e correspondências
* => Qualquer string com zero ou mais caracteres.
? => Qualquer caractere único.
[abc...] => Qualquer caractere na classe entre colchetes.
[!abc...] => Qualquer caractere que não esteja na classe entre colchetes.
[^abc...] => Qualquer caractere que não esteja na classe entre colchetes.
[[:alpha:]] => Qualquer caractere alfabético.
[[:lower:]] => Qualquer caractere em minúsculas.
[[:upper:]] => Qualquer caractere em maiúsculas.
[[:alnum:]] => Qualquer caractere alfabético ou numérico.
[[:punct:]] => Qualquer caractere imprimível que não seja alfanumérico nem um espaço.
[[:digit:]] => Qualquer dígito único de 0 a 9.
[[:space:]] => Qualquer caractere de espaço único. Isso pode incluir recuos, novas linhas, retornos, avanços de página ou espaços.
Para os próximos exemplos, digamos que você executou os comandos a seguir para criar alguns arquivos de amostra.
[user@host ~]$ mkdir glob; cd glob
[user@host glob]$ touch alfa bravo charlie delta echo able baker cast dog easy
[user@host glob]$ ls
able alfa baker bravo cast charlie delta dog easy echo
[user@host glob]$
O primeiro exemplo usará combinações de padrão simples com os caracteres asterisco * e ponto de interrogação ‘?’ e uma classe de caracteres para corresponder a alguns desses nomes de arquivo.
Expansão de til
O caractere til ‘~’ corresponde ao diretório pessoal do usuário atual. Se uma string diferente de uma barra ‘/’ for iniciada, o shell interpretará a string até essa barra como um nome de usuário, se houver uma correspondência, e substituirá a cadeia pelo caminho absoluto para o diretório pessoal desse usuário. Se nenhum nome de usuário for correspondente, um til real seguido da string será usado.
No exemplo a seguir, o comando echo é usado para exibir o valor do caractere til. O comando echo também pode ser usado para exibir os valores de chaves e caracteres de expansão de variáveis, entre outros.
[user@host glob]$ echo ~root
/root
[user@host glob]$ echo ~user
/home/user
[user@host glob]$ echo ~/glob
/home/user/glob
[user@host glob]$
Expansão de chave
A expansão de chave é usada para gerar strings de caracteres distintas. As chaves contêm uma lista de strings separadas por vírgula ou uma expressão de sequência. O resultado inclui o texto anterior ou o posterior à definição de chave. As expansões de chave podem ser aninhadas uma dentro da outra. Além disso, a sintaxe de dois pontos (..) é expandida para uma sequência tal que {m..p} será expandido para m n o p.
[user@host glob]$ echo {Sunday,Monday,Tuesday,Wednesday}.log
Sunday.log Monday.log Tuesday.log Wednesday.log
[user@host glob]$ echo file{1..3}.txt
file1.txt file2.txt file3.txt
[user@host glob]$ echo file{a..c}.txt
filea.txt fileb.txt filec.txt
[user@host glob]$ echo file{a,b}{1,2}.txt
filea1.txt filea2.txt fileb1.txt fileb2.txt
[user@host glob]$ echo file{a{1,2},b,c}.txt
filea1.txt filea2.txt fileb.txt filec.txt
[user@host glob]$
Um uso prático da expansão de chaves é criar rapidamente vários arquivos ou diretórios.
[user@host glob]$ mkdir ../RHEL{6,7,8}
[user@host glob]$ ls ../RHEL*
RHEL6 RHEL7 RHEL8
[user@host glob]$
Expansão variável
Uma variável age como um contêiner nomeado que pode armazenar um valor na memória. As variáveis facilitam o acesso e modificam os dados armazenados a partir da linha de comando ou dentro de um script de shell.
Você pode atribuir dados como um valor a uma variável usando a seguinte sintaxe:
[user@host ~]$ VARIABLENAME=value
Você pode usar a expansão variável para converter o nome da variável para o valor na linha de comando. Se uma string começar com um cifrão ($), o shell tentará usar o restante dessa cadeia como um nome de variável e o substituirá por qualquer valor que a variável tenha.
[user@host ~]$ USERNAME=operator
[user@host ~]$ echo $USERNAME
operator
Para ajudar a evitar erros devido a outras expansões de shell, você pode colocar o nome da variável entre chaves, por exemplo ${VARIABLENAME} .
[user@host ~]$ USERNAME=operator
[user@host ~]$ echo ${USERNAME}
operator
As variáveis do shell e as formas de usá-las serão abordadas com mais profundidade posteriormente neste curso.
Substituição de comandos
A substituição de comandos permite que a saída de um comando substitua o próprio comando. A substituição de comandos ocorre quando um comando é colocado entre parênteses e precedido por um cifrão ($). A forma $(command) pode aninhar várias expansões de comandos, uma dentro da outra.
[user@host glob]$ echo Today is $(date +%A).
Today is Wednesday.
[user@host glob]$ echo The time is $(date +%M) minutes past $(date +%l%p).
The time is 26 minutes past 11AM.
[user@host glob]$
Proteção de argumentos da expansão
Vários caracteres têm significado especial no shell Bash. Para evitar que o shell execute expansões de shell em partes de sua linha de comando, você pode usar aspas e escapes em caracteres e strings.
A barra invertida () é um caractere de escape no shell Bash. Ela protegerá contra expansão o caractere que vem imediatamente depois.
[user@host glob]$ echo The value of $HOME is your home directory.
The value of /home/user is your home directory.
[user@host glob]$ echo The value of \$HOME is your home directory.
The value of $HOME is your home directory.
[user@host glob]$
No exemplo anterior, proteger o cifrão de expansão fez com que o Bash o tratasse como um caractere regular e não executou a expansão de variável em $HOME .
Para proteger strings mais longas, aspas simples (’) ou duplas (") são usadas para delimitar strings. Elas têm efeitos ligeiramente diferentes. As aspas simples param toda a expansão do shell. As aspas duplas param a maior parte da expansão do shell.
Use aspas duplas para suprimir globbing e a expansão do shell, mas ainda permitir substituição de comandos e de variáveis.
[user@host glob]$ myhost=$(hostname -s); echo $myhost
host
[user@host glob]$ echo "***** hostname is ${myhost} *****"
***** hostname is host *****
[user@host glob]$
Use aspas simples para interpretar todo o texto literalmente.
[user@host glob]$ echo "Will variable $myhost evaluate to $(hostname -s)?"
Will variable host evaluate to host?
[user@host glob]$ echo 'Will variable $myhost evaluate to $(hostname -s)?'
Will variable $myhost evaluate to $(hostname -s)?
[user@host glob]$
Neste capítulo, você aprendeu que:
Os arquivos em um sistema Linux são organizados em uma única árvore de diretório invertida, conhecida como hierarquia do sistema de arquivos.
Os caminhos absolutos começam com um / e especificam a localização de um arquivo na hierarquia do sistema de arquivos.
Os caminhos relativos não começam com um / e especificam a localização de um arquivo em relação ao diretório de trabalho atual.
Cinco comandos principais são usados para gerenciar arquivos: mkdir , rmdir , cp , mv e rm .
Os links físicos e os links simbólicos são maneiras diferentes de ter vários nomes de arquivos apontando para os mesmos dados.
O shell Bash fornece recursos de correspondência, expansão e substituição de padrões para ajudar você a executar comandos de maneira eficiente.
Capítulo 4. Ajuda no Red Hat Enterprise Linux
Introdução ao comando man
Uma fonte de documentação geralmente disponível no sistema local são páginas do manual do sistema ou páginas do man. Essas páginas são enviadas como parte dos pacotes de software para os quais fornecem documentação e podem ser acessadas na linha de comando usando o comando man.
O histórico Manual do Programador Linux, do qual as páginas do man se originam, era tão grande que consistia em vários volumes impressos. Cada seção contém informações sobre um determinado tópico.
-
Comandos de usuário (tanto executáveis quanto programas shell)
-
Chamadas de sistema (rotinas do kernel invocadas a partir do espaço do usuário)
-
Funções de biblioteca (fornecidas pelas bibliotecas dos programas)
-
Arquivos especiais (como arquivos de dispositivos)
-
Formatos de arquivo (para muitos arquivos de configuração e estruturas)
-
Jogos (seção histórica para programas de lazer)
-
Convenções, padrões e páginas diversas (protocolos, sistemas de arquivos)
-
Administração do sistema e comandos com privilégios (tarefas de manutenção)
-
API do kernel Linux (chamadas de kernel internas)
Para distinguir nomes de tópicos idênticos em diferentes seções, as referências da página do man incluem o número da seção entre parênteses após o tópico. Por exemplo, passwd(1) descreve o comando para alterar senhas, enquanto passwd(5) explica o formato de arquivo /etc/passwd para armazenar contas de usuário locais.
Para ler páginas específicas do man, use man topic. O conteúdo é exibido em uma tela de cada vez. O comando man pesquisa seções do manual em ordem alfanumérica. Por exemplo, man passwd exibe passwd(1) por padrão. Para exibir o tópico da página de manual de uma seção específica, inclua o argumento número de seção: man 5 passwd exibe passwd(5).
Navegar e pesquisar em páginas de manual
A capacidade de fazer pesquisas eficientes por tópicos e de navegar pelas páginas do man é uma habilidade essencial de administração. As ferramentas da GUI facilitam a configuração de recursos comuns do sistema, mas usar a interface de linha de comando ainda é mais eficiente. Para navegar efetivamente pela linha de comando, você deve ser capaz de encontrar as informações necessárias nas páginas de manual.
A seguinte tabela lista comandos básicos de navegação ao visualizar páginas do man:
Navegação em páginas do man
Barra de espaço
Avançar uma tela (para baixo)
PageDown
Avançar uma tela (para baixo)
##PageUp Recuar uma tela (para cima)
##Seta para baixo Avançar uma linha (para baixo)
Seta para cima
Recuar uma linha (para cima)
D
Avançar meia tela (para baixo)
U
Recuar meia tela (para cima)
##/string Procurar string avançando (para baixo) na página do man
N
Repetir a pesquisa anterior avançando (para baixo) na página do man
Shift+N
Repetir a pesquisa anterior recuando (para cima) na página do man
G
Acesse o início da página do man.
Shift+G
Acesse o final da página do man.
Q
Sair do man e retornar ao prompt de comando do shell
Importante
Durante a realização de pesquisas, string permite sintaxe com expressões regulares. Enquanto o texto simples (como passwd) funciona como esperado, as expressões regulares usam metacaracteres (como $, , . e ^) para uma busca de padrões mais sofisticada. Portanto, pesquisas com strings que incluem metacaracteres de expressões do programa, como make $$$, poderão obter resultados inesperados.
Leitura de páginas de manual
Cada tópico é dividido em várias partes. A maioria dos tópicos compartilha os mesmos cabeçalhos e é apresentada na mesma ordem. Normalmente, um tópico não apresenta todos os cabeçalhos, porque nem todos os cabeçalhos se aplicam a todos os tópicos.
Pesquisa por páginas do man usando palavras-chave
Uma pesquisa por páginas de manual usando palavras-chave é realizada com man -k keyword, que exibe uma lista de tópicos de páginas de manual correspondentes às palavras-chave seguidos de números de seção.
[student@desktopX ~]$ man -k passwd
checkPasswdAccess (3) - query the SELinux policy database in the kernel.
chpasswd (8) - update passwords in batch mode
ckpasswd (8) - nnrpd password authenticator
fgetpwent_r (3) - get passwd file entry reentrantly
getpwent_r (3) - get passwd file entry reentrantly
...
passwd (1) - update user's authentication tokens
sslpasswd (1ssl) - compute password hashes
passwd (5) - password file
passwd.nntp (5) - Passwords for connecting to remote NNTP servers
passwd2des (3) - RFS password encryption
...
Os tópicos de administração de sistema populares encontram-se nas seções 1 (comandos de usuário), 5 (formatos de arquivos) e 8 (comandos administrativos). Os administradores usando determinadas ferramentas de solução de problemas também usam a seção 2 (chamadas do sistema). As seções restantes são geralmente usadas como referência para programadores ou na administração avançada.
Nota
As pesquisas usando palavras-chave se baseiam em um índice gerado pelo comando mandb(8), que deve ser executado como root. O comando é executado diariamente por cron.daily ou por anacrontab em até uma hora após a inicialização do sistema se ele estiver desatualizado.
Importante
O comando man -K (maiúscula) executa uma pesquisa de texto completo nas páginas, não apenas de títulos e descrições, como a opção -k. Uma pesquisa de texto completo usa mais recursos do sistema e leva mais tempo.
Capítulo 5. Criação, visualização e edição de arquivos de texto
Entrada padrão, saída padrão e erro padrão
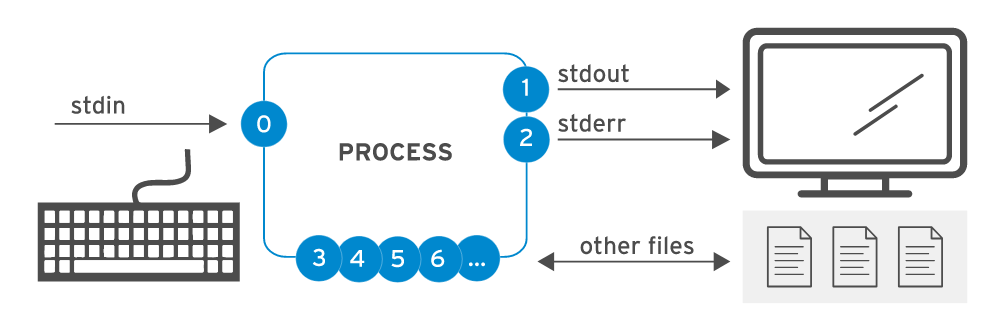
Um programa, ou um processo, em execução precisa ler a entrada de algum lugar e gravar a saída em algum lugar. Um comando executado no prompt do shell normalmente lê a entrada no teclado e envia a saída para a janela de terminal.
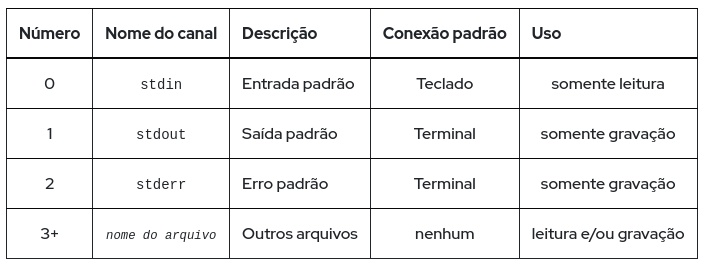
Um processo usa vários canais chamados descritores de arquivos para obter a entrada e enviar a saída. Todos os processos começam com pelo menos três descritores de arquivos. A entrada padrão (canal 0) lê a entrada do teclado. A saída padrão (canal 1) envia a saída normal para o terminal. O erro padrão (canal 2) envia mensagens de erro para o terminal. Se um programa abrir conexões separadas para outros arquivos, ele poderá usar descritores de arquivo de numeração mais alta.
Redirecionamento da saída para um arquivo
O redirecionamento E/S muda como o processo obtém sua entrada ou saída. Em vez de obter entrada do teclado ou enviar saída e erros para o terminal, o processo lê ou grava em arquivos. O redirecionamento permite salvar mensagens em um arquivo que normalmente é enviado para a janela de terminal. Como alternativa, você pode usar o redirecionamento para descartar a saída ou os erros, para que eles não sejam exibidos no terminal nem salvos.
Redirecionar stdout impede que a saída do processo apareça no terminal. Conforme mostrado na tabela a seguir, redirecionar somente stdout não exclui a exibição de mensagens de erro stderr no terminal. Se o arquivo não existir, ele será criado. Se o arquivo existir e o redirecionamento não for o anexado ao arquivo, o conteúdo do arquivo será substituído.
Se você desejar descartar mensagens, o arquivo especial /dev/null descarta saída de canal redirecionada a ele e é sempre um arquivo vazio.
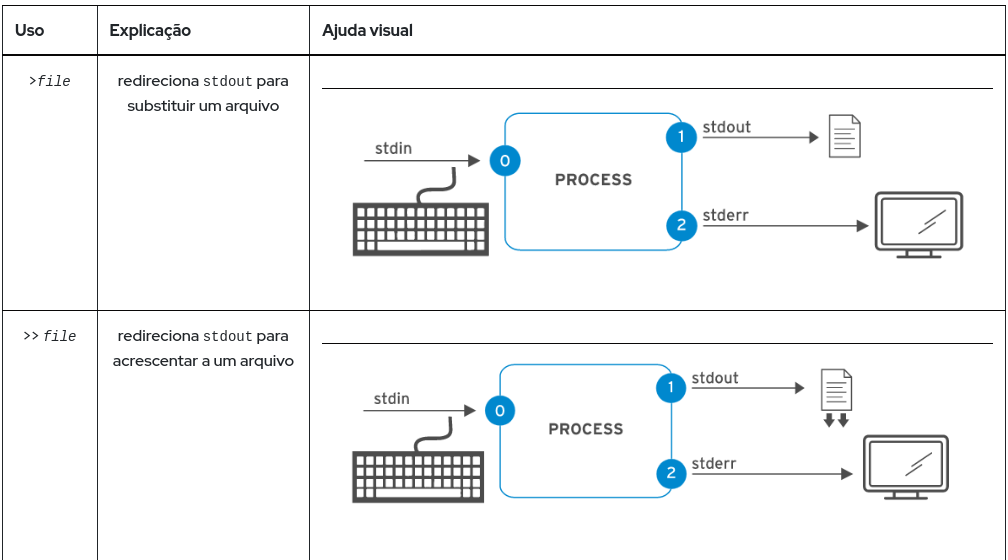
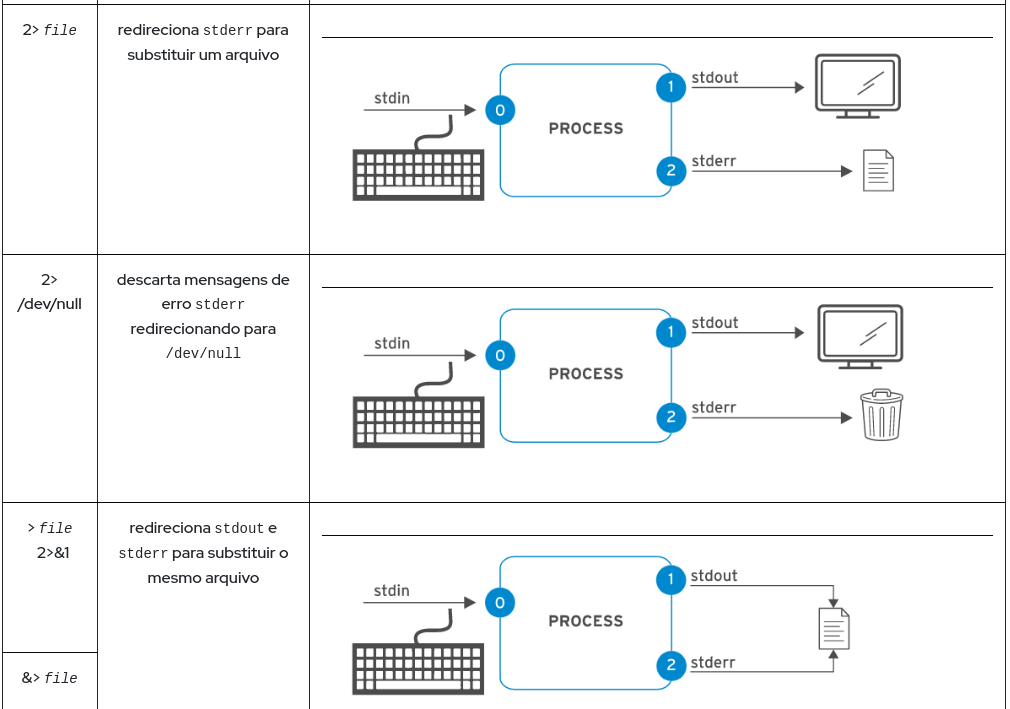
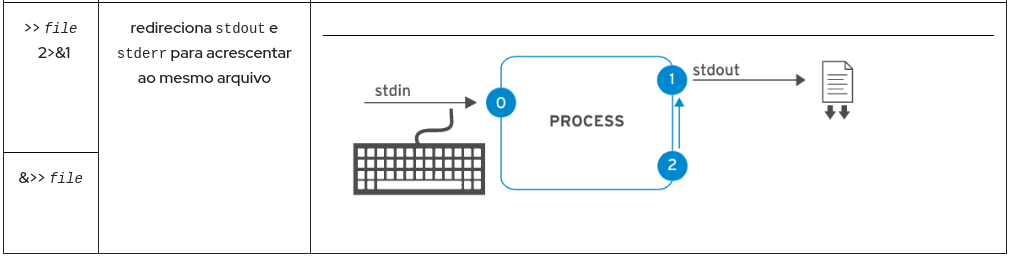
Importante
A ordem das operações de redirecionamento é importante. A sequência a seguir redireciona a saída padrão para file, e depois o erro padrão para o mesmo local da saída padrão (file).
> file 2>&1
No entanto, a sequência seguinte faz o redirecionamento na ordem oposta. Isso redireciona o erro padrão ao local padrão da saída padrão (a janela de terminal, portanto não há mudanças) e depois apenas redireciona a saída padrão para file.
2>&1 > file
Devido a isso, alguns preferem usar os operadores de fusão de redirecionamento:

No entanto, outros administradores de sistema e programadores que também usam outros shells relacionados ao bash (conhecidos como shells compatíveis com Bourne) para comandos de script pensam que os operadores de fusão de redirecionamento mais recentes devem ser evitados, pois não são padronizados nem implementados em todos os shells e têm outras limitações.
Os autores deste curso têm uma posição neutra sobre o tema; ambas as sintaxes podem ser encontradas no campo.
Exemplos de redirecionamento de saída
Diversas tarefas de administração de rotina são simplificadas através do redirecionamento. Use a tabela anterior como auxílio ao considerar os seguintes exemplos:
Salvar um carimbo de data e hora para referência futura.
[user@host ~]$ date > /tmp/saved-timestamp
Copiar as últimas 100 linhas de um arquivo de log para outro arquivo.
[user@host ~]$ tail -n 100 /var/log/dmesg > /tmp/last-100-boot-messages
Concatenar quatro arquivos em um.
[user@host ~]$ cat file1 file2 file3 file4 > /tmp/all-four-in-one
Listar somente os nomes de arquivos regulares e ocultos do diretório pessoal em um arquivo.
[user@host ~]$ ls -a > /tmp/my-file-names
Acrescentar a saída a um arquivo existente.
[user@host ~]$ echo "new line of information" >> /tmp/many-lines-of-information
[user@host ~]$ diff previous-file current-file >> /tmp/tracking-changes-made
Os próximos comandos geram mensagens de erro, porque alguns diretórios do sistema estão inacessíveis para usuários normais. Observe como as mensagens de erro são redirecionadas. Redirecionar erros para um arquivo enquanto visualiza a saída normal do comando no terminal.
[user@host ~]$ find /etc -name passwd 2> /tmp/errors
Salvar a saída de processos e as mensagens de erro em arquivos separados.
[user@host ~]$ find /etc -name passwd > /tmp/output 2> /tmp/errors
Ignorar e descartar mensagens de erro.
[user@host ~]$ find /etc -name passwd > /tmp/output 2> /dev/null
Armazenar em conjunto a saída e os erros gerados.
[user@host ~]$ find /etc -name passwd &> /tmp/save-both
Acrescentar a saída e os erros gerados a um arquivo existente.
[user@host ~]$ find /etc -name passwd >> /tmp/save-both 2>&1
Construção de pipelines
Um pipeline é uma sequência de um ou mais comandos separados por pipe, o caractere (|). Um pipe conecta a saída padrão do primeiro comando à entrada padrão do comando seguinte.
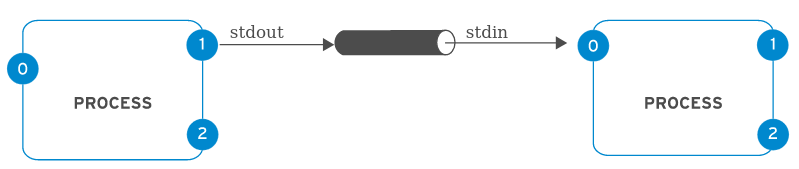
Pipelines permitem que a saída de um processo seja manipulada e formatada por outros processos antes de sua saída para o terminal. Uma imagem mental útil é imaginar que os dados “fluem” pelo pipeline de um processo a outro, sendo levemente alterados a cada comando no pipeline em que passam.
obs: Pipelines e redirecionamento de E/S manipulam a saída padrão e a entrada padrão. O redirecionamento envia a saída padrão para arquivos ou recebe deles a entrada padrão. Pipes enviam a saída padrão de um processo para a entrada padrão de outro processo.
Exemplos de pipeline
Este exemplo utiliza a saída do comando ls e usa less para exibi-la no terminal uma tela por vez.
[user@host ~]$ ls -l /usr/bin | less
A saída do comando ls é enviada para wc -l, que conta o número de linhas recebidas de ls e o imprime no terminal.
[user@host ~]$ ls | wc -l
Neste pipeline, head terá como saída as 10 primeiras linhas da saída de ls -t, com o resultado final redirecionado para um arquivo.
[user@host ~]$ ls -t | head -n 10 > /tmp/ten-last-changed-files
Pipelines, redirecionamento e o comando tee
Quando o redirecionamento é combinado com um pipeline, o shell configura todo o pipeline primeiro e depois redireciona input/output. Se o redirecionamento de saída for usado no meio de um pipeline, a saída irá para o arquivo e não para o próximo comando no pipeline.
Neste exemplo, a saída do comando ls irá para o arquivo, e less não exibirá resultados no terminal.
[user@host ~]$ ls > /tmp/saved-output | less
O comando tee supera essa limitação. Em um pipeline, tee copia sua entrada padrão para a saída padrão e também redireciona a saída padrão para os arquivos nomeados como argumentos do comando. Se você imaginar os dados como água fluindo através de uma tubulação, o tee pode ser visualizado como uma junção “T” no tubo, que direciona a saída em duas direções.
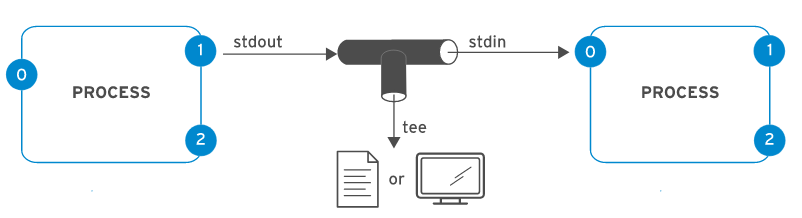
Exemplos de pipeline usando o comando tee
Este exemplo redireciona a saída do comando ls para o arquivo e passa-o a less para exibição no terminal, uma tela por vez.
[user@host ~]$ ls -l | tee /tmp/saved-output | less
Se tee for usado no fim de um pipeline, a saída final de um comando poderá ser salva e enviada ao terminal ao mesmo tempo.
[user@host ~]$ ls -t | head -n 10 | tee /tmp/ten-last-changed-files
Importante
É possível redirecionar o erro padrão através de um pipe, mas os operadores de fusão de redirecionamento (&> e &») não podem ser usados para fazer isso.
Esta é a maneira correta de redirecionar tanto a saída padrão quanto o erro padrão através de um pipe:
[user@host ~]$ find -name / passwd 2>&1 | less
Edição de arquivos de texto a partir do prompt do shell
Objetivos
Depois de concluir esta seção, você deverá ser capaz de criar e editar arquivos de texto a partir da linha de comando usando o editor vim. Edição de arquivos com o Vim
Um princípio de design essencial no Linux é que as informações e as definições de configuração são normalmente armazenadas em arquivos de texto. Esses arquivos podem ser estruturados de várias maneiras, como listas de configurações, em formatos semelhantes a INI, como XML estruturado ou YAML, e assim por diante. No entanto, a vantagem dos arquivos de texto é que eles podem ser visualizados e editados usando qualquer editor de texto simples.
O Vim é uma versão melhorada do editor vi distribuído com sistemas Linux e UNIX. O Vim é altamente configurável e eficiente para usuários experientes, incluindo recursos como edição em janela dividida, formatação em cores e destaque para edição de texto.
Por que saber usar o Vim?
Você deve saber usar pelo menos um editor de texto que pode ser usado em um prompt do shell de somente texto. Se souber, poderá editar arquivos de configuração de texto de uma janela de terminal ou de logins remotos com o ssh ou o console da web. Dessa forma, não é necessário acessar uma área de trabalho gráfica para editar arquivos em um servidor, e esse servidor pode não precisar executar um ambiente gráfico de área de trabalho.
Então por que aprender Vim em vez de outras opções possíveis? A principal razão é que o Vim está quase sempre instalado em um servidor se houver algum editor de texto presente. O motivo é que vi foi especificado pelo padrão POSIX que o Linux e muitos outros sistemas operacionais semelhantes a UNIX cumprem em grande parte.
Além disso, o Vim é frequentemente usado como implementação do vi em outros sistemas operacionais ou distribuições comuns. Por exemplo, o macOS atualmente inclui uma instalação leve do Vim por padrão. Por isso, as habilidades do Vim aprendidas para o Linux também podem ajudar você realizar tarefas em outros lugares.
Inicialização do Vim
O Vim pode estar instalado no Red Hat Enterprise Linux de duas maneiras diferentes. Elas podem afetar os recursos e os comandos do Vim disponíveis para você.
Seu servidor pode ter apenas o pacote vim-minimal instalado. Essa é uma instalação muito leve que inclui apenas o conjunto de recursos principais e o comando vi. Nesse caso, você pode abrir um arquivo para edição com vi filename, e todos os principais recursos discutidos nesta seção estarão disponíveis para você.
Como alternativa, seu servidor pode ter o pacote vim-enhanced instalado. Ele fornece um conjunto muito mais abrangente de recursos, um sistema on-line de ajuda e um programa de tutorial. Para iniciar o Vim nesse modo avançado, você usa o comando vim.
[user@host ~]$ vim filename
Nos dois modos, os principais recursos que discutiremos nesta seção funcionarão com os dois comandos. Nota
Se vim-enhanced estiver instalado, os usuários regulares terão um conjunto de alias de shell para que, se executarem o comando vi, recebam automaticamente o comando vim no lugar. Isso não se aplica ao root e aos outros usuários com UIDs abaixo de 200 (que são usados pelos serviços do sistema).
Se você estiver editando arquivos como o usuário root e esperar que o vi seja executado no modo avançado, isso poderá ser uma surpresa. Da mesma forma, se vim-enhanced estiver instalado e um usuário regular desejar usar o vi simples por algum motivo, ele poderá precisar usar o \vi para substituir o alias temporariamente.
Os usuários avançados podem usar \vi –version e vim –version para comparar os conjuntos de recursos dos dois comandos.
Modos de operação do Vim
Uma característica incomum do Vim é que ele tem vários modos de operação, incluindo modo de comando, modo de comando estendido, modo de edição e modo visual. Dependendo do modo, você pode emitir comandos, editar texto ou trabalhar com blocos de texto. Como um novo usuário do Vim, você deve sempre estar ciente de seu modo atual, pois as teclas têm diferentes efeitos em diferentes modos.
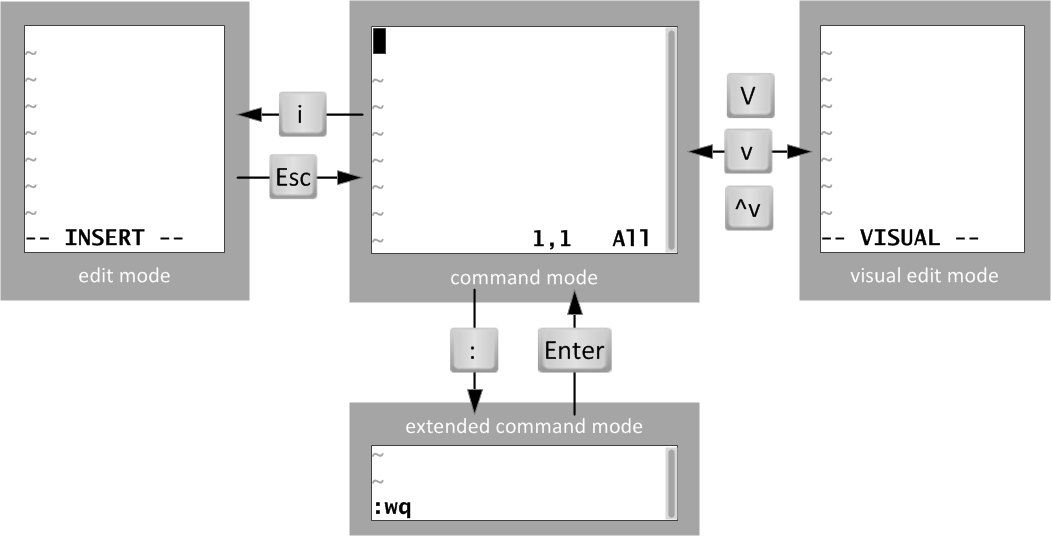
Figura 5.10: Alternância entre modos do Vim
Quando você abre o Vim pela primeira vez, ele é iniciado em Modo de comando, que é usado para navegação, operações de cortar e colar e manipulação de texto. Digite os outros modos com pressionamentos de teclas individuais para acessar a funcionalidade de edição específica:
O atalho de teclado i entra no modo de inserção, em que todo o texto digitado se torna conteúdo do arquivo. Pressionar Esc retorna para o modo de comando.
O atalho de teclado v entra no modo visual, em que vários caracteres podem ser selecionados para manipulação de texto. Use Shift+V para seleção de várias linhas e Ctrl+V para seleção em bloco. O mesmo atalho de teclado usado para entrar no modo visual (v, Shift+V ou Ctrl+V) é usado para sair dele.
O atalho de teclado : inicia o modo de comando estendido para tarefas como gravar o arquivo (para salvá-lo) ou sair do editor do Vim.
Nota
Se você não tiver certeza do modo do Vim em que está, poderá pressionar Esc algumas vezes para voltar ao modo de comando. A tecla Esc não tem nenhum efeito no modo de comando, por isso não há problema em pressionar algumas vezes a mais.
O fluxo de trabalho mínimo e básico do Vim
O Vim tem atalhos de teclado eficientes e coordenados para tarefas de edição avançadas. Embora se tornem muito úteis com a prática, os recursos do Vim podem sobrecarregar novos usuários.
A tecla i coloca o Vim no modo de inserção. Todo o texto digitado depois disso é tratado como conteúdo do arquivo até que você saia do modo de inserção. A tecla Esc sai do modo de inserção e retorna o Vim para o modo de comando. A tecla u desfaz a edição mais recente. Pressione a tecla x para excluir um único caractere. O comando :w grava (salva) o arquivo e permanece no modo de comando para continuar editando. O comando :wq grava (salva) o arquivo e sai do Vim. O comando :q! sai do Vim, descartando todas as alterações no arquivo desde a última gravação. O usuário do Vim deve aprender esses comandos para realizar qualquer tarefa de edição.
Reorganização do texto existente
No Vim, copiar e colar são conhecidos como yank e put e usam os caracteres de comando y e p. Comece posicionando o cursor no primeiro caractere a ser selecionado e entre no visual. Use as teclas de seta para expandir a seleção visual. Quando estiver pronto, pressione y para copiar (yank) a seleção para a memória. Posicione o cursor no local novo e pressione p para colocar a seleção no cursor.
Modo visual no Vim
O modo visual é uma ótima maneira de destacar e manipular texto. Existem três atalhos de teclado:
Modo de caractere: v
Modo de linha: Shift+v
Modo de bloqueio: Ctrl+v
O modo de caractere destaca frases em um bloco de texto. A palavra VISUAL aparecerá na parte inferior da tela. Pressione v para entrar no modo de caracteres visuais. Shift+v entra no modo de linha. VISUAL LINE aparecerá na parte inferior da tela.
O modo de bloqueio visual é perfeito para manipular arquivos de dados. A partir do cursor, pressione Ctrl+v para entrar no bloco visual. VISUAL BLOCK aparecerá na parte inferior da tela. Use as teclas de seta para realçar a seção a ser alterada. Nota
O Vim tem muitos recursos, mas você deve dominar o fluxo de trabalho básico primeiro. Você não precisa entender rapidamente todo o editor e seus recursos. Sinta-se confortável com esses conceitos básicos através da prática e, depois, você poderá expandir seu vocabulário sobre o Vim aprendendo comandos adicionais do Vim (atalhos do teclado).
O exercício desta seção apresentará você ao comando vimtutor. Este tutorial, que vem com o vim-enhanced, é uma excelente maneira de aprender a funcionalidade principal do Vim.
Alteração do ambiente do shell
Objetivos
Depois de concluir esta seção, você deverá ser capaz de definir variáveis de shell para ajudar a executar comandos e editar scripts de inicialização Bash para definir variáveis de shell e de ambiente a fim de modificar o comportamento do shell e os programas executados a partir dele. Uso de variáveis de shell
O shell Bash permite que você defina variáveis de shell que pode usar para ajudar a executar comandos ou modificar o comportamento do shell. Você também pode exportar variáveis de shell como variáveis de ambiente, que são automaticamente copiadas para programas executados a partir desse shell quando iniciados. Você pode usar variáveis para facilitar a execução de um comando com um argumento longo ou para aplicar uma configuração comum aos comandos executados a partir desse shell.
As variáveis do shell são exclusivas de uma sessão de shell específica. Se você tiver duas janelas de terminal abertas ou duas sessões de login independentes para o mesmo servidor remoto, você está executando dois shells. Cada shell tem seu próprio conjunto de valores para suas variáveis do shell.
Atribuição de valores a variáveis
Atribua um valor a uma variável de shell usando a seguinte sintaxe:
VARIABLENAME=value
Os nomes das variáveis podem conter letras maiúsculas ou minúsculas, dígitos e o caractere de sublinhado (_). Por exemplo, os seguintes comandos definem as variáveis de shell:
[user@host ~]$ COUNT=40
[user@host ~]$ first_name=John
[user@host ~]$ file1=/tmp/abc
[user@host ~]$ _ID=RH123
Lembre-se, essa alteração afeta apenas o shell no qual você executa o comando, e nenhum outro shell que você esteja executando nesse servidor.
Você pode usar o comando set para listar todas as variáveis de shell que estão atualmente configuradas. (Isso também lista todas as funções de shell, que você pode ignorar.) Essa lista é longa o suficiente para que você possa enviar a saída para o comando less e possa visualizar uma página por vez.
[user@host ~]$ set | less
BASH=/usr/bin/bash
BASHOPTS=checkwinsize:cmdhist:complete_fullquote:expand_aliases:extglob:extquote:force_fignore:histappend:interactive_comments:progcomp:promptvars:sourcepath
BASHRCSOURCED=Y
...output omitted...
Recuperação de valores com expansão de variável
Você pode usar a expansão de variável para se referir ao valor de uma variável que você definiu. Para fazer isso, use um cifrão ($) antes do nome da variável. No exemplo a seguir, o comando echo imprime o restante da linha de comando inserida, mas depois que a expansão de variável foi executada.
Por exemplo, o seguinte comando define a variáveis COUNT como 40:
[user@host ~]$ COUNT=40
Se você inserir o comando echo COUNT, a string COUNT será impressa.
[user@host ~]$ echo COUNT
COUNT
Porém, se você digitar o comando echo $COUNT, o valor da variável COUNT será impresso.
[user@host ~]$ echo $COUNT
40
Um exemplo mais prático pode ser usar uma variável para se referir a um nome de arquivo longo para vários comandos.
[user@host ~]$ file1=/tmp/tmp.z9pXW0HqcC
[user@host ~]$ ls -l $file1
-rw-------. 1 student student 1452 Jan 22 14:39 /tmp/tmp.z9pXW0HqcC
[user@host ~]$ rm $file1
[user@host ~]$ ls -l $file1
total 0
Importante
Se houver algum caractere adjacente à direita do nome da variável, talvez seja necessário proteger o nome da variável com chaves. Sempre é possível usar chaves em expansão de variável, mas você também verá muitos exemplos nos quais elas não são necessárias e são omitidas.
No exemplo a seguir, o primeiro comando echo tenta expandir a variável inexistente COUNTx, que não causa um erro, mas não retorna nada.
[user@host ~]$ echo Repeat $COUNTx
Repeat
[user@host ~]$ echo Repeat ${COUNT}x
Repeat 40x
Configuração do Bash com variáveis de Shell
Algumas variáveis de shell são definidas quando o Bash é iniciado, mas podem ser modificadas para ajustar o comportamento do shell.
Por exemplo, duas variáveis de shell que afetam o histórico do shell e o comando history são HISTFILE e HISTFILESIZE. E se HISTFILE estiver definido, ele especifica a localização de um arquivo para salvar o histórico do shell ao sair. Por padrão, este é o arquivo ~/.bash_history do usuário. A variável HISTFILESIZE especifica quantos comandos devem ser salvos nesse arquivo do histórico.
Outro exemplo é PS1, que é uma variável de shell que controla a aparência do prompt de shell. Se você alterar esse valor, ele alterará a aparência do prompt de shell. Uma série de expansões de caracteres especiais compatíveis com o prompt é listada na seção “SOLICITAÇÃO” da página do man bash(1).
[user@host ~]$ PS1="bash\$ "
bash$ PS1="[\u@\h \W]\$ "
[user@host ~]$
Dois itens a serem observados sobre o exemplo acima: primeiro, como o valor definido por PS1 é um prompt, é quase sempre desejável finalizar o prompt com um espaço à direita. Segundo, sempre que o valor de uma variável contiver alguma forma de espaço, incluindo um espaço, um recuo ou uma quebra de linha, o valor deve estar entre aspas, simples ou duplas; isso não é opcional. Resultados inesperados ocorrerão se as aspas forem omitidas. Examine o exemplo PS1 acima e observe que ele está em conformidade com a recomendação (espaço à direita) e com a regra (aspas). Configuração de programas com variáveis de ambiente
O shell fornece um ambiente para os programas que você executa a partir desse shell. Entre outras coisas, esse ambiente inclui informações sobre o diretório de trabalho atual no sistema de arquivos, opções de linha de comando transmitidas para o programa e valores de variáveis de ambiente. Os programas podem usar essas variáveis de ambiente para alterar seu comportamento ou suas configurações padrão.
As variáveis do shell que não são variáveis de ambiente só podem ser usadas pelo shell. As variáveis de ambiente podem ser usadas pelo shell e por programas executados a partir desse shell. Nota
HISTFILE, HISTFILESIZE e PS1, aprendidas na seção anterior, não precisam ser exportadas como variáveis de ambiente porque são usadas apenas pelo próprio shell, e não pelos programas que você executa a partir do shell.
Você pode transformar qualquer variável definida no shell em uma variável de ambiente marcando-a para exportação com o comando export.
[user@host ~]$ EDITOR=vim
[user@host ~]$ export EDITOR
Você pode definir e exportar uma variável em uma etapa:
[user@host ~]$ export EDITOR=vim
Aplicativos e sessões usam essas variáveis para determinar seu comportamento. Por exemplo, o shell define automaticamente a variável HOME para o nome do arquivo do diretório pessoal do usuário quando ele é iniciado. Isso pode ser usado para ajudar os programas a definir onde salvar os arquivos.
Outro exemplo é LANG, que define o local. Ele ajusta o idioma preferido para a saída do programa, o conjunto de caracteres, a formatação de datas, números e moeda e a ordem de classificação dos programas. Se estiver configurado para en_US.UTF-8, o idioma usará inglês dos EUA com codificação de caracteres UTF-8 Unicode. Se estiver configurado para outro, por exemplo fr_FR.UTF-8, o idioma usará francês com codificação UTF-8 Unicode.
[user@host ~]$ date
Tue Jan 22 16:37:45 CST 2019
[user@host ~]$ export LANG=fr_FR.UTF-8
[user@host ~]$ date
mar. janv. 22 16:38:14 CST 2019
Outra variável de ambiente importante é PATH. A variável PATH contém uma lista de diretórios separados por dois-pontos que contêm programas:
[user@host ~]$ echo $PATH
/home/user/.local/bin:/home/user/bin:/usr/share/Modules/bin:/usr/local/bin:/usr/bin:/usr/local/sbin:/usr/sbin
Quando você executa um comando como ls, o shell procura pelo arquivo executável ls em cada um desses diretórios em ordem e executa o primeiro arquivo correspondente encontrado. (Em um sistema típico, isso significa /usr/bin/ls.)
Você pode facilmente adicionar diretórios adicionais ao final do PATH . Por exemplo, talvez você tenha programas executáveis ou scripts que você deseja executar como comandos regulares em /home/user/sbin . Você pode adicionar /home/user/sbin ao final do seu PATH para a sessão atual assim:
[user@host ~]$ export PATH=${PATH}:/home/user/sbin
Para listar todas as variáveis de ambiente para um determinado shell, execute o comando env:
[user@host ~]$ env
...output omitted...
LANG=en_US.UTF-8
HISTCONTROL=ignoredups
HOSTNAME=host.example.com
XDG_SESSION_ID=4
...output omitted...
Definição do editor de texto padrão
A variável de ambiente EDITOR especifica o programa que você deseja usar como seu editor de texto padrão para programas de linha de comando. Muitos programas usam vi ou vim se nada for especificado, mas você pode substituir essa preferência, se necessário:
[user@host ~]$ export EDITOR=nano
Importante
Por convenção, as variáveis de ambiente e de shell que são definidas automaticamente pelo shell têm nomes que usam todos os caracteres maiúsculos. Se você estiver definindo suas próprias variáveis, convém usar nomes compostos de caracteres minúsculos para evitar conflitos de nomenclatura. Definição automática de variáveis
Se você deseja definir variáveis shell ou de ambiente automaticamente ao iniciar o shell, é possível editar os scripts de inicialização do Bash. Quando o Bash é iniciado, vários arquivos de texto contendo comandos shell são executados, o que inicializa o ambiente do shell.
Os scripts exatos que são executados dependem de como o shell foi iniciado, se ele é um shell de login interativo, um shell sem login ou um script de shell.
Pressupondo que os arquivos padrão sejam /etc/profile, /etc/bashrc e ~/.bash_profile, se você quiser fazer uma alteração na sua conta de usuário que afete todos os prompts de shell interativos na inicialização, edite o arquivo ~/.bashrc. Por exemplo, você pode definir o editor padrão dessa conta como nano editando o arquivo para que seja:
.bashrc
Source global definitions
if [ -f /etc/bashrc ]; then . /etc/bashrc fi
User specific environment
PATH="$HOME/.local/bin:$HOME/bin:$PATH" export PATH
User specific aliases and functions
export EDITOR=nano
Nota
A melhor maneira de ajustar as configurações que afetam todas as contas de usuários é adicionando um arquivo com um nome que termina em .sh e contém as alterações no diretório /etc/profile.d. Para fazer isso, você precisa estar logado como usuário root. Remoção da configuração e da exportação de variáveis
Para remover totalmente a configuração e a exportação de uma variável, use o comando unset:
[user@host ~]$ echo $file1
/tmp/tmp.z9pXW0HqcC
[user@host ~]$ unset file1
[user@host ~]$ echo $file1
[user@host ~]$
Para remover a exportação de uma variável sem remover a configuração, use o comando export -n:
[user@host ~]$ export -n PS1
Capítulo 6. Gerenciamento de usuários e grupos locais
##Descrição de conceitos de usuário e grupo
Objetivos
Depois de concluir esta seção, você deverá ser capaz de descrever o propósito dos usuários e grupos em um sistema Linux. O que é um usuário?
Uma conta de usuário é usada para fornecer limites de segurança entre diferentes pessoas e programas que podem executar comandos.
Os usuários têm nomes de usuários para que usuários humanos possam identificá-los e para ser mais fácil de trabalhar com eles. Internamente, o sistema distingue as contas de usuários pelo número de identificação exclusivo atribuído a elas, ID do usuário ou UID. Se uma conta de usuário for usada por humanos, geralmente será atribuída uma senha secreta que o usuário usará para provar que é o usuário autorizado ao fazer login.
As contas de usuário são fundamentais para a segurança do sistema. Todo processo (programa em execução) no sistema é executado como um usuário particular. Todo arquivo tem um usuário específico como seu proprietário. A propriedade de arquivo ajuda o sistema a impor o controle de acesso aos usuários dos arquivos. O usuário associado a um processo em execução determina os arquivos e diretórios acessíveis a esse processo.
Os três principais tipos de conta de usuário são superusuário, usuário do sistema e usuário regular.
A conta de superusuário é para administração do sistema. O nome do superusuário é root e a conta tem UID 0. O superusuário tem acesso total ao sistema.
O sistema tem contas de usuário do sistema que são usadas por processos que fornecem serviços de suporte. Esses processos, ou daemons, geralmente não precisam ser executados como superusuário. Eles são atribuídos a contas não privilegiadas que permitem proteger os arquivos e outros recursos uns dos outros e de usuários regulares no sistema. Os usuários não fazem login interativamente usando uma conta de usuário do sistema.
A maioria dos usuários tem conta de usuário regular que eles usam para o seu trabalho diário. Como os usuários do sistema, os usuários regulares têm acesso limitado ao sistema.
O comando id é usado para mostrar informações sobre o usuário conectado atualmente.
[user01@host ~]$ id uid=1000(user01) gid=1000(user01) groups=1000(user01) context=unconfined_u:unconfined_r:unconfined_t:s0-s0:c0.c1023
Para ver informações básicas sobre outro usuário, passe o nome de usuário para o comando id como um argumento.
[user01@host]$ id user02 uid=1002(user02) gid=1001(user02) groups=1001(user02) context=unconfined_u:unconfined_r:unconfined_t:s0-s0:c0.c1023
Para visualizar o proprietário de um arquivo, use o comando ls -l. Para visualizar o proprietário de um diretório, use o comando ls -ld. Na saída a seguir, a terceira coluna mostra o nome de usuário.
[user01@host ~]$ ls -l file1 -rw-rw-r–. 1 user01 user01 0 Feb 5 11:10 file1 [user01@host]$ ls -ld dir1 drwxrwxr-x. 2 user01 user01 6 Feb 5 11:10 dir1
Para visualizar informações de processos, use o comando ps. O padrão é mostrar apenas os processos no shell atual. Adicione a opção a para visualizar todos os processos em um terminal. Para visualizar o usuário associado a um processo, inclua a opção u. Na saída a seguir, a primeira coluna mostra o nome de usuário.
[user01@host]$ ps -au USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND root 777 0.0 0.0 225752 1496 tty1 Ss+ 11:03 0:00 /sbin/agetty -o -p – \u –noclear tty1 linux root 780 0.0 0.1 225392 2064 ttyS0 Ss+ 11:03 0:00 /sbin/agetty -o -p – \u –keep-baud 115200,38400,9600 user01 1207 0.0 0.2 234044 5104 pts/0 Ss 11:09 0:00 -bash user01 1319 0.0 0.2 266904 3876 pts/0 R+ 11:33 0:00 ps au
A saída do comando anterior exibe os usuários por nome, mas o sistema operacional usa as UIDs para rastrear usuários internamente O mapeamento de nomes de usuários para UIDs é definido em bancos de dados de informações de conta. Por padrão, os sistemas usam o arquivo simples /etc/passwd para armazenar informações sobre os usuários locais.
Cada linha no arquivo /etc/passwd contém informações sobre um usuário. Ele está dividido em sete campos separados por cores. Veja um exemplo de uma linha de /etc/passwd:
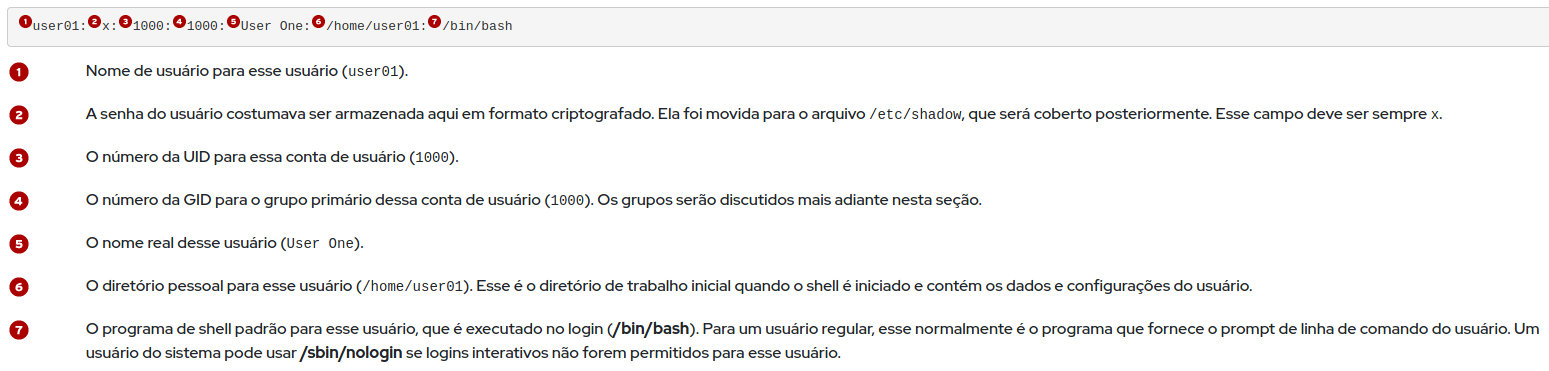
O que é um grupo?
Um grupo é uma coleção de usuários que precisam compartilhar o acesso a arquivos e outros recursos do sistema. Os grupos podem ser usados para conceder acesso a arquivos para um conjunto de usuários, em vez de apenas um único usuário.
Como os usuários, os grupos têm nomes de grupos ser mais fácil trabalhar com eles. Internamente, o sistema distingue grupos pelo número de identificação exclusivo atribuído a eles, ID do grupo ou GID.
O mapeamento de nomes de grupos para GIDs é definido em bancos de dados de informações de conta de grupo. Por padrão, os sistemas usam o arquivo simples /etc/group para armazenar informações sobre os grupos locais.
Cada linha no arquivo /etc/group contém informações sobre um grupo. Cada entrada de grupo é dividida em quatro campos separados por cor. Veja um exemplo de uma linha de /etc/group:

Grupos primários e grupos suplementares
Cada usuário tem exatamente um grupo principal. Para usuários locais, esse é o grupo listado por número de GID no arquivo /etc/passwd. Por padrão, esse é o grupo que possuirá novos arquivos criados pelo usuário.
Normalmente, quando você cria um novo usuário regular, um novo grupo com o mesmo nome daquele usuário é criado. Esse grupo é usado como grupo primário para o novo usuário e esse usuário é o único membro desse grupo privado de usuários. Isso ajuda a simplificar o gerenciamento de permissões de arquivos, o que será discutido posteriormente neste curso.
Os usuários também podem ter grupos suplementares . A associação em grupos suplementares é determinada pelo arquivo /etc/group. Os usuários recebem acesso aos arquivos com base no acesso de qualquer um de seus grupos. Não importa se o grupo ou grupos que têm acesso são primários ou suplementares para o usuário.
Por exemplo, se o usuário user01 tiver um grupo primário user01 e grupos suplementares wheel e webadmin, esse usuário poderá ler arquivos legíveis por qualquer um desses três grupos.
O comando id também pode ser usado para descobrir sobre a associação de um usuário em um grupo.
[user03@host ~]$ id uid=1003(user03) gid=1003(user03) groups=1003(user03),10(wheel),10000(group01) context=unconfined_u:unconfined_r:unconfined_t:s0-s0:c0.c1023
No exemplo anterior, o user03 tem o grupo user03 como seu grupo primário (gid). O item groups lista todos os grupos desse usuário. Além do grupo primário user03, o usuário tem os grupos wheel e group01 como grupos suplementares.
Obtenção de acesso de superusuário
Objetivos
Depois de concluir esta seção, você poderá alternar para a conta de superusuário para gerenciar um sistema Linux e conceder acesso de superusuário a outros usuários por meio do comando sudo. O superusuário
A maioria dos sistemas operacionais tem algum tipo de superusuário, ou seja, um usuário que tem todos os poderes sobre o sistema. No Red Hat Enterprise Linux esse usuário é chamado de usuário root. Ele tem o poder de superar privilégios normais no sistema de arquivos e é usado para gerenciar e administrar o sistema. Para executar tarefas como a instalação ou a remoção de software e o gerenciamento de arquivos e diretórios de sistema, é necessário escalonar seus privilégios para o usuário root.
O usuário root, entre os usuários normais, consegue controlar a maioria dos dispositivos, mas há algumas exceções. Por exemplo, usuários normais podem controlar dispositivos removíveis, como dispositivos USB. Sendo assim, usuários normais podem adicionar e remover arquivos e também para gerenciar um dispositivo removível, mas somente o root consegue gerenciar discos rígidos “fixos” por padrão.
No entanto, esse privilégio ilimitado exige responsabilidade. O usuário root tem poder ilimitado para danificar o sistema: apagar arquivos e diretórios, apagar contas de usuário, adicionar backdoors etc. Se a conta do usuário root for comprometida, outra pessoa terá controle administrativo do sistema. No decorrer deste curso, os administradores são incentivados a fazer login como um usuário normal e a escalonar privilégios para root somente quando necessário.
A conta root no Linux equivale em grande parte à conta local de Administrador no Microsoft Windows. No Linux, a maioria dos administradores de sistemas faz login no sistema como um usuário sem privilégios e usa várias ferramentas para obter temporariamente privilégios de root. Atenção
Uma prática comum no Microsoft Windows no passado era o usuário local Administrador fazer login diretamente para executar as tarefas de administrador de sistema. Embora isso seja possível no Linux, a Red Hat recomenda que os administradores do sistema não façam login diretamente como root. Em vez disso, os administradores de sistema devem fazer login como um usuário normal e usar outros mecanismos (su, sudo ou PolicyKit, por exemplo) para obter temporariamente privilégios de superusuário.
Ao fazer login como superusuário, todo o ambiente de área de trabalho é executado com privilégios administrativos desnecessariamente. Nessa situação, qualquer vulnerabilidade de segurança que normalmente só comprometeria a conta de usuário tem o potencial de comprometer todo o sistema. Alternância de usuários
O comando su permite que os usuários alternem para contas de usuário diferentes. Se executar su em uma conta de usuário comum, você será solicitado a fornecer a senha da conta para a qual deseja alternar. Quando root executa su, você não precisa digitar a senha do usuário.
[user01@host ~]$ su - user02 Password: [user02@host ~]$
Se você omitir o nome de usuário, o comando su ou su - tenta alternar para root por padrão.
[user01@host ~]$ su - Password: [root@host ~]#
O comando su inicia um shell que não é de login, enquanto o comando su - (com a opção de dash) inicia um shell de login. A principal diferença entre os dois comandos é que su - define o ambiente do shell como se fosse um novo login como esse usuário, enquanto su apenas inicia um shell como esse usuário, mas usa as configurações de ambiente do usuário original.
Na maioria dos casos, os administradores deverão executar su - para obter um shell com as configurações de ambiente normais do usuário de destino. Para obter mais informações, consulte a página do man bash(1). Nota
O comando su é usado mais frequentemente para obter uma interface de linha de comando (prompt do shell) executada como outro usuário, geralmente root. Entretanto, com a opção -c, ele pode ser usado como o utilitário runas do Windows para executar um programa arbitrário como outro usuário. Execute info su para ver mais detalhes. Execução de comandos com Sudo
Em alguns casos, a conta de usuário root pode não ter uma senha válida por motivos de segurança. Nesse caso, os usuários não podem fazer login no sistema como root diretamente com uma senha, e su não pode ser usado para obter um shell interativo. Uma ferramenta que pode ser usada para obter acesso ao root nesse caso é sudo.
Diferentemente do su, o sudo normalmente exige que os usuários informem sua própria senha para autenticação, não a senha da conta de usuário que estão tentando acessar. Ou seja, os usuários que usam sudo para executar comandos como root não precisam saber a senha de root. Em vez disso, eles usam suas próprias senhas para autenticar o acesso.
Além disso, o sudo pode ser configurado para permitir que usuários específicos executem qualquer comando como outro usuário ou apenas alguns comandos como esse usuário.
Por exemplo, quando sudo é configurado para permitir que o usuário user01 execute o comando usermod como root, o user01 poderá executar o seguinte comando para bloquear ou desbloquear uma conta de usuário:
[user01@host ~]$ sudo usermod -L user02 [sudo] password for user01: [user01@host ~]$ su - user02 Password: su: Authentication failure [user01@host ~]$
Se um usuário tentar executar um comando como outro usuário e a configuração sudo não permitir, o comando será bloqueado, a tentativa será registrada e, por padrão, um e-mail será enviado ao usuário root.
[user02@host ~]$ sudo tail /var/log/secure [sudo] password for user02: user02 is not in the sudoers file. This incident will be reported. [user02@host ~]$
Um benefício adicional do uso do sudo é que todos os comandos executados são registrados, por padrão, em /var/log/secure.
[user01@host ~]$ sudo tail /var/log/secure …output omitted… Feb 6 20:45:46 host sudo[2577]: user01 : TTY=pts/0 ; PWD=/home/user01 ; USER=root ; COMMAND=/sbin/usermod -L user02 …output omitted…
No Red Hat Enterprise Linux 7 e no Red Hat Enterprise Linux 8, todos os membros do grupo wheel podem usar sudo para executar comandos como qualquer usuário, incluindo root. É solicitado que o usuário digite sua própria senha. Essa é uma mudança do Red Hat Enterprise Linux 6 e versões anteriores, onde os usuários que eram membros do grupo wheel não tinham esse acesso administrativo por padrão. Atenção
O RHEL 6 não concedia ao grupo wheel privilégios especiais por padrão. Sites que usam esse grupo para um objetivo diferente do padrão poderão se surpreender quando o RHEL 7 e o RHEL 8 automaticamente concederem a todos os membros do wheel privilégios completos no sudo. Isso pode levar usuários não autorizados a obter acesso administrativo nos sistemas RHEL 7 e RHEL 8.
Historicamente, sistemas semelhantes ao UNIX usam a associação ao grupo wheel para conceder ou controlar o acesso de superusuário.
Obtenção de um root shell interativo com o Sudo
Se houver uma conta de usuário não administrativa no sistema que possa usar sudo para executar o comando su, você poderá executar sudo su - nessa conta para obter um shell de usuário root interativo. Isso funciona porque sudo executará su - como root, e o root não precisa digitar uma senha para usar o su.
Outra maneira de acessar a conta root com o sudo é usar o comando sudo -i. Isso alternará para a conta root e executará o shell padrão desse usuário (normalmente bash) e os scripts de login de shell associados. Se você desejar apenas executar o shell, poderá usar o comando sudo -s.
Por exemplo, um administrador pode obter um shell interativo como root em uma instância do AWS EC2 usando a autenticação de chave pública SSH para fazer login como usuário normal ec2-user e, depois, executando sudo -i para obter o shell do usuário root.
[ec2-user@host ~]$ sudo -i [sudo] password for ec2-user: [root@host ~]#
O comando sudo su - e sudo -i não se comportam exatamente da mesma maneira. Isso será discutido brevemente no final da seção.
Configuração do Sudo
O arquivo de configuração principal do para sudo é /etc/sudoers. Para evitar problemas se vários administradores tentarem editá-lo ao mesmo tempo, ele só deve ser editado com o comando especial visudo.
Por exemplo, a linha a seguir do arquivo /etc/sudoers permite acesso sudo aos membros do grupo wheel.
%wheel ALL=(ALL) ALL
Nessa linha, %wheel é o usuário ou grupo a quem a regra se aplica. Um % especifica que esse é um grupo, o grupo wheel . O ALL=(ALL) especifica que em qualquer host que possa ter esse arquivo, wheel pode executar qualquer comando. O final ALL especifica que wheel pode executar esses comandos como qualquer usuário no sistema.
Por padrão, /etc/sudoers também inclui o conteúdo de qualquer arquivo no diretório /etc/sudoers.d como parte do arquivo de configuração. Isso permite que um administrador adicione acesso a sudo para um usuário simplesmente colocando um arquivo apropriado nesse diretório. Nota
Usar arquivos suplementares no diretório /etc/sudoers.d é conveniente e simples. Você pode ativar ou desativar o acesso a sudo simplesmente copiando um arquivo para o diretório ou removendo-o do diretório.
Neste curso, você criará e removerá arquivos no diretório /etc/sudoers.d para configurar o acesso sudo para usuários e grupos.
Para permitir acesso sudo total para o usuário user01, crie /etc/sudoers.d/user01 com o seguinte conteúdo:
user01 ALL=(ALL) ALL
Para permitir acesso total do grupo group01 a sudo, crie /etc/sudoers.d/group01 com o seguinte conteúdo:
%group01 ALL=(ALL) ALL
Também é possível configurar sudo para permitir que um usuário execute comandos como outro usuário sem digitar sua senha:
ansible ALL=(ALL) NOPASSWD:ALL
Embora haja riscos óbvios de segurança para a concessão desse nível de acesso a um usuário ou grupo, ele é frequentemente usado com instâncias de nuvem, máquinas virtuais e sistemas de provisionamento para ajudar a configurar os servidores. A conta com esse acesso deve ser cuidadosamente protegida e pode exigir a autenticação de chave pública SSH para que um usuário em um sistema remoto possa acessá-la.
Por exemplo, o AMI oficial para o Red Hat Enterprise Linux no Amazon Web Services Marketplace é fornecido com o root e as senhas dos usuários ec2-user bloqueadas. A conta de usuário ec2-user é configurada para permitir acesso remoto interativo através da autenticação de chave pública SSH. O usuário ec2-user também pode executar qualquer comando como root sem uma senha porque a última linha do arquivo /etc/sudoers do AMI é configurado da seguinte forma:
ec2-user ALL=(ALL) NOPASSWD: ALL
O requisito para digitar uma senha para sudo pode ser habilitado novamente ou outras alterações podem ser feitas para aumentar a segurança como parte do processo de configuração do sistema. Nota
Neste curso, você pode ver sudo su - usado em vez de sudo -i. Ambos os comandos funcionam, mas existem algumas diferenças sutis entre eles.
O comando sudo su - configura o ambiente root exatamente como um login normal porque o comando su - ignora as configurações feitas por sudo e configura o ambiente a partir do zero.
A configuração padrão do comando sudo -i realmente configura alguns detalhes do ambiente do usuário root de modo diferente de um login normal. Por exemplo, ela define a variável de ambiente PATH de modo ligeiramente diferente. Isso afeta onde o shell procurará comandos.
Você pode fazer com que sudo -i se comporte mais como su - editando /etc/sudoers com visudo . Encontre a linha
Defaults secure_path = /sbin:/bin:/usr/sbin:/usr/bin
e a substitua pelas duas linhas seguintes:
Defaults secure_path = /usr/local/bin:/usr/bin Defaults>root secure_path = /usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin
Para a maioria das finalidades, essa não é uma diferença importante. No entanto, para consistência de configurações PATH em sistemas com o arquivo padrão /etc/sudoers, os autores deste curso usam sudo -i nos exemplos e exercícios.
##Gerenciamento de contas de usuários locais
##Objetivos
Depois de concluir esta seção, você deverá ser capaz de criar, modificar e excluir contas de grupo local. Gerenciamento de usuários locais
Para gerenciar contas de usuários locais, você pode usar várias ferramentas da linha de comando.
Criação de usuários a partir da linha de comando
O comando useradd username cria um novo usuário chamado username. Ele configura o diretório pessoal e as informações da conta do usuário, além de criar um grupo privado para o usuário chamado username . Nesse ponto, a conta não tem uma senha válida definida. O usuário não pode fazer login até que uma senha seja definida.
O comando useradd --help exibe as opções básicas que podem ser usadas para substituir os padrões. Na maioria dos casos, as mesmas opções podem ser usadas com o comando usermod para modificar um usuário existente.
Alguns padrões, como o intervalo de números de UID válidos e as regras padrão para vencimento de senha, são lidos a partir do arquivo /etc/login.defs. Os valores nesse arquivo são usados somente ao criar novos usuários. Uma alteração nesse arquivo não afeta os usuários existentes.
Modificação de usuários existentes a partir da linha de comando
O comando usermod --help exibe as opções básicas que podem ser usadas para modificar uma conta. Algumas opções comuns incluem:
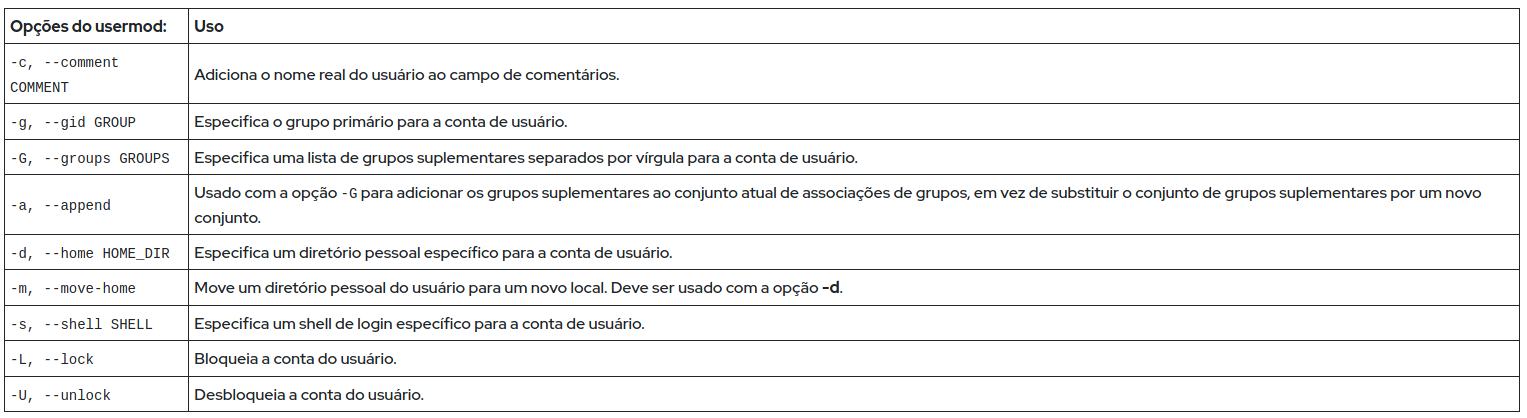
Exclusão de usuários a partir da linha de comando
O comando userdel username remove os detalhes de username de /etc/passwd, mas deixa o diretório pessoal do usuário intacto.
O comando userdel -r username remove os detalhes de username de /etc/passwd, bem como o diretório pessoal do usuário.
Atenção
Quando um usuário é removido com userdel, sem a opção -r especificada, o sistema terá arquivos pertencentes a uma UID não atribuída. Isso também pode acontecer quando um arquivo que tem um usuário excluído como proprietário existir fora do diretório pessoal do usuário. Essa situação pode levar a vazamentos de informações e a outros problemas de segurança.
No Red Hat Enterprise Linux 7 e no Red Hat Enterprise Linux 8, o comando useradd atribui a novos usuários a primeira UID livre maior ou igual a 1.000, a menos que você especifique uma explicitamente usando a opção -u.
É assim que acontece o vazamento de informações. Se a primeira UID livre tiver sido anteriormente atribuída a uma conta de usuário que, depois, foi removida do sistema, a UID do antigo usuário será novamente atribuída ao novo usuário, dando a este novo usuário a propriedade dos arquivos restantes do antigo usuário.
O cenário a seguir demonstra essa situação.
[root@host ~]# useradd user01
[root@host ~]# ls -l /home
drwx------. 3 user01 user01 74 Feb 4 15:22 user01
[root@host ~]# userdel user01
[root@host ~]# ls -l /home
drwx------. 3 1000 1000 74 Feb 4 15:22 user01
[root@host ~]# useradd user02
[root@host ~]# ls -l /home
drwx------. 3 user02 user02 74 Feb 4 15:23 user02
drwx------. 3 user02 user02 74 Feb 4 15:22 user01
Observe que o user02 agora é proprietário de todos os arquivos dos quais o user01 era proprietário anteriormente.
Dependendo da situação, uma solução para esse problema poderá ser remover todos os arquivos sem proprietário do sistema quando o usuário que os criou for excluído. Outra solução será atribuir manualmente os arquivos sem proprietário a um usuário diferente. O usuário root pode usar o comando find / -nouser -o -nogroup para localizar todos os arquivos e diretórios sem proprietários.
Configuração de senhas a partir da linha de comando
O comando passwd username define a senha inicial ou altera a senha existente de username.
O usuário root pode configurar uma senha para qualquer valor. Uma mensagem é exibida se a senha não atender aos critérios mínimos recomendados, mas será seguida por um prompt para redigitar a nova senha, e todos os tokens serão atualizados com êxito.
[root@host ~]# passwd user01
Changing password for user user01.
New password: redhat
BAD PASSWORD: The password fails the dictionary check - it is based on a dictionary word
Retype new password: redhat
passwd: all authentication tokens updated successfully.
[root@host ~]#
Um usuário regular deve escolher uma senha que tenha pelo menos oito caracteres e que não seja baseada em uma palavra do dicionário, no nome de usuário ou na senha anterior.
Intervalos de UID
Números de UID e intervalos de números específicos são usados para fins determinados pelo Red Hat Enterprise Linux.
A UID 0 sempre é atribuída à conta de superusuário, root.
As UID de 1 a 200 estão no intervalo de "usuários do sistema" atribuídos estaticamente para processos do sistema pela Red Hat.
As UIDs de 201 a 999 estão no intervalo de "usuários do sistema" usado por processos do sistema que não são proprietários de arquivos no sistema de arquivos. Elas são geralmente atribuídas dinamicamente a partir do pool disponível quando o software que precisa delas é instalado. Os programas são executados como esses usuários "sem privilégios" do sistema para limitar o acesso apenas aos recursos dos quais eles precisam para funcionar.
As UIDs 1000 e superiores estão no intervalo disponível para atribuição a usuários regulares.
Gerenciamento de contas de grupos locais
Objetivos
Depois de concluir esta seção, os alunos deverão ser capazes de criar, modificar e excluir contas de grupo local. Gerenciamento de grupos locais
Um grupo deve existir antes que um usuário possa ser adicionado a esse grupo. Várias ferramentas de linha de comando são usadas para gerenciar contas de grupo locais.
Criação de grupos a partir da linha de comando
O comando groupadd cria grupos. Sem opções o comando groupadd usa a próxima GID disponível no intervalo especificado no arquivo /etc/login.defs ao criar os grupos.
A opção -g especifica uma GID específica para o grupo usar.
[user01@host ~]$ sudo groupadd -g 10000 group01
[user01@host ~]$ tail /etc/group
...output omitted...
group01:x:10000:
Nota
Dada a criação automática de grupos privados de usuário (GID >1000), geralmente recomenda-se determinar um intervalo de GIDs a ser usado para grupos suplementares. Um intervalo maior evitará uma colisão com um grupo do sistema (GID 0-999).
A opção -r cria um grupo do sistema usando uma GID no intervalo de GIDs de sistema válidos listados no arquivo /etc/login.defs. Os itens de configuração SYS_GID_MIN e SYS_GID_MAX em /etc/login.defs definem o intervalo de GIDs do sistema.
[user01@host ~]$ sudo groupadd -r group02
[user01@host ~]$ tail /etc/group
...output omitted...
group01:x:10000:
group02:x:988:
Modificação de grupos existentes a partir da linha de comando
O comando groupmod altera as propriedades de um grupo existente. A opção -n especifica um novo nome para o grupo.
[user01@host ~]$ sudo groupmod -n group0022 group02
[user01@host ~]$ tail /etc/group
...output omitted...
group0022:x:988:
Observe que o nome do grupo é atualizado para group0022 de group02.
A opção -g especifica uma nova GID.
[user01@host ~]$ sudo groupmod -g 20000 group0022
[user01@host ~]$ tail /etc/group
...output omitted...
group0022:x:20000:
Observe que a GID é atualizada para 20000 de 988.
Exclusão de grupos a partir da linha de comando
O comando groupdel remove grupos.
[user01@host ~]$ sudo groupdel group0022
Nota
Não é possível remover um grupo se for o grupo principal de qualquer usuário existente. Assim como ocorre com userdel, verifique todos os sistemas de arquivos para garantir que nenhum arquivo permanece no sistema que seja de propriedade do grupo.
Alteração da associação do grupo na linha de comando
A associação de um grupo é controlada com o gerenciamento de usuários. Use o comando usermod -g para alterar o grupo principal de um usuário.
[user01@host ~]$ id user02
uid=1006(user02) gid=1008(user02) groups=1008(user02)
[user01@host ~]$ sudo usermod -g group01 user02
[user01@host ~]$ id user02
uid=1006(user02) gid=10000(group01) groups=10000(group01)
Use o comando usermod -aG para adicionar um usuário a um gripo suplementar.
[user01@host ~]$ id user03
uid=1007(user03) gid=1009(user03) groups=1009(user03)
[user01@host ~]$ sudo usermod -aG group01 user03
[user01@host ~]$ id user03
uid=1007(user03) gid=1009(user03) groups=1009(user03),10000(group01)
Importante
O uso da opção -a passa a função usermod para o modo acréscimo. Sem -a, o usuário será removido de qualquer um dos grupos suplementares atuais que não estejam incluídos na lista de opções -G.
Gerenciamento de senhas de usuários
Objetivos
Depois de concluir esta seção, você poderá definir uma política de gerenciamento de senha para usuários e bloquear e desbloquear manualmente contas de usuário. Senhas shadow e política de senha
No passado, as senhas criptografadas eram armazenadas no arquivo /etc/passwd, que podia ser lido por todos. Achava-se que isso era razoavelmente seguro até que ataques de dicionário a senhas criptografadas se tornaram comuns. A partir daí, as senhas criptografadas foram movidas para um arquivo /etc/shadow que só pode ser lido por root. Esse novo arquivo também permitiu a implementação de recursos de vencimento e expiração de senhas.
Como /etc/passwd, cada usuário tem uma linha no arquivo /etc/shadow. Uma linha de amostra de /etc/shadow com seus nove campos separados por dois-pontos é mostrada abaixo.
senhas_shadow.png
Formato de uma senha criptografada
O campo de senha criptografada armazena três informações: o algoritmo de hashing usado, o sal e o hash criptografado. Cada informação é delimitada pelo símbolo $.
shadow_senhas_a2.png
O principal motivo para combinar um salt com a senha é defender-se contra ataques usando listas pré-testadas de hashes de senha. A adição de salts altera os hashes resultantes, tornando a lista previamente computada inútil. Se um invasor conseguir obter uma cópia de um arquivo /etc/shadow que está usando salts, ele precisará executar uma adivinhação de senha de força bruta, exigindo mais tempo e esforço.
Verificação de senha
Quando um usuário tenta fazer login, o sistema procura a entrada do usuário em /etc/shadow, combina o sal para o usuário com a senha não criptografada que foi digitada e a criptografa usando o algoritmo de hash especificado. Se o resultado corresponder ao hash criptografado, o usuário digitou a senha correta. Se o resultado não corresponder ao hash criptografado, o usuário digitou uma senha incorreta, e a tentativa de login falhará. Esse método permite que o sistema determine se o usuário digitou a senha correta sem armazenar a senha de uma forma que ela possa ser copiada para fazer o login.
Configuração do vencimento de senha
O diagrama a seguir relaciona os parâmetros de vencimento de senha relevantes que podem ser ajustados usando o comando chage para implementar uma política de vencimento de senha.
shadow_file.png
[user01@host ~]$ sudo chage -m 0 -M 90 -W 7 -I 14 user03
O comando chage anterior usa as opções -m, -M, -W e -I para definir a idade mínima, a idade máxima, o período de aviso e o período de inatividade da senha do usuário, respectivamente.
O comando chage -d 0 user03 força o usuário user03 a atualizar sua senha na próxima vez que fizer login.
O comando chage -l user03 exibe os detalhes de vencimento de senha de user03.
O comando chage -E 2019-08-05 user03 faz com que a conta do usuário user03 expire em 2019-08-05 (no formato AAAA-MM-DD). Nota
O comando date pode ser usado para calcular uma data no futuro. A opção -u informa a hora em UTC.
[user01@host ~]$ date -d “+45 days” -u Thu May 23 17:01:20 UTC 2019
Edite os itens de configuração de vencimento da senha no arquivo /etc/login.defs para definir as políticas padrão de vencimento de senha. O PASS_MAX_DAYS define a idade máxima padrão da senha. O PASS_MIN_DAYS define a idade mínima padrão da senha. O PASS_WARN_AGE define o período de aviso padrão da senha. Qualquer alteração nas políticas de vencimento de senha padrão entrará em vigor apenas para novos usuários. Os usuários existentes continuarão usando as configurações antigas de vencimento de senha, em vez de usar as configurações novas. Restrição de acesso
Você pode usar o comando chage para definir as datas de vencimento da conta. Quando uma data for atingida, o usuário não poderá fazer login no sistema interativamente. O comando usermod pode bloquear uma conta com a opção -L.
[user01@host ~]$ sudo usermod -L user03 [user01@host ~]$ su - user03 Password: redhat su: Authentication failure
Se um usuário deixar a empresa, o administrador poderá bloquear e expirar uma conta com um único comando usermod. A data deverá ser fornecida como o número de dias desde 1970-01-01 ou no formato AAAA-MM-DD.
[user01@host ~]$ sudo usermod -L -e 2019-10-05 user03
O comando usermod anterior usa a opção -e para definir a data de vencimento da conta para a conta de usuário especificada. A opção -L bloqueia a senha do usuário.
O bloqueio da conta impede que o usuário faça a autenticação com senha no sistema. É o método recomendado para evitar o acesso a uma conta por um funcionário que tenha saído da empresa. Se o funcionário retornar, a conta poderá posteriormente ser desbloqueada com usermod -U. Se a conta também tiver expirado, certifique-se de alterar também a data de vencimento.
O shell nologin
O shell nologin funciona como um shell de substituição para as contas de usuário que não pretendem fazer login interativamente no sistema. Do ponto de vista da segurança, é inteligente liberar uma conta de fazer login no sistema quando a conta não exige login. Por exemplo, um servidor de e-mail pode exigir uma conta para armazenar mensagens de e-mail e uma senha para o usuário autenticar com um cliente de e-mail usado para obter mensagens. Esse usuário não precisa fazer o login diretamente no sistema.
Uma solução comum para essa situação é definir o shell de login do usuário como /sbin/nologin. Se o usuário tentar fazer login no sistema diretamente, o shell nologin fecha a conexão.
[user01@host ~]$ usermod -s /sbin/nologin user03 [user01@host ~]$ su - user03 Last login: Wed Feb 6 17:03:06 IST 2019 on pts/0 This account is currently not available.
Importante
O shell nologin impede o uso interativo do sistema, mas não evita todo o acesso. Os usuários poderão ainda ser capazes de autenticar e enviar ou receber arquivos através de aplicativos, como aplicativos web, programas de transferência de arquivos ou leitores de e-mail se usarem a senha para autenticação do usuário.
Capítulo 7. Controle de acesso a arquivos
Interpretação das permissões do sistema de arquivos Linux
Objetivos
Depois de concluir esta seção, você deverá ser capaz de listar as permissões do sistema de arquivos em arquivos e diretórios e interpretar o efeito dessas permissões no acesso de usuários e grupos. Permissões do sistema de arquivos Linux
As permissões de arquivo controlam o acesso aos arquivos. As permissões de arquivos Linux são simples, mas flexíveis, fáceis de compreender e aplicar, sendo ainda capazes de lidar facilmente com a maioria dos casos normais de permissão.
Os arquivos possuem três categorias de usuário às quais as permissões se aplicam. O arquivo é de propriedade de um usuário, normalmente aquele que o criou. O arquivo também é de propriedade de um único grupo, geralmente o grupo primário do usuário que criou o arquivo, mas isso pode ser alterado. Diferentes permissões podem ser definidas para o usuário proprietário, o grupo proprietário e todos os outros usuários do sistema que não sejam nem o usuário, nem o grupo proprietário.
As permissões mais específicas têm prioridade. As permissões de usuário substituem as permissões de grupo, que substituem outras permissões.
Em Figura 7.1: Exemplo de associação ao grupo para facilitar a colaboração, joshua é membro do grupos joshua e web, e allison é membro de allison, wheel e web. Quando joshua e allison precisarem colaborar, os arquivos deverão ser associados ao grupo web, e as permissões de grupo deverão permitir o acesso desejado.
usersandgroups.png
Três categorias de permissões se aplicam: leitura, gravação e execução. A tabela a seguir explica como essas permissões afetam o acesso a arquivos e diretórios.
Tabela 7.1. Efeitos das permissões em arquivos e diretórios
regras_permission.png
Os usuários normalmente têm as permissões de leitura e execução em diretórios somente leitura para que possam listar o diretório e tenham total acesso somente leitura ao conteúdo dele. Se um usuário só tiver acesso de leitura em um diretório, os nomes dos arquivos nele poderão ser listados, mas nenhuma outra informação, inclusive permissões e horas/datas de alteração, estará disponível, e eles não poderão ser acessados. Se um usuário tiver apenas acesso de execução em um diretório, ele não poderá listar os nomes de arquivo no diretório. Se ele souber o nome de um arquivo que tem permissão para ler, poderá acessar o conteúdo desse arquivo de fora do diretório especificando explicitamente o nome do arquivo relativo.
Um arquivo pode ser apagado por qualquer pessoa que seja proprietária ou tenha permissão de gravação no diretório no qual o arquivo reside, independentemente da propriedade ou das permissões do próprio arquivo. Isso pode ser substituído por uma permissão especial, o sticky bit, que será discutida mais adiante neste capítulo.
Nota
As permissões de arquivo do Linux funcionam de maneira diferente do sistema de permissões usado pelo sistema de arquivos NTFS para Microsoft Windows.
No Linux, as permissões se aplicam apenas ao arquivo ou diretório no qual elas estão definidas. Ou seja, as permissões em um diretório não são herdadas automaticamente pelos subdiretórios e arquivos dentro deles. No entanto, as permissões em um diretório podem bloquear o acesso ao conteúdo do diretório, dependendo de como elas são restritivas.
A permissão read em um diretório do Linux é mais ou menos equivalente a Listar conteúdo da pasta no Windows.
A permissão write em um diretório do Linux é equivalente a Modificar no Windows; ela pressupõe a capacidade de excluir arquivos e subdiretórios. No Linux, se write e sticky bit estiverem definidos em um diretório, somente o proprietário do arquivo ou do subdiretório poderá excluí-lo, o que é semelhante ao comportamento da permissão Gravar no Windows.
O usuário root do Linux tem o equivalente à permissão Controle total do Windows em todos os arquivos. No entanto, o root ainda pode ter seu acesso restrito pela política SELinux do sistema usando contextos de segurança do processo e do arquivo. A SELinux será discutida em um dos próximos cursos.
Exibição de permissões e da propriedade de arquivos e diretórios
A opção -l do comando ls mostra informações mais detalhadas sobre permissões e propriedade:
[user@host~]$ ls -l test -rw-rw-r–. 1 student student 0 Feb 8 17:36 test
Use a opção -d para mostrar informações detalhadas sobre um diretório em si, e não seu conteúdo.
[user@host ~]$ ls -ld /home drwxr-xr-x. 5 root root 4096 Jan 31 22:00 /home
O primeiro caractere da listagem longa é o tipo de arquivo, interpretado assim:
- é um arquivo regular.
d é um diretório
eu é um link simbólico.
Outros caracteres representam dispositivos de hardware (b e c) ou outros arquivos com fins especiais (p e s).
Os próximos nove caracteres são as permissões de arquivo. Eles estão em três conjuntos de três caracteres: permissões que se aplicam ao usuário proprietário do arquivo, ao grupo proprietário do arquivo e todos os outros usuários. Se o conjunto exibir rwx, essa categoria tem as três permissões, ler, gravar e executar. Se uma letra foi substituída por -, essa categoria não tem essa permissão.
Após a contagem de links, o primeiro nome especifica o usuário proprietário do arquivo e o segundo nome, o grupo proprietário do arquivo.
Então, no exemplo acima, as permissões para o usuário student são especificados pelo primeiro conjunto de três caracteres. O usuário student tem permissões de leitura e gravação no test, mas não de execução.
O grupo student é especificado pelo segundo conjunto de três caracteres: ele também tem permissões de leitura e gravação no test, mas não de execução.
As permissões de qualquer outro usuário são especificadas pelo terceiro conjunto de três caracteres: eles só têm permissão de leitura no test.
O conjunto de permissões que vale é o mais específico. Então, se o usuário student tiver permissões diferentes do grupo student, e o usuário student também for um membro desse grupo, as permissões de usuário serão as aplicadas.
Exemplos de efeitos de permissão
Os exemplos a seguir ajudarão a ilustrar como as permissões de arquivo interagem. Para esses exemplos, temos quatro usuários com as seguintes associações a grupos:
exemplos_permisson.png
Esses usuários estarão trabalhando com arquivos no diretório dir. Essa é uma listagem longa dos arquivos nesse diretório:
[database1@host dir]$ ls -la total 24 drwxrwxr-x. 2 database1 consultant1 4096 Apr 4 10:23 . drwxr-xr-x. 10 root root 4096 Apr 1 17:34 .. -rw-rw-r–. 1 operator1 operator1 1024 Apr 4 11:02 lfile1 -rw-r–rw-. 1 operator1 consultant1 3144 Apr 4 11:02 lfile2 -rw-rw-r–. 1 database1 consultant1 10234 Apr 4 10:14 rfile1 -rw-r—–. 1 database1 consultant1 2048 Apr 4 10:18 rfile2
A opção -a mostra as permissões de arquivos ocultos, incluindo os arquivos especiais usados para representar o diretório e seu pai. Nesse exemplo, . reflete as permissões de dir em si e .. as permissões do diretório pai.
Quais são as permissões de rfile1? O usuário proprietário do arquivo (database1) tem permissões de leitura e gravação, mas não de execução. O grupo proprietário do arquivo (consultant1) tem permissões de leitura e gravação, mas não de execução. Todos os outros usuários têm permissão de leitura, mas não de gravação ou execução.
A seguinte tabela explora alguns dos efeitos desse conjunto de permissões para esses usuários:
table_p1.png
Gerenciamento de permissões do sistema de arquivos a partir da linha de comando
Objetivos
Depois de concluir esta seção, você deverá ser capaz de alterar as permissões e as propriedades dos arquivos usando ferramentas de linha de comando. Alteração de permissões de arquivo e diretório
O comando usado para alterar permissões da linha de comando é chmod, o que significa “change mode”, alterar modo (as permissões também são chamadas de modo de um arquivo). O comando chmod assume uma instrução de permissão seguida por uma lista de arquivos ou diretórios a serem alterados. A instrução de permissão pode ser emitida simbolicamente (pelo método simbólico) ou numericamente (pelo método numérico).
Alteração de permissões com o método simbólico
chmod WhoWhatWhich file|directory
Who é u, g, o, a (referente a usuário, grupo, outros, todos)
What é +, -, = (referente a adição, remoção, definição)
Which é r, w, x (referente a leitura, gravação, execução)
O método simbólico de alterar permissões de arquivo usa letras para representar os diferentes grupos de permissões: u para usuário, g para grupo, o para outro e a para todos.
Com o método simbólico, não é necessário definir um novo grupo de permissões. Em vez disso, você pode alterar uma ou mais permissões existentes. Use + ou - para adicionar ou remover permissões, respectivamente, ou use = para substituir o conjunto inteiro por um grupo de permissões.
As permissões em si são representadas por uma única letra: r para leitura, w para gravação e x para execução. Quando chmod é usado para alterar as permissões com o método simbólico, usar um X maiúsculo como sinalizador de permissão somente adicionará a permissão de execução se o arquivo for um diretório ou já tiver a execução definida para usuário, grupo ou outro. Nota
O comando chmod é compatível com a opção -R para definir de maneira recursiva as permissões nos arquivos em uma árvore de diretórios inteira. Quando utilizada, a opção -R poderá ser útil para definir permissões usando a opção X. Isso permite que a permissão de execução (pesquisa) seja definida em diretórios de modo a possibilitar o acesso a seu conteúdo sem alterações de permissão na maioria dos arquivos. Entretanto, Tenha cuidado com a opção X, porque se um arquivo tiver definido um conjunto qualquer de permissões de execução, X também definirá para esse arquivo a permissão de execução especificada. Por exemplo, o comando a seguir define recursivamente o acesso de leitura e gravação em demodir e todos os seus filhos para o grupo proprietário, mas somente aplica permissões de execução de grupo a diretórios e arquivos que já têm a execução definida para usuário, grupo ou outro.
[root@host opt]# chmod -R g+rwX demodir
Exemplos
Remova a permissão de leitura e gravação para grupo e outro no file1:
[user@host ~]$ chmod go-rw file1
Adicione permissão de execução para todos no file2:
[user@host ~]$ chmod a+x file2
Alteração de permissões com o método numérico
No exemplo abaixo, o caractere # representa um dígito.
chmod ### file|directory
Cada dígito representa permissões para um nível de acesso: user (usuário), group (grupo), other (outro).
O dígito é calculado adicionando números para cada permissão que você deseja adicionar, 4 para leitura, 2 para gravação e 1 para execução.
Usando o método numérico, as permissões são representadas por um número octal de três dígitos (ou quatro, ao configurar permissões avançadas). Um único dígito octal pode representar qualquer valor único de 0 a 7.
Na representação octal (numérica) de três dígitos, cada dígito representa um nível de acesso, da esquerda para a direita: usuário, grupo e outro. Para determinar cada dígito:
Comece com 0.
Se a permissão de leitura deve estar presente para o nível de acesso, adicione 4.
Se a permissão de gravação deve estar presente, adicione 2.
Se a permissão de execução deve estar presente, adicione 1.
Examine as permissões -rwxr-x—. Para o usuário, rwx é calculado como 4+2+1=7. Para o grupo, r-x é calculado como 4+0+1=5, e para outros usuários, — é representado com 0. Colocando esses três juntos, a representação numérica dessas permissões é 750.
Esse cálculo pode também ser realizado na direção oposta. Analise as permissões 640. Para as permissões de usuário, 6 representa leitura (4) e gravação (2), que é exibido como rw-. Para a parte do grupo, 4 inclui somente leitura (4) e é exibido como r–. O 0 para outro não concede permissões (—), então o conjunto final de permissões simbólicas para esse arquivo é -rw-r—–.
Os administradores mais experientes geralmente usam permissões simbólicas, uma vez que são mais curtas para digitar e pronunciar e, ao mesmo tempo, dão controle total sobre todas as permissões.
Exemplos
Defina permissões de leitura e gravação para o usuário e leitura para o grupo e outros no samplefile:
[user@host ~]$ chmod 644 samplefile
Defina permissões de leitura, gravação e execução para o usuário, leitura e execução para o grupo e sem permissão para outros no sampledir:
[user@host ~]$ chmod 750 sampledir
Alteração de propriedade de grupo ou usuário do diretório e arquivo
Um arquivo novo é de propriedade do usuário que o cria. Por padrão, novos arquivos têm uma propriedade de grupo que é o grupo primário do usuário que criou o arquivo. No Red Hat Enterprise Linux, o grupo primário de um usuário é normalmente um grupo privado com apenas esse usuário como um membro. Para conceder acesso a um arquivo com base em associação ao grupo, o grupo proprietário de um arquivo pode precisar ser alterado.
Somente root pode alterar o usuário proprietário de um arquivo. No entanto, a propriedade do grupo pode ser definida pelo root ou pelo proprietário do arquivo. O root pode conceder a propriedade do arquivo a qualquer grupo, mas os usuários regulares só podem conceder a propriedade se forem membros desse grupo.
A propriedade do arquivo pode ser alterada com o comando chown (alterar proprietário). Por exemplo, para conceder a propriedade do arquivo test_file ao usuário student, use o seguinte comando:
[root@host ~]# chown student test_file
chown pode ser usado com a opção -R para alterar recursivamente a propriedade de uma árvore de diretório inteira. O seguinte comando concede a propriedade de test_dir e todos os arquivos e subdiretórios contidos nele a student:
[root@host ~]# chown -R student test_dir
O comando chown também pode ser usado para alterar a propriedade do grupo de um arquivo ao preceder o nome do grupo com dois-pontos (:). Por exemplo, o seguinte comando altera a propriedade de grupo do diretório test_dir para admins:
[root@host ~]# chown :admins test_dir
O comando chown também pode ser usado para alterar o proprietário e o grupo ao mesmo tempo usando a sintaxe owner:group. Por exemplo, para alterar a propriedade de test_dir para visitor e o grupo para guests, use o seguinte comando:
[root@host ~]# chown visitor:guests test_dir
Em vez de usar chown, alguns usuários alteram a propriedade do grupo usando o comando chgrp. Esse comando funciona como chown, mas é usado apenas para alterar a propriedade do grupo e os dois-pontos (:) antes do nome do grupo não são necessários. Importante
Você pode encontrar exemplos de comandos chown usando uma sintaxe alternativa que separa proprietário e grupo com um ponto em vez de dois-pontos:
[root@host ~]# chown owner.group filename
Você não deve usar essa sintaxe. Sempre use dois-pontos.
O ponto é um caractere válido em um nome de usuário, mas dois-pontos não é. Se o usuário enoch.root , o usuário enoch e o grupo root existirem no sistema, o resultado de chown enoch.root filename será ter filename como proprietário o usuário enoch.root. Talvez você esteja tentando definir a propriedade do arquivo para o usuário enoch e o grupo root. Isso pode ser confuso.
Se você sempre usar a sintaxe de dois-pontos chown ao definir o usuário e grupo ao mesmo tempo, os resultados serão sempre fáceis de prever.
Gerenciamento de permissões padrão e acesso aos arquivos
Objetivos
Depois de concluir esta seção, os alunos deverão ser capazes de:
Controlar as permissões padrão de novos arquivos criados pelos usuários.
Explicar o efeito de permissões especiais.
Usar permissões especiais e permissões padrão para definir o proprietário do grupo de arquivos criado em um diretório específico.
Permissões especiais
As permissões especiais constituem um quarto tipo de permissão além dos tipos básicos usuário, grupo e outros. Como o nome indica, essas permissões fornecem recursos relacionados a acesso além do que os tipos básicos de permissão permitem. Esta seção detalha o impacto das permissões especiais, resumidas na tabela abaixo.
Tabela 7.2. Efeitos das permissões especiais em arquivos e diretórios
permissoes_p3.png
A permissão setuid em um arquivo executável significa que os comandos são executados como o usuário que é proprietário desse arquivo, e não o usuário que executou o comando. Um exemplo é o comando passwd:
[user@host ~]$ ls -l /usr/bin/passwd -rwsr-xr-x. 1 root root 35504 Jul 16 2010 /usr/bin/passwd
Em uma listagem longa, você consegue identificar as permissões do setuid por uma letra minúscula s onde você normalmente esperaria que houvesse um x (o proprietário executa permissões). Se o proprietário não tiver permissões de execução, isso é substituído por uma letra S maiúscula.
A permissão especial setgid em um diretório significa que os arquivos criados no diretório herdam a propriedade do grupo do diretório em vez de herdá-la do usuário que o criou. Isso é frequentemente usado em diretórios colaborativos de grupo para alterar de maneira automática um arquivo do grupo privado padrão para o grupo compartilhado, ou se os arquivos em um diretório precisarem sempre ser de propriedade de um grupo específico. Um exemplo disso é o diretório /run/log/journal:
[user@host ~]$ ls -ld /run/log/journal drwxr-sr-x. 3 root systemd-journal 60 May 18 09:15 /run/log/journal
Se setgid estiver definido em um arquivo executável, os comandos são executados como o grupo ao qual o arquivo pertence, e não como o usuário que executou o comando, de maneira semelhante ao setuid. Um exemplo é o comando locate:
[user@host ~]$ ls -ld /usr/bin/locate -rwx–s–x. 1 root slocate 47128 Aug 12 17:17 /usr/bin/locate
Em uma listagem longa, você consegue identificar as permissões do setgid por uma letra minúscula s onde você normalmente esperaria que houvesse um x (o grupo executa permissões). Se o grupo não tiver permissões de execução, ela é substituída por uma letra S maiúscula.
Por fim, o sticky bit para um diretório define uma restrição especial na exclusão de arquivos. Apenas o proprietário do arquivo (e o root) consegue excluir arquivos dentro do diretório. Um exemplo é o /tmp:
[user@host ~]$ ls -ld /tmp drwxrwxrwt. 39 root root 4096 Feb 8 20:52 /tmp
Em uma listagem longa, você consegue identificar as permissões do sticky por uma letra minúscula t onde você normalmente esperaria que houvesse um x (outros executam permissões). Se outros não tiverem permissões de execução, ela é substituída por uma letra T maiúscula.
Definição de permissões especiais
Simbolicamente: setuid = u+s ; setgid = g+s; sticky = o+t
Numericamente (o quarto dígito da direita para a esquerda): setuid = 4; setgid = 2; sticky = 1
Exemplos
Adicione o bit setgid no directory:
[user@host ~]# chmod g+s directory
Defina o bit setgid e adicione permissões de leitura/gravação/execução ao usuário e grupo, sem acesso para outros, em directory:
[user@host ~]# chmod 2770 directory
Permissões de arquivo padrão
Quando você cria um novo arquivo ou diretório, ele recebe permissões iniciais. Há duas coisas que afetam essas permissões iniciais. A primeira é se você está criando um arquivo regular ou um diretório. A segunda é o umask atual.
Se você criar um novo diretório, o sistema operacional iniciará atribuindo a ele permissões octal 0777 (drwxrwxrwx). Se você criar um novo arquivo regular, o sistema operacional atribui a ele permissões octal 0666 (-rw-rw-rw-). Você sempre precisa incluir explicitamente a permissão de execução em um arquivo regular. Isso dificulta que um invasor comprometa um serviço de rede para criar um novo arquivo e executá-lo imediatamente como um programa.
No entanto, a sessão de shell também definirá umask para restringir ainda mais as permissões definidas inicialmente. Esse é um bitmask octal usado para limpar as permissões de novos arquivos e diretórios criados pelo processo. Se um bit for definido no umask, a permissão correspondente será desmarcada nos novos arquivos. Por exemplo, o umask 0002, limpa o bit de gravação para outros usuários. Os zeros à esquerda indicam que as permissões especial, de usuário e de grupo não são limpas. O umask de 0077 limpa todo o grupo e outras permissões de arquivos recentemente criados.
O comando umask sem argumentos exibirá o valor atual do umask do shell:
[user@host ~]$ umask 0002
Use o comando umask com apenas um argumento numérico para alterar o umask do shell atual. O argumento numérico deve ser um valor octal correspondente ao novo valor de umask. Você pode omitir zeros à esquerda no umask.
Os valores de umask padrão do sistema para usuários do shell Bash estão definidos nos arquivos /etc/profile ou /etc/bashrc. Os usuários podem substituir os padrões do sistema em seus arquivos .bash_profile ou .bashrc nos diretórios pessoais.
Exemplo de umask
O exemplo a seguir explica como o umask afeta as permissões de arquivos e diretórios. Observe as permissões padrão do umask para os arquivos e diretórios no shell atual. O proprietário e o grupo têm permissões de leitura e gravação nos arquivos e outros estão configurados para leitura. O proprietário e o grupo têm permissões de leitura, gravação e execução nos diretórios. A única permissão para outros é de leitura.
[user@host ~]$ umask 0002 [user@host ~]$ touch default [user@host ~]$ ls -l default.txt -rw-rw-r–. 1 user user 0 May 9 01:54 default.txt [user@host ~]$ mkdir default [user@host ~]$ ls -ld default drwxrwxr-x. 2 user user 0 May 9 01:54 default
Definindo o valor umask como 0, as permissões de arquivo para outras alterações são de leitura a leitura e gravação. As permissões do diretório para outras alterações de leitura e execução a leitura, gravação e execução.
[user@host ~]$ umask 0 [user@host ~]$ touch zero.txt [user@host ~]$ ls -l zero.txt -rw-rw-rw-. 1 user user 0 May 9 01:54 zero.txt [user@host ~]$ mkdir zero [user@host ~]$ ls -ld zero drwxrwxrwx. 2 user user 0 May 9 01:54 zero
Para mascarar todas as permissões de arquivo e diretório para outros, defina o valor umask como 007.
[user@host ~]$ umask 007 [user@host ~]$ touch seven.txt [user@host ~]$ ls -l seven.txt -rw-rw—-. 1 user user 0 May 9 01:55 seven.txt [user@host ~]$ mkdir seven [user@host ~]$ ls -ld seven drwxrwx—. 2 user user 0 May 9 01:54 seven
Um umask com o valor de 027 garante que os novos arquivos tenham permissões de leitura e gravação para usuário e permissão de leitura para grupo. Novos diretórios têm acesso de leitura e gravação para grupo e nenhuma permissão para outros.
[user@host ~]$ umask 027 [user@host ~]$ touch two-seven.txt [user@host ~]$ ls -l two-seven.txt -rw-r—–. 1 user user 0 May 9 01:55 two-seven.txt [user@host ~]$ mkdir two-seven [user@host ~]$ ls -ld two-seven drwxr-x—. 2 user user 0 May 9 01:54 two-seven
O umask padrão para usuários é definido pelos scripts de inicialização do shell. Por padrão, se a UID da sua conta for 200 ou mais e seu nome de usuário e nome do grupo principal forem os mesmos, será atribuído a você umask de 002. Caso contrário, seu umask será 022.
Como root, você pode alterar isso adicionando um script de inicialização do shell chamado /etc/profile.d/local-umask.sh que se parece com a saída deste exemplo:
[root@host ~]# cat /etc/profile.d/local-umask.sh
Overrides default umask configuration
if [ $UID -gt 199 ] && [ “id -gn” = “id -un” ]; then
umask 007
else
umask 022
fi
O exemplo anterior configurará o umask como 007 para usuários com uma UID maior que 199 e com um nome de usuário e um nome de grupo primário correspondentes e como 022 para todos os demais. Se você apenas quisesse configurar o umask de todos como 022, você poderia criar esse arquivo apenas com o seguinte conteúdo:
Overrides default umask configuration
umask 022
Para garantir que as alterações globais de umask entrem em vigor, você deve fazer o logout do shell e fazer login novamente. Até lá, o umask configurado no shell atual ainda estará em vigor.
Capítulo 8. Monitoramento e gerenciamento de processos do Linux
Listagem de processos
Objetivos
Depois de concluir esta seção, você deverá ser capaz de obter informações sobre programas em execução em um sistema para determinar o status, o uso de recursos e a propriedade deles para poder controlá-los. Definição de um processo
Um processo é uma instância em execução de um programa executável iniciado. Um processo consiste em:
Um espaço de endereço de memória alocada
Propriedades de segurança, incluindo credenciais do proprietário e privilégios
Um ou mais threads de execução do código do programa
Estado do processo
O ambiente de um processo inclui:
Variáveis locais e globais
Um contexto de agendamento atual
Recursos alocados do sistema, como descritores de arquivo e portas de rede
Um processo existente (pai) duplica seu próprio espaço de endereços (fork) para criar uma nova estrutura de processo (filho). Cada novo processo recebe uma única ID de processo (PID) para rastreamento e segurança. A PID e a ID do processo pai (PPID) são elementos do novo ambiente de processo. Qualquer processo pode criar um processo filho. Todos os processos são descendentes do primeiro processo do sistema, systemd em um Red Hat Enterprise Linux 8 system).
lifecycle.png
Por meio da rotina fork, um processo filho herda as identidades de segurança, os descritores de arquivo atuais e anteriores, os privilégios de porta e de recurso, as variáveis de ambiente e o código do programa. Um processo filho pode então realizar o exec de seu próprio código do programa. Normalmente, um processo pai hiberna, enquanto o processo filho é executado, configurando uma solicitação (wait) a ser sinalizada quando da conclusão do filho. Ao sair, o processo filho já fechou ou descartou seus recursos e seu ambiente. O único recurso remanescente, chamado de zumbi, é uma entrada na tabela de processos. O pai, sinalizado ativo quando o filho saiu, limpa a tabela de processo da entrada do filho, liberando, assim, o último recurso do processo do filho. O processo pai continua com sua própria execução de código do programa. Descrição dos estados do processo
Em um sistema operacional multitarefa, cada CPU (ou núcleo da CPU) pode estar trabalhando em um processo em determinado ponto no tempo. À medida que um processo é executado, seus requisitos imediatos de tempo de CPU e alocação de recursos se alteram. Os processos recebem uma atribuição de state, a qual muda conforme a imposição das circunstâncias.
states.png
Os estados de processo no Linux são ilustrados no diagrama anterior e descritos na tabela a seguir.
Tabela 8.1. Estados de processo no Linux
process_linux_p1.png
Por que os estados do processo são importantes?
Ao solucionar problemas de um sistema, é importante entender como o kernel se comunica com os processos e como os processos se comunicam entre si. Na criação do processo, o sistema atribui um estado ao processo. A coluna S do comando top ou a coluna STAT do ps mostra o estado de cada processo. Em um sistema de CPU único, apenas um processo pode ser executado por vez. É possível ver vários processos com um estado de R. No entanto, nem todos eles serão executados consecutivamente, alguns deles terão o status aguardando.
[user@host ~]$ top PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 1 root 20 0 244344 13684 9024 S 0.0 0.7 0:02.46 systemd 2 root 20 0 0 0 0 S 0.0 0.0 0:00.00 kthreadd …output omitted…
[user@host ~]$ ps aux USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND …output omitted… root 2 0.0 0.0 0 0 ? S 11:57 0:00 [kthreadd] student 3448 0.0 0.2 266904 3836 pts/0 R+ 18:07 0:00 ps aux …output omitted…
O processo pode ser suspenso, interrompido, retomado, finalizado e interrompido usando sinais. Os sinais são discutidos em mais detalhes posteriormente neste capítulo. Os sinais podem ser usados por outros processos, pelo próprio kernel ou por usuários logados no sistema. Listagem de processos
O comando ps é usado para listar os processos atuais. Ele pode fornecer informações detalhadas de processo, incluindo:
A identificação de usuário (UID) que determina os privilégios de processo
A identificação de processo (PID) única
A CPU e o tempo real já utilizado
O quanto de memória o processo já alocou em vários locais
O local da saída do processo stdout, conhecido como o terminal de controle
O estado atual do processo
Importante
A versão Linux do ps dá suporte a três formatos:
Opções UNIX (POSIX), que podem ser agrupadas e devem ser antecedidas de um traço
Opções BSD, que podem ser agrupadas e não devem ser usadas com um traço
Opções extensas GNU, que são precedidas por dois traços
Por exemplo, ps -aux não é o mesmo que ps aux.
Talvez o conjunto de opções mais comum, aux, exiba todos os processos, incluindo processos sem um terminal de controle. Uma listagem longa (opções lax) oferece mais detalhes técnicos, mas pode ser exibida mais rapidamente, evitando a procura pelo nome de usuário. Uma sintaxe semelhante à do UNIX usa as opções -ef para exibir todos os processos.
[user@host ~]$ ps aux USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND root 1 0.1 0.1 51648 7504 ? Ss 17:45 0:03 /usr/lib/systemd/syst root 2 0.0 0.0 0 0 ? S 17:45 0:00 [kthreadd] root 3 0.0 0.0 0 0 ? S 17:45 0:00 [ksoftirqd/0] root 5 0.0 0.0 0 0 ? S< 17:45 0:00 [kworker/0:0H] root 7 0.0 0.0 0 0 ? S 17:45 0:00 [migration/0] …output omitted… [user@host ~]$ ps lax F UID PID PPID PRI NI VSZ RSS WCHAN STAT TTY TIME COMMAND 4 0 1 0 20 0 51648 7504 ep_pol Ss ? 0:03 /usr/lib/systemd/ 1 0 2 0 20 0 0 0 kthrea S ? 0:00 [kthreadd] 1 0 3 2 20 0 0 0 smpboo S ? 0:00 [ksoftirqd/0] 1 0 5 2 0 -20 0 0 worker S< ? 0:00 [kworker/0:0H] 1 0 7 2 -100 - 0 0 smpboo S ? 0:00 [migration/0] …output omitted… [user@host ~]$ ps -ef UID PID PPID C STIME TTY TIME CMD root 1 0 0 17:45 ? 00:00:03 /usr/lib/systemd/systemd –switched-ro root 2 0 0 17:45 ? 00:00:00 [kthreadd] root 3 2 0 17:45 ? 00:00:00 [ksoftirqd/0] root 5 2 0 17:45 ? 00:00:00 [kworker/0:0H] root 7 2 0 17:45 ? 00:00:00 [migration/0] …output omitted…
Por padrão, ps sem opções seleciona todos os processos com a mesma ID de usuário efetiva (EUID) como o usuário atual, e os quais são associados ao mesmo terminal onde ps foi invocado.
Processos entre parênteses (normalmente, na parte superior da lista) são threads do kernel agendadas.
Zumbis são listados como de saída ou extintos.
A saída de ps é exibida uma vez. Usar top para uma exibição de processo que é atualizada dinamicamente.
ps pode ser exibido no formato de árvore para que você possa exibir as relações entre os processos pai e filho.
A saída padrão é classificada por número de ID do processo. À primeira vista, isso pode parecer ordem cronológica. No entanto, o kernel reutiliza as IDs do processo, portanto, o pedido é menos estruturado do que aparece. Para classificar, use as opções -O ou --sort. A ordem de exibição é equivalente à ordem da tabela de processos do sistema, a qual utiliza novamente as linhas na tabela à medida que os processos são extintos e novos processos são criados. A saída poderá parecer cronológica, mas isso não é garantido, a menos que as opções -O ou --sort sejam usadas explicitamente.
Controle de tarefas
Objetivos
Depois de concluir esta seção, você deverá ser capaz de usar o controle de tarefa do Bash para gerenciar vários processos iniciados na mesma sessão de terminal. Descrição de tarefas e sessões
O controle de tarefas é um recurso do shell que permite a uma única instância do shell executar e gerenciar vários comandos.
Uma tarefa é associada a cada pipeline inserido em um prompt do shell. Todos os processos em um pipeline fazem parte da tarefa e são membros do mesmo grupo de processos. Se apenas um comando for inserido em um prompt do shell, poderá ser considerado um “pipeline” mínimo de um comando, criando uma tarefa com apenas um membro.
Somente uma tarefa por vez pode ler a entrada e os sinais gerados pelo teclado em uma janela de terminal. Os processos que fazem parte dessa tarefa são processos de primeiro plano do terminal de controle.
Um processo em segundo plano no terminal de controle é membro de qualquer outra tarefa associada ao terminal. Processos em segundo plano de um terminal não podem ler a entrada ou receber interrupções geradas pelo teclado a partir do terminal, mas podem ser gravados no terminal. Uma tarefa em segundo plano pode estar interrompida (suspensa) ou estar em execução. Se uma tarefa executada em segundo plano tentar ler a partir do terminal, será suspensa automaticamente.
Cada terminal é sua própria sessão, e pode ter um processo em primeiro plano e qualquer número de processos em segundo plano independentes. Uma tarefa faz parte de exatamente uma sessão, que pertence a seu terminal de controle.
O comando psmostra o nome de dispositivo do terminal de controle de um processo na coluna TTY. Alguns processos, como daemons do sistema, são iniciados pelo sistema, e não a partir de um prompt do shell. Esses processos não têm um terminal de controle, não são membros de uma tarefa e não podem ser colocados em primeiro plano. O comando ps exibe um ponto de interrogação (?) na coluna TTY para esses processos. Execução de tarefas em segundo plano
É possível iniciar qualquer comando ou pipeline em segundo plano acrescentando um “e” comercial (&) no final da linha de comando. O shell Bash exibe um número de tarefa (único para a sessão) e a PID do novo processo filho. O shell não aguarda o processo filho ser concluído; em vez disso, ele exibe o prompt do shell.
[user@host ~]$ sleep 10000 & [1] 5947 [user@host ~]$
Nota
Quando uma linha de comando que contém um pipe é enviada para o segundo plano usando um “e” comercial, a PID do último comando no pipeline é usada como saída. Todos os processos no pipeline ainda serão membros dessa tarefa.
[user@host ~]$ example_command | sort | mail -s “Sort output” & [1] 5998
Você pode exibir a lista de tarefas que o Bash está rastreando para uma sessão específica com o comando jobs.
[user@host ~]$ jobs [1]+ Running sleep 10000 & [user@host ~]$
É possível trazer uma tarefa em segundo plano para o primeiro plano usando o comando fg com sua ID de tarefa (%número da tarefa).
[user@host ~]$ fg %1 sleep 10000
No exemplo anterior, o comando sleep agora é executado em primeiro plano no terminal de controle. O shell volta a ser suspenso, aguardando a saída desse processo filho.
Para enviar um processo em primeiro plano ao segundo plano, primeiro pressione a solicitação de suspensão gerada pelo teclado (Ctrl+z) no terminal.
sleep 10000 ^Z [1]+ Stopped sleep 10000 [user@host ~]$
A tarefa é imediatamente colocada em segundo plano e suspensa.
O comando ps j exibe informações relativas às tarefas. A PID é a única ID do processo do processo. A PPID é a PID do processo pai deste processo, o processo que o iniciou (ramificou). A PGID é a PID do líder do grupo de processo, normalmente o primeiro processo no pipeline da tarefa. A SID é a PID do líder da sessão, o que para uma tarefa normalmente é o shell interativo em execução no terminal de controle. Como o comando sleep agora está suspenso, seu estado de processo é T.
[user@host ~]$ ps j PPID PID PGID SID TTY TPGID STAT UID TIME COMMAND 2764 2768 2768 2768 pts/0 6377 Ss 1000 0:00 /bin/bash 2768 5947 5947 2768 pts/0 6377 T 1000 0:00 sleep 10000 2768 6377 6377 2768 pts/0 6377 R+ 1000 0:00 ps j
Para reiniciar o processo em segundo plano, use o comando bg com a mesma ID de tarefa.
[user@host ~]$ bg %1 [1]+ sleep 10000 &
O shell avisará um usuário que tentar sair de uma janela de terminal (sessão) com tarefas suspensas. Se o usuário tentar sair de novo imediatamente, as tarefas suspensas serão canceladas. Nota
Observe o sinal de + após o [1] nos exemplos acima. O sinal + indica que essa tarefa é o trabalho padrão atual. Ou seja, se for usado um comando que espera um argumento %job number e um número de trabalho não for fornecido, a ação é executada na tarefa com o indicador +.
Encerramento de processos
Objetivos
Depois de concluir esta seção, você deverá ser capaz de:
Usar os comandos para encerrar os processos e se comunicar com eles.
Definir as características de um processo daemon.
Encerrar sessões de usuário e processos.
Controle de processos com o uso de sinais
Um sinal é uma interrupção de software entregue a um processo. Os sinais relatam eventos a um programa em execução. Os eventos que geram um sinal podem ser um erro, um evento externo (uma solicitação de E/S ou um temporizador expirado) ou um uso explícito de um comando de envio de sinal ou de uma sequência de teclado.
A tabela abaixo lista os principais sinais usados pelos administradores do sistema para o gerenciamento dos processos de rotina. Consulte os sinais através de seus nomes abreviados (HUP) ou de seus nomes próprios (SIGHUP).
Tabela 8.2. Sinais de gerenciamento de processo fundamentais
process_fundamentals.png
Nota
Os números de sinalização variam em diferentes plataformas de hardware Linux, mas os nomes de sinalização e seus significados são padronizados. Para usar o comando, aconselha-se utilizar os nomes de sinalização em vez dos números. Os números discutidos nesta seção são para sistemas x86_64.
Cada sinal tem uma ação padrão, geralmente uma das seguintes:
Term - faz com que um programa seja encerrado (saia) de imediato.
Core - faz com que um programa salve uma imagem de memória (despejo de memória) e, em seguida, seja encerrado.
Stop - faz com que um programa pare de ser executado (seja suspenso) e espere para ser continuado (retomado).
Os programas podem ser preparados para reagir a sinais de evento esperados pela implementação de rotinas de manipulação para ignorar, substituir ou estender uma ação padrão do sinal.
Comandos para enviar sinais por solicitação explícita
Você sinaliza o processo em primeiro plano atual digitando uma sequência de controles do teclado para suspender (Ctrl+z), encerrar (Ctrl+c) ou despejar a memória (Ctrl+) do processo. No entanto, você usará comandos de envio de sinal para enviar sinais a um processo em segundo plano ou a processos em uma sessão diferente.
Sinais podem ser especificados como opções pelo nome (por exemplo, -HUP ou -SIGHUP) ou por número (o -1 relacionado). Os usuários podem encerrar seus próprios processos, mas privilégios de root são necessários para terminar processos de propriedade de outros.
O comando kill envia um sinal a um processo pelo número da PID. Apesar de seu nome, o comando kill pode ser usado para enviar um sinal, não somente para encerrar programas. Você pode usar o comando kill -l para listar os nomes e números de todos os sinais disponíveis.
[user@host ~]$ kill -l
- SIGHUP 2) SIGINT 3) SIGQUIT 4) SIGILL 5) SIGTRAP
- SIGABRT 7) SIGBUS 8) SIGFPE 9) SIGKILL 10) SIGUSR1
- SIGSEGV 12) SIGUSR2 13) SIGPIPE 14) SIGALRM 15) SIGTERM
- SIGSTKFLT 17) SIGCHLD 18) SIGCONT 19) SIGSTOP 20) SIGTSTP …output omitted… [user@host ~]$ ps aux | grep job 5194 0.0 0.1 222448 2980 pts/1 S 16:39 0:00 /bin/bash /home/user/bin/control job1 5199 0.0 0.1 222448 3132 pts/1 S 16:39 0:00 /bin/bash /home/user/bin/control job2 5205 0.0 0.1 222448 3124 pts/1 S 16:39 0:00 /bin/bash /home/user/bin/control job3 5430 0.0 0.0 221860 1096 pts/1 S+ 16:41 0:00 grep –color=auto job [user@host ~]$ kill 5194 [user@host ~]$ ps aux | grep job user 5199 0.0 0.1 222448 3132 pts/1 S 16:39 0:00 /bin/bash /home/user/bin/control job2 user 5205 0.0 0.1 222448 3124 pts/1 S 16:39 0:00 /bin/bash /home/user/bin/control job3 user 5783 0.0 0.0 221860 964 pts/1 S+ 16:43 0:00 grep –color=auto job [1] Terminated control job1 [user@host ~]$ kill -9 5199 [user@host ~]$ ps aux | grep job user 5205 0.0 0.1 222448 3124 pts/1 S 16:39 0:00 /bin/bash /home/user/bin/control job3 user 5930 0.0 0.0 221860 1048 pts/1 S+ 16:44 0:00 grep –color=auto job [2]- Killed control job2 [user@host ~]$ kill -SIGTERM 5205 user 5986 0.0 0.0 221860 1048 pts/1 S+ 16:45 0:00 grep –color=auto job [3]+ Terminated control job3
O comando killall pode sinalizar vários processos, com base no nome do comando.
[user@host ~]$ ps aux | grep job 5194 0.0 0.1 222448 2980 pts/1 S 16:39 0:00 /bin/bash /home/user/bin/control job1 5199 0.0 0.1 222448 3132 pts/1 S 16:39 0:00 /bin/bash /home/user/bin/control job2 5205 0.0 0.1 222448 3124 pts/1 S 16:39 0:00 /bin/bash /home/user/bin/control job3 5430 0.0 0.0 221860 1096 pts/1 S+ 16:41 0:00 grep –color=auto job [user@host ~]$ killall control [1] Terminated control job1 [2]- Terminated control job2 [3]+ Terminated control job3 [user@host ~]$
Use pkill para enviar um sinal para um ou mais processos que correspondam aos critérios de seleção. Os critérios de seleção podem ser um nome de comando, um processo pertencente a um usuário específico ou todos os processos do sistema. O comando pkill inclui critérios de seleção avançados:
Command - Processos com um nome de comando correspondente ao padrão.
UID - Processos de propriedade de uma conta de usuário Linux, efetiva ou real.
GID - Processos de propriedade de uma conta de grupo Linux, efetiva ou real.
Parent - Processos filhos de um determinado processo pai.
Terminal - Processos em execução em um terminal de controle específico.
[user@host ~]$ ps aux | grep pkill user 5992 0.0 0.1 222448 3040 pts/1 S 16:59 0:00 /bin/bash /home/user/bin/control pkill1 user 5996 0.0 0.1 222448 3048 pts/1 S 16:59 0:00 /bin/bash /home/user/bin/control pkill2 user 6004 0.0 0.1 222448 3048 pts/1 S 16:59 0:00 /bin/bash /home/user/bin/control pkill3 [user@host ~]$ pkill control [1] Terminated control pkill1 [2]- Terminated control pkill2 [user@host ~]$ ps aux | grep pkill user 6219 0.0 0.0 221860 1052 pts/1 S+ 17:00 0:00 grep –color=auto pkill [3]+ Terminated control pkill3 [user@host ~]$ ps aux | grep test user 6281 0.0 0.1 222448 3012 pts/1 S 17:04 0:00 /bin/bash /home/user/bin/control test1 user 6285 0.0 0.1 222448 3128 pts/1 S 17:04 0:00 /bin/bash /home/user/bin/control test2 user 6292 0.0 0.1 222448 3064 pts/1 S 17:04 0:00 /bin/bash /home/user/bin/control test3 user 6318 0.0 0.0 221860 1080 pts/1 S+ 17:04 0:00 grep –color=auto test [user@host ~]$ pkill -U user [user@host ~]$ ps aux | grep test user 6870 0.0 0.0 221860 1048 pts/0 S+ 17:07 0:00 grep –color=auto test [user@host ~]$
Fazer o logout de usuários administrativamente
Talvez seja necessário desconectar outros usuários por vários motivos. Para citar algumas das diversas possibilidades: o usuário cometeu uma violação de segurança; o usuário pode ter usado recursos em excesso; o usuário pode ter um sistema que não responde; ou o usuário tem acesso inadequado aos materiais. Nesses casos, talvez seja necessário encerrar administrativamente sua sessão usando sinais.
Para fazer logoff de um usuário, primeiro identifique a sessão de login a ser finalizada. Use o comando w para listar logins de usuários e processos em execução atuais. Observe as colunas TTY e FROM para determinar as sessões a serem fechadas.
Todas as sessões de login do usuário estão associadas a um dispositivo de terminal (TTY). Se o nome do dispositivo estiver no formato pts/N, ele é um pseudo-terminal associado a uma janela de terminal gráfica ou sessão de login remoto. Se estiver no formato ttyN, o usuário está em um console do sistema, em um console alternativo ou em outros dispositivos do terminal conectados diretamente.
[user@host ~]$ w 12:43:06 up 27 min, 5 users, load average: 0.03, 0.17, 0.66 USER TTY FROM LOGIN@ IDLE JCPU PCPU WHAT root tty2 12:26 14:58 0.04s 0.04s -bash bob tty3 12:28 14:42 0.02s 0.02s -bash user pts/1 desk.example.com 12:41 2.00s 0.03s 0.03s w [user@host ~]$
Descubra há quanto tempo um usuário está no sistema visualizando o tempo de login da sessão. Para cada sessão, os recursos da CPU consumidos por tarefas atuais, incluindo tarefas em segundo plano e processos filhos, estão na coluna JCPU. O consumo de CPU dos processos em primeiro plano atuais está na coluna PCPU.
Os processos e sessões podem ser sinalizados individualmente ou em conjunto. Para encerrar todos os processos para um usuário, use o comando pkill. Como o processo inicial em uma sessão de login (líder da sessão) é projetado para lidar com solicitações de término de sessão e para ignorar sinais de teclado não intencionais, encerrar todos os processos e shells de login de usuário requer o uso do sinal SIGKILL. Importante
O SIGKILL é normalmente usado muito rapidamente pelos administradores.
Como o sinal SIGKILL não pode ser manipulado ou ignorado, ele é sempre fatal. No entanto, ele força o término sem permitir que processos terminados abruptamente executem rotinas de autolimpeza. É recomendado o envio de SIGTERM primeiro, seguido do SIGINT e, somente se os dois falharem, tentar novamente com o SIGKILL.
Primeiro, identifique os números de PID a serem encerrados usando pgrep, que opera de modo semelhante ao pkill, inclusive usando as mesmas opções, exceto por usar processos de listas pgrep, em vez de encerrar processos.
[root@host ~]# pgrep -l -u bob 6964 bash 6998 sleep 6999 sleep 7000 sleep [root@host ~]# pkill -SIGKILL -u bob [root@host ~]# pgrep -l -u bob [root@host ~]#
Quando os processos que exigem atenção estiverem na mesma sessão de login, ele poderá ser desnecessário para encerrar todos os processos do usuário. Determine o terminal de controle para a sessão usando o comando w. Em seguida, encerre somente os processos que fazem referência à mesma ID de terminal. A menos que SIGKILL seja especificado, o líder da sessão (aqui, o shell de login Bash) lida com a solicitação de término com sucesso e sobrevive a ela, mas todos os outros processos da sessão são terminados.
[root@host ~]# pgrep -l -u bob 7391 bash 7426 sleep 7427 sleep 7428 sleep [root@host ~]# w -h -u bob bob tty3 18:37 5:04 0.03s 0.03s -bash [root@host ~]# pkill -t tty3 [root@host ~]# pgrep -l -u bob 7391 bash [root@host ~]# pkill -SIGKILL -t tty3 [root@host ~]# pgrep -l -u bob [root@host ~]#
O mesmo término seletivo de processos pode ser aplicado usando relações de processos de pai e filho. Use o comando pstree para exibir uma árvore de processo ao sistema ou a um único usuário. Use a PID do processo pai para encerrar todos os filhos que foram criados. Desta vez, o shell de login Bash pai sobrevive, porque o sinal é orientado apenas a seus processos filhos.
[root@host ~]# pstree -p bob bash(8391)─┬─sleep(8425) ├─sleep(8426) └─sleep(8427) [root@host ~]# pkill -P 8391 [root@host ~]# pgrep -l -u bob bash(8391) [root@host ~]# pkill -SIGKILL -P 8391 [root@host ~]# pgrep -l -u bob bash(8391) [root@host ~]#
Monitoramento de atividade de processo
Objetivos
Depois de concluir esta seção, você deverá ser capaz de descrever qual é a média de carga e determinar os processos responsáveis pelo uso elevado de recursos em um servidor. Descrição da média de carga
A média de carga é uma medida fornecida pelo kernel do Linux que é uma maneira simples de representar a carga do sistema percebida ao longo do tempo. Ela pode ser usada como um indicador aproximado de quantas solicitações de recursos do sistema estão pendentes e para determinar se a carga do sistema está aumentando ou diminuindo com o tempo.
A cada cinco segundos, o kernel coleta o número de carga atual, com base no número de processos em estados executáveis e ininterruptos. Esse número é acumulado e informado como uma média móvel exponencial nos últimos 1, 5 e 15 minutos.
Compreensão do cálculo da média de carga do Linux
A média de carga representa a carga do sistema percebida em determinado período de tempo. O Linux determina isso informando quantos processos estão prontos para execução em uma CPU e quantos processos estão aguardando a conclusão de E/S de disco ou rede.
O número de carga é uma média móvel do número de processos que estão prontos para execução (em estado de processo R) ou estão esperando pela conclusão de E/S (em estado de processo D).
Alguns sistemas UNIX só consideram o uso da CPU ou o comprimento da fila de execução para indicar a carga do sistema. O Linux também inclui o uso de disco ou rede porque isso pode ter um impacto tão significativo no desempenho do sistema quanto a carga da CPU. Ao experimentar médias de carga altas com atividade mínima de CPU, examine a atividade do disco e da rede.
A média de carga é uma medida aproximada de quantos processos estão atualmente aguardando que uma solicitação seja concluída antes que eles possam fazer qualquer outra coisa. A solicitação pode ser por tempo de CPU para executar o processo. Como alternativa, a solicitação pode ser para a conclusão de uma operação crítica de E/S do disco e o processo não pode ser executado na CPU até que a solicitação seja concluída, mesmo se a CPU estiver ociosa. De qualquer maneira, a carga do sistema é afetada e o sistema parece ser executado de modo mais lento porque os processos estão aguardando a execução.
Interpretação dos valores de média de carga exibidos
O comando uptime é uma maneira de exibir a média de carga atual. Ele imprime a hora atual, há quanto tempo a máquina está ativa, quantas sessões de usuário estão sendo executadas e a média de carga atual.
[user@host ~]$ uptime 15:29:03 up 14 min, 2 users, load average: 2.92, 4.48, 5.20
Os três valores para a média da carga representam a carga ao longo dos últimos 1, 5 e 15 minutos. Uma olhada rápida indica se a carga do sistema parece estar aumentando ou diminuindo.
Se a contribuição principal para a carga média for um processo aguardando a CPU, você pode calcular o valor da carga aproximado por CPU para determinar se o sistema está enfrentando esperas significativas.
O comando lscpu pode ajudar a determinar quantas CPUs um sistema possui.
No exemplo a seguir, o sistema é um sistema dual-core de soquete único com dois hyperthreads por núcleo. Basicamente, o Linux tratará isso como um sistema de quatro CPUs para fins de agendamento.
[user@host ~]$ lscpu Architecture: x86_64 CPU op-mode(s): 32-bit, 64-bit Byte Order: Little Endian CPU(s): 4 On-line CPU(s) list: 0-3 Thread(s) per core: 2 Core(s) per socket: 2 Socket(s): 1 NUMA node(s): 1 …output omitted…
Por um momento, imagine que a única contribuição para o número da carga é os processos que precisam de tempo de CPU. Em seguida, você pode dividir os valores de média de carga exibidos pelo número de CPUs lógicas no sistema. Um valor abaixo de 1 indica o uso satisfatório de recursos e tempos de espera mínimos. Um valor acima de 1 indica saturação de recursos e certo atraso de processamento.
From lscpu, the system has four logical CPUs, so divide by 4:
load average: 2.92, 4.48, 5.20
divide by number of logical CPUs: 4 4 4
—- —- —-
per-CPU load average: 0.73 1.12 1.30
This system’s load average appears to be decreasing.
With a load average of 2.92 on four CPUs, all CPUs were in use ~73% of the time.
During the last 5 minutes, the system was overloaded by ~12%.
During the last 15 minutes, the system was overloaded by ~30%.
Uma fila de CPU inativa tem um número de carga de 0. Cada processo aguardando uma CPU adiciona uma contagem de 1 ao número da carga. Se um processo estiver sendo executado em uma CPU, o número de carga será um, o recurso (a CPU) estará em uso, mas não haverá solicitações em espera. Se esse processo for executado por um minuto inteiro, sua contribuição para a média de carga de um minuto será 1.
Porém, os processos em hibernação ininterrupta para E/S crítica devido ao fato de o disco ou a rede estarem ocupados também são incluídos na contagem e aumentam a média de carga. Embora não seja uma indicação do uso da CPU, esses processos são adicionados à contagem de filas porque estão aguardando recursos e não podem ser executados em uma CPU até que os obtenham. Esse ainda é carregamento do sistema devido a limitações de recursos que estão fazendo com que os processos não sejam executados.
Até a saturação dos recursos, a média de carga permanece abaixo de 1, já que as tarefas raramente são encontradas na fila de espera. A média de carga aumenta somente quando a saturação de recursos faz com que as solicitações permaneçam na fila e sejam contadas pela rotina de cálculo de carga. Quando o uso de recursos se aproxima dos 100%, cada solicitação adicional começa a ter tempo de espera de serviço.
Várias ferramentas adicionais informam a média de carga, incluindo w e top. Monitoramento de processos em tempo real
O programa top é uma visualização dinâmica dos processos do sistema, exibindo um cabeçalho de resumo seguido de uma lista de processos ou de threads semelhante às informações de ps. Diferentemente da saída estática de ps, top é atualizado continuamente em um intervalo configurável, fornecendo capacidades de reordenamento de colunas, classificação e realce. As configurações do usuário podem ser salvas e tornadas persistentes.
As colunas de saída padrão são reconhecíveis por outras ferramentas de recursos:
A ID de processo (PID).
O nome de usuário (USER) é o proprietário do processo.
A memória virtual (VIRT) é toda a memória que o processo está usando, incluindo as definições residentes, as bibliotecas compartilhadas e as páginas de memória mapeadas ou trocadas. (Chamados de VSZ no comando ps).
A memória residente (RES) é a memória física usada pelo processo, incluindo objetos residentes compartilhados (Chamados de RSS no comando ps).
O estado de processo (S) é exibido como:
D = Hibernação ininterruptível
R = Em execução ou Executável
S = Em hibernação
T = Interrompido ou Rastreável
Z = Zumbi
O tempo de CPU (TIME) é o total do tempo de processamento desde que o processo foi iniciado. Pode ser comutado para incluir o tempo cumulativo de todos os filhos anteriores.
O nome de comando do processo (COMMAND).
Tabela 8.3. Pressionamentos de tecla fundamentais em top
process_fundamentals_a2.png
Capítulo 9. Controle de serviços e daemons
Identificação de processos do sistema iniciados automaticamente Objetivos
Depois de concluir esta seção, você deverá ser capaz de listar daemons do sistema e serviços de rede iniciados pelo serviço systemd e pelas unidades de soquete. Introdução ao systemd
O daemon systemd gerencia a inicialização para Linux, incluindo a inicialização de serviços e o gerenciamento de serviços em geral. Ele ativa os recursos do sistema, daemons do servidor e outros processos, tanto no momento da inicialização quanto em um sistema em execução.
Daemons são processos que esperam ou são executados em segundo plano realizando várias tarefas. Em geral, os daemons são iniciados automaticamente no momento do boot e continuam em execução até o desligamento ou até serem interrompidos manualmente. Por convenção, os nomes de muitos programas daemon terminam com a letra d.
Um serviço no sentido do systemd muitas vezes se refere a um ou mais daemons, mas iniciar ou parar um serviço pode fazer uma única alteração no estado do sistema, que não envolve deixar um processo daemon em execução posteriormente (chamado oneshot).
No Red Hat Enterprise Linux, o primeiro processo que inicia (PID 1) é o systemd. Alguns dos recursos fornecidos pelo systemd incluem:
Recursos de paralelização (que iniciam vários serviços de uma só vez), que aumentam a velocidade de boot de um sistema.
Inicialização de daemons conforme a necessidade sem exigir um serviço separado.
Gerenciamento automático de dependência de serviço, que pode evitar limites de tempo longos. Por exemplo, um serviço dependente de rede não tentará iniciar até que a rede esteja disponível.
Um método de rastrear processos relacionados em conjunto usando os grupos de controle do Linux.
Descrição das unidades de serviço
O systemd usa unidades para gerenciar diferentes tipos de objetos. Alguns tipos comuns de unidades estão listados abaixo:
As unidades de serviço têm uma extensão .service e representam os serviços do sistema. Esse tipo de unidade é usado para iniciar daemons acessados frequentemente, como um servidor web.
Unidades de soquete têm uma extensão .socket e representam soquetes de comunicação entre processos (IPC) que o systemd monitora. Se um cliente se conecta ao soquete, o systemd iniciará um daemon e passará a conexão para ele. Unidades de soquete são usadas para atrasar o início de um serviço no momento do boot e para iniciar sob demanda serviços usados com menos frequência.
Unidades de caminho têm uma extensão .path e são usadas para atrasar a ativação de um serviço até que ocorra uma alteração específica do sistema de arquivos. Elas são frequentemente usadas para serviços que usam diretórios de spool, tais como um sistema de impressão.
O comando systemctl é usado para gerenciar unidades. Por exemplo, exiba os tipos de unidade disponíveis com o comando systemctl -t help. Importante
Ao usar systemctl, você pode abreviar nomes de unidades, processar entradas de árvores e descrições de unidades. Unidades de serviço de listagem
Você usa o comando systemctl para explorar o estado atual do sistema. Por exemplo, o comando a seguir lista todas as unidades de serviço atualmente carregadas, paginando a saída usando less.
[root@host ~]# systemctl list-units –type=service UNIT LOAD ACTIVE SUB DESCRIPTION atd.service loaded active running Job spooling tools auditd.service loaded active running Security Auditing Service chronyd.service loaded active running NTP client/server crond.service loaded active running Command Scheduler dbus.service loaded active running D-Bus System Message Bus …output omitted…
A saída acima limita o tipo de unidade listada às unidades de serviço com a opção –type=service. A saída possui as seguintes colunas:
Colunas na saída de comando systemctl list-units
UNIT
O nome da unidade de serviço.
LOAD
Se o systemd analisou adequadamente a configuração da unidade e carregou a unidade na memória.
ACTIVE
Estado de ativação de alto nível da unidade. Essa informação indica se a unidade foi iniciada com êxito ou não.
SUB
Estado de ativação de baixo nível da unidade. Esta informação indica informações mais detalhadas sobre a unidade. A informação varia com base no tipo de unidade, estado e de que maneira a unidade é executada.
DESCRIPTION
A breve descrição da unidade.
Por padrão, o comando systemctl list-units –type=service lista apenas as unidades de serviço com estados de ativação ativo. A opção –all lista todas as unidades de serviço, independentemente dos estados de ativação. Use a opção –state= para filtrar pelos valores nos campos LOAD , ACTIVE ou SUB.
[root@host ~]# systemctl list-units –type=service –all UNIT LOAD ACTIVE SUB DESCRIPTION atd.service loaded active running Job spooling tools auditd.service loaded active running Security Auditing … auth-rpcgss-module.service loaded inactive dead Kernel Module … chronyd.service loaded active running NTP client/server cpupower.service loaded inactive dead Configure CPU power … crond.service loaded active running Command Scheduler dbus.service loaded active running D-Bus System Message Bus ● display-manager.service not-found inactive dead display-manager.service …output omitted…
O comando systemctl sem nenhum argumento lista as unidades que estão carregadas e ativas.
[root@host ~]# systemctl UNIT LOAD ACTIVE SUB DESCRIPTION proc-sys-fs-binfmt_misc.automount loaded active waiting Arbitrary… sys-devices-….device loaded active plugged Virtio network… sys-subsystem-net-devices-ens3.deviceloaded active plugged Virtio network… … -.mount loaded active mounted Root Mount boot.mount loaded active mounted /boot … systemd-ask-password-plymouth.path loaded active waiting Forward Password… systemd-ask-password-wall.path loaded active waiting Forward Password… init.scope loaded active running System and Servi… session-1.scope loaded active running Session 1 of… atd.service loaded active running Job spooling tools auditd.service loaded active running Security Auditing… chronyd.service loaded active running NTP client/server crond.service loaded active running Command Scheduler …output omitted…
O comando systemctl list-units exibe as unidades que o serviço systemd tenta analisar e carregar na memória; ele não exibe serviços instalados, mas não habilitados. Para ver o estado de todos os arquivos da unidade instalados, use o comando systemctl list-unit-files. Por exemplo:
[root@host ~]# systemctl list-unit-files –type=service UNIT FILE STATE arp-ethers.service disabled atd.service enabled auditd.service enabled auth-rpcgss-module.service static autovt@.service enabled blk-availability.service disabled …output omitted…
Na saída do comando systemctl list-units-files, entradas válidas para o campo STATE são ativadas, desativadas, estáticas e mascaradas. Exibição de estados de serviço
Visualize o status de uma unidade específica com systemctl status name.type. Se o tipo de unidade não for fornecido, systemctl mostrará o status de uma unidade de serviço, caso ela exista.
[root@host ~]# systemctl status sshd.service ● sshd.service - OpenSSH server daemon Loaded: loaded (/usr/lib/systemd/system/sshd.service; enabled; vendor preset: enabled) Active: active (running) since Thu 2019-02-14 12:07:45 IST; 7h ago Main PID: 1073 (sshd) CGroup: /system.slice/sshd.service └─1073 /usr/sbin/sshd -D …
Feb 14 11:51:39 host.example.com systemd[1]: Started OpenSSH server daemon. Feb 14 11:51:39 host.example.com sshd[1073]: Could not load host key: /et…y Feb 14 11:51:39 host.example.com sshd[1073]: Server listening on 0.0.0.0 …. Feb 14 11:51:39 host.example.com sshd[1073]: Server listening on :: port 22. Feb 14 11:53:21 host.example.com sshd[1270]: error: Could not load host k…y Feb 14 11:53:22 host.example.com sshd[1270]: Accepted password for root f…2 …output omitted…
Esse comando exibe o status atual do serviço. Os significados dos campos são:
Tabela 9.1. Informações da unidade de serviço
daemons_services_a1.png
Várias palavras-chave que indicam o estado do serviço podem ser encontradas na saída de status:
Tabela 9.2. Estados de serviço na saída de systemctl
daemons_services_a2.png
Nota
O comando systemctl status NAME substitui o comando service NAME status usado no Red Hat Enterprise Linux 6 e versões anteriores. Verificação do status de um serviço
O comando systemctl oferece métodos para verificar os estados específicos de um serviço. Por exemplo, use o seguinte comando para verificar se a unidade de serviço está active (running) no momento:
[root@host ~]# systemctl is-active sshd.service active
O comando retorna o estado da unidade de serviço, que geralmente é active ou inactive.
Execute o seguinte comando para verificar se uma unidade de serviço está habilitada para iniciar automaticamente durante a inicialização do sistema:
[root@host ~]# systemctl is-enabled sshd.service enabled
O comando retorna se a unidade de serviço estiver habilitada para iniciar no momento da inicialização, que geralmente está enabled ou disabled.
Para verificar se a unidade falhou durante a inicialização, execute o seguinte comando:
[root@host ~]# systemctl is-failed sshd.service active
O comando retorna active se estiver funcionando corretamente ou failed se tiver ocorrido um erro durante a inicialização. No caso de a unidade ser interrompida, ele retorna unknown ou inactive.
Para listar todas as unidades com falha, execute o comando systemctl –failed –type=service.
Controle de serviços do sistema Objetivos
Depois de concluir esta seção, você deverá ser capaz de controlar daemons do sistema e serviços de rede usando o systemctl. Início e encerramento de serviços
Os serviços precisam ser interrompidos ou iniciados manualmente por vários motivos: talvez o serviço precise ser atualizado; o arquivo de configuração pode precisar de alterações; um serviço talvez precise ser desinstalado; ou um administrador pode iniciar manualmente um serviço usado com pouca frequência.
Para iniciar um serviço, primeiro verifique se ele não está sendo executado com o systemctl status. Depois, use o comando systemctl start como usuário root (usando sudo se necessário). O exemplo abaixo mostra como iniciar o serviço sshd.service:
[root@host ~]# systemctl start sshd.service
O serviço systemd procura arquivos .servive para gerenciamento de serviços em comandos na ausência do tipo de serviço com o nome do serviço. Assim, o comando acima pode ser executado como:
[root@host ~]# systemctl start sshd
Para interromper um serviço em execução no momento, use o argumento stop com o comando systemctl. O exemplo abaixo mostra como encerrar o serviço sshd.service:
[root@host ~]# systemctl stop sshd.service
Reinício e recarregamento de serviços
Durante o reinício de um serviço em execução, o serviço é interrompido e, depois, iniciado. Na reinicialização do serviço, a ID do processo é alterada e uma nova ID de processo é associada durante a inicialização. Para reiniciar um serviço em execução, use o argumento restart com o comando systemctl. O exemplo abaixo mostra como reiniciar o serviço sshd.service:
[root@host ~]# systemctl restart sshd.service
Alguns serviços têm a capacidade de recarregar seus arquivos de configuração sem exigir uma reinicialização. Este processo é chamado de recarregamento de serviço. Recarregar um serviço não altera a ID do processo associado a vários processos de serviço. Para recarregar um serviço em execução, use o argumento reload com o comando systemctl. O exemplo abaixo mostra como recarregar o serviço sshd.service depois de alterar a configuração:
[root@host ~]# systemctl reload sshd.service
Caso você não tenha certeza se o serviço tem a funcionalidade de recarregar as alterações do arquivo de configuração, use o reload-or-restart argumento com o comando systemctl. O comando recarrega as alterações de configuração se a funcionalidade de recarregamento estiver disponível. Caso contrário, o comando reinicia o serviço para implementar as novas alterações de configuração:
[root@host ~]# systemctl reload-or-restart sshd.service
Listagem de dependências de unidade
Alguns serviços exigem que outros serviços sejam executados primeiro, criando dependências nos outros serviços. Outros serviços não são iniciados no momento da inicialização, mas apenas sob demanda. Em ambos os casos, systemd e systemctl iniciam serviços conforme necessário, seja para resolver a dependência ou para iniciar um serviço usado com pouca frequência. Por exemplo, se o serviço de impressão do CUPS não estiver em execução e um arquivo for colocado no diretório de spool de impressão, o sistema iniciará daemons ou comandos relacionados ao CUPS para satisfazer o pedido de impressão.
[root@host ~]# systemctl stop cups.service Warning: Stopping cups, but it can still be activated by: cups.path cups.socket
Para interromper completamente os serviços de impressão em um sistema, interrompa todas as três unidades. A desativação do serviço desabilita as dependências.
O comando systemctl list-dependencies UNIT exibe um mapeamento de hierarquia de dependências para iniciar a unidade de serviço. Para listar dependências reversas (unidades que dependem da unidade especificada), use a opção –reverse com o comando.
[root@host ~]# systemctl list-dependencies sshd.service sshd.service ● ├─system.slice ● ├─sshd-keygen.target ● │ ├─sshd-keygen@ecdsa.service ● │ ├─sshd-keygen@ed25519.service ● │ └─sshd-keygen@rsa.service ● └─sysinit.target …output omitted…
Incluir e remover máscaras de serviços
Às vezes, um sistema pode ter diferentes serviços instalados que estejam em conflito. Por exemplo, há vários métodos de gerenciar servidores de e-mail (postfix e sendmail, por exemplo). Mascarar um serviço impede que um administrador inicie acidentalmente um serviço que esteja em conflito com outros. O mascaramento cria um link nos diretórios de configuração para o arquivo /dev/null que impede que o serviço seja iniciado.
[root@host ~]# systemctl mask sendmail.service Created symlink /etc/systemd/system/sendmail.service → /dev/null.
[root@host ~]# systemctl list-unit-files –type=service UNIT FILE STATE …output omitted… sendmail.service masked …output omitted…
A tentativa de iniciar uma unidade de serviço mascarada falha com a seguinte saída:
[root@host ~]# systemctl start sendmail.service Failed to start sendmail.service: Unit sendmail.service is masked.
Use o comando systemctl unmask para desmascarar a unidade de serviço.
[root@host ~]# systemctl unmask sendmail Removed /etc/systemd/system/sendmail.service.
Importante
Um serviço desativado pode ser iniciado manualmente ou por outros arquivos da unidade, mas não é iniciado automaticamente na inicialização. Um serviço mascarado não pode ser iniciado manual ou automaticamente. Habilitação de serviços para iniciar ou interromper na inicialização
Iniciar um serviço em um sistema em execução não garante que o serviço inicia automaticamente quando o sistema é reinicializado. Da mesma forma, interromper um serviço em um sistema em execução não evita que ele inicie novamente quando o sistema for reinicializado. A criação de links nos diretórios de configuração systemd permitem que o serviço inicie na inicialização. Os comandos systemctl criam e removem esses links.
Para iniciar um serviço na inicialização, use o comando systemctl enable.
[root@root ~]# systemctl enable sshd.service Created symlink /etc/systemd/system/multi-user.target.wants/sshd.service → /usr/lib/systemd/system/sshd.service.
O comando acima cria um link simbólico a partir do arquivo da unidade de serviço, geralmente no diretório /usr/lib/systemd/system, para o local no disco onde systemd procura arquivos, que está no diretório /etc/systemd/system/TARGETNAME.target.wants. Ativar um serviço não inicia o serviço na sessão atual. Para iniciar o serviço e permitir que ele inicie automaticamente durante a inicialização, execute ambos os comandos systemctl start e systemctl enable.
Para impedir que o serviço seja iniciado automaticamente, use o comando a seguir, que remove o link simbólico criado durante a ativação de um serviço. Observe que o ato de desabilitar um serviço não o interrompe.
[root@host ~]# systemctl disable sshd.service Removed /etc/systemd/system/multi-user.target.wants/sshd.service.
Para verificar se o serviço está ativado ou desativado, use o comando systemctl is-enabled. Sumário de comandos systemctl
Os serviços podem ser iniciados e interrompidos em um sistema em execução e habilitados ou desabilitados para iniciarem automaticamente no momento do boot.
Tabela 9.3. Comandos úteis de gerenciamento de serviços
gerenciamento_services.png
Capítulo 10. Configuração e proteção do SSH
Acesso à linha de comando remoto com o SSH Objetivos
Depois de concluir esta seção, você deverá ser capaz de fazer login em um sistema remoto e executar comandos usando ssh. O que é o OpenSSH?
O OpenSSH implementa o Secure Shell ou o protocolo SSH em sistemas Red Hat Enterprise Linux. O protocolo SSH permite que os sistemas se comuniquem de maneira criptografada e segura em uma rede insegura.
Você pode usar o comando ssh para criar uma conexão segura com um sistema remoto, autenticar como um usuário específico e obter uma sessão de shell interativa no sistema remoto como esse usuário. Você também pode usar o comando ssh para executar um comando individual no sistema remoto sem acessar o shell interativo. Exemplos do Secure Shell
O comando ssh a seguir faria o seu login no servidor remoto remotehost usando o mesmo nome de usuário do usuário local atual. Neste exemplo, o sistema remoto solicita a autenticação com a senha desse usuário.
[user01@host ~]$ ssh remotehost user01@remotehost’s password: redhat …output omitted… [user01@remotehost ~]$
Você pode usar o comando exit para fazer o logout do sistema remoto.
[user01@remotehost ~]$ exit logout Connection to remotehost closed. [user01@host ~]$
O próximo comando ssh faria o seu login no servidor remoto remotehost usando o mesmo nome de usuário user02. Novamente, o sistema remoto solicita a autenticação com a senha desse usuário.
[user01@host ~]$ ssh user02@remotehost user02@remotehost’s password: shadowman …output omitted… [user02@remotehost ~]$
Esse comando ssh executaria o comando hostname no sistema remoto remotehost como o usuário user02 sem acessar o shell interativo remoto.
[user01@host ~]$ ssh user02@remotehost hostname user02@remotehost’s password: shadowman remotehost.lab.example.com [user01@host ~]$
Observe que o comando anterior exibiu a saída no terminal do sistema local. Identificação de usuários remotos
O comando w exibe uma lista de usuários atualmente conectados ao computador. Isso é especialmente útil para mostrar quais usuários estão conectados por meio de ssh, em quais locais remotos e o que eles estão fazendo.
[user01@host ~]$ ssh user01@remotehost user01@remotehost’s password: redhat [user01@remotehost ~]$ w 16:13:38 up 36 min, 1 user, load average: 0.00, 0.00, 0.00 USER TTY FROM LOGIN@ IDLE JCPU PCPU WHAT user02 pts/0 172.25.250.10 16:13 7:30 0.01s 0.01s -bash user01 pts/1 172.25.250.10 16:24 3.00s 0.01s 0.00s w [user02@remotehost ~]$
A saída precedente mostra que o usuário user02 fez login no sistema no pseudoterminal 0 às 16:13 hoje a partir do host com o endereço IP 172.25.250.10, e ficou ocioso em um prompt do shell por sete minutos e trinta segundos. A saída anterior também mostra que o usuário user01 fez login no sistema no pseudoterminal 1 e ficou ocioso desde os últimos três segundos após a execução do comando w. Chaves do host do SSH
O SSH garante a segurança da comunicação por meio da criptografia de chaves públicas. Quando um cliente SSH se conecta a um servidor SSH, o servidor envia uma cópia da chave pública ao cliente antes de o cliente fazer login. Essa chave é usada para estabelecer a criptografia segura do canal de comunicação e para autenticar o servidor para o cliente.
Quando um usuário usa o comando ssh para se conectar a um servidor SSH, o comando verifica se há uma cópia da chave pública desse servidor em seus arquivos hosts locais conhecidos. O administrador do sistema pode o ter pré-configurado em /etc/ssh/ssh_known_hosts ou o usuário pode ter um arquivo ~/.ssh/known_hosts em seu diretório pessoal que contém a chave.
Se o cliente tiver uma cópia da chave, ssh comparará a chave dos arquivos hosts conhecidos para esse servidor com aquele que recebeu. Se as chaves não corresponderem, o cliente entenderá que o tráfego de rede ao servidor poderia ser interceptado ou que o servidor está comprometido e buscará a confirmação do usuário se deve ou não continuar com a conexão. Nota
Defina o parâmetro StrictHostKeyChecking como sim no arquivo ~/.ssh/config específico do usuário ou no /etc/ssh/ssh_config válido para todo o sistema para que o comando ssh sempre anule a conexão por SSH se as chaves públicas não corresponderem.
Se o cliente não tiver uma cópia da chave pública em seus arquivos de hosts conhecidos, o comando ssh perguntará se você deseja fazer login de qualquer maneira. Se você fizer isso, uma cópia da chave pública será salva no arquivo ~/.ssh/known_hosts para que a identidade do servidor possa ser confirmada automaticamente no futuro.
[user01@host ~]$ ssh newhost The authenticity of host ‘remotehost (172.25.250.12)’ can’t be established. ECDSA key fingerprint is SHA256:qaS0PToLrqlCO2XGklA0iY7CaP7aPKimerDoaUkv720. Are you sure you want to continue connecting (yes/no)? yes Warning: Permanently added ’newhost,172.25.250.12’ (ECDSA) to the list of known hosts. user01@newhost’s password: redhat …output omitted… [user01@newhost ~]$
Gerenciamento de chaves de hosts conhecidos SSH
Se a chave pública de um servidor for alterada porque a chave foi perdida devido a falha no disco rígido ou substituída por algum motivo legítimo, você precisará editar os arquivos de hosts conhecidos para garantir que a entrada da chave pública antiga seja substituída por uma entrada com a nova chave pública para fazer login sem erros.
As chaves públicas são armazenadas no /etc/ssh/ssh_known_hosts e no arquivo ~/.ssh/known_hosts de cada usuário no cliente SSH. Cada chave está em uma linha. O primeiro campo é uma lista de nomes de host e endereços IP que compartilham essa chave pública. O segundo campo é o algoritmo de criptografia da chave. O último campo é a chave em si.
[user01@host ~]$ cat ~/.ssh/known_hosts remotehost,172.25.250.11 ecdsa-sha2-nistp256 AAAAE2VjZHNhLXNoYTItbmlzdHAyNTYAAAAIbmlzdHAyNTYAAABBBOsEi0e+FlaNT6jul8Ag5Nj+RViZl0yE2w6iYUr+1fPtOIF0EaOgFZ1LXM37VFTxdgFxHS3D5WhnIfb+68zf8+w=
Cada servidor SSH remoto que você conecta armazena sua chave pública no diretório /etc/ssh em arquivos com a extensão .pub.
[user01@remotehost ~]$ ls /etc/ssh/*key.pub /etc/ssh/ssh_host_ecdsa_key.pub /etc/ssh/ssh_host_ed25519_key.pub /etc/ssh/ssh_host_rsa_key.pub
Nota
É uma boa prática adicionar entradas que correspondam aos arquivos ssh_host_*key.pub do servidor para seu arquivo ~/.ssh/known_hosts ou o arquivo /etc/ssh/ssh_known_hosts de todo o sistema.
Configuração da autenticação baseada em chaves SSH
Objetivos
Depois de concluir esta seção, você deverá ser capaz de configurar uma conta de usuário para usar autenticação baseada em chave para fazer login em sistemas remotos com segurança e sem uma senha. Autenticação baseada em chaves SSH
Você pode configurar um servidor SSH para permitir a autenticação sem uma senha usando autenticação baseada em chave. Essa é baseada em um esquema de chave privada-pública.
Para fazer isso, você gera um par combinado de arquivos de chaves criptográficas. Uma é uma chave privada, a outra é uma chave pública correspondente. O arquivo de chave privada é usado como a credencial de autenticação e, como uma senha, deve ser mantido em segredo e protegido. A chave pública é copiada para sistemas nos quais o usuário deseja fazer login e é usada para verificar a chave privada. A chave pública não precisa ser secreta.
Você coloca uma cópia da chave pública em sua conta no servidor. Quando você tenta fazer login, o servidor SSH pode usar a chave pública para emitir um desafio que só pode ser respondido corretamente usando a chave privada. Como resultado, seu cliente ssh pode autenticar automaticamente seu login no servidor com sua cópia exclusiva da chave privada. Isso permite que você acesse sistemas com segurança e sem digitar sempre uma senha interativamente.
Geração de chaves SSH
Para criar uma chave privada e uma chave pública correspondente para autenticação, use o comando ssh-keygen. Por padrão, as suas chaves privada e pública são salvas nos arquivos ~/.ssh/id_rsa e ~/.ssh/id_rsa.pub, respectivamente.
[user@host ~]$ ssh-keygen Generating public/private rsa key pair. Enter file in which to save the key (/home/user/.ssh/id_rsa): Enter Created directory ‘/home/user/.ssh’. Enter passphrase (empty for no passphrase): Enter Enter same passphrase again: Enter Your identification has been saved in /home/user/.ssh/id_rsa. Your public key has been saved in /home/user/.ssh/id_rsa.pub. The key fingerprint is: SHA256:vxutUNPio3QDCyvkYm1oIx35hmMrHpPKWFdIYu3HV+w user@host.lab.example.com The key’s randomart image is: +—[RSA 2048]—-+ | | | . . | | o o o | | . = o o . | | o + = S E . | | ..O o + * + | |.+% O . + B . | |=*oO . . + * | |++. . +. | +—-[SHA256]—–+
Se você não especificar uma senha quando ssh-keygen solicitar, a chave privada gerada não estará protegida. Nesse caso, qualquer pessoa com o arquivo de chave privada poderá usá-lo para autenticação. Se você definir uma senha, precisará digitá-la ao usar a chave privada para autenticação. (Portanto, você estaria usando a senha da chave privada, em vez da senha no host remoto para autenticar.)
Você pode executar um programa auxiliar chamado ssh-agent que pode armazenar temporariamente em cache a sua senha de chave privada na memória no início da sua sessão para obter uma verdadeira autenticação sem senha. Isso será discutido mais adiante nesta seção.
O exemplo a seguir do comando ssh-keygen mostra a criação da chave privada protegida por senha junto com a chave pública.
[user@host ~]$ ssh-keygen -f .ssh/key-with-pass Generating public/private rsa key pair. Enter passphrase (empty for no passphrase): Enter same passphrase again: Your identification has been saved in .ssh/key-with-pass. Your public key has been saved in .ssh/key-with-pass.pub. The key fingerprint is: SHA256:w3GGB7EyHUry4aOcNPKmhNKS7dl1YsMVLvFZJ77VxAo user@host.lab.example.com The key’s randomart image is: +—[RSA 2048]—-+ | . + =.o … | | = B XEo o. | | . o O X =…. | | = = = B = o. | |= + * * S . | |.+ = o + . | | + . | | | | | +—-[SHA256]—–+
A opção -f com o comando ssh-keygen determina os arquivos onde as chaves são salvas. No exemplo anterior, as chaves privada e pública são salvas nos arquivos /home/user/.ssh/key-with-pass /home/user/.ssh/key-with-pass.pub, respectivamente. Atenção
Durante a geração adicional do par de chaves SSH, a menos que você especifique um nome de arquivo exclusivo, será solicitada permissão para substituir os arquivos id_rsa e id_rsa.pub existentes. Se você substituir os arquivos id_rsa e id_rsa.pub existentes, você deve substituir a chave pública antiga pela nova em todos os servidores SSH que tenham sua chave pública antiga.
Depois que as chaves SSH tiverem sido geradas, elas serão armazenadas por padrão no diretório .ssh/ do diretório pessoal do usuário. Os modos de permissão devem ser 600 em sua chave privada e 644 em sua chave pública.
Compartilhamento da chave pública
Antes que a autenticação baseada em chave possa ser usada, a chave pública precisa ser copiada para o sistema de destino. O comando ssh-copy-id copia a chave pública do par de chaves SSH para o sistema de destino. Se você omitir o caminho para o arquivo de chave pública durante a execução de ssh-copy-id, ela usa o arquivo /home/user/.ssh/id_rsa.pub padrão.
[user@host ~]$ ssh-copy-id -i .ssh/key-with-pass.pub user@remotehost /usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: “/home/user/.ssh/id_rsa.pub” /usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed /usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed – if you are prompted now it is to install the new keys user@remotehost’s password: redhat Number of key(s) added: 1
Now try logging into the machine, with: “ssh ‘user@remotehost’” and check to make sure that only the key(s) you wanted were added.
Depois que a chave pública é transferida com êxito para um sistema remoto, você pode autenticar para um sistema remoto usando a chave privada correspondente ao fazer login no sistema remoto via SSH. Se você omitir o caminho para o arquivo de chave privada durante a execução do comando ssh, ela usará o arquivo /home/user/.ssh/id_rsa padrão.
[user@host ~]$ ssh -i .ssh/key-with-pass user@remotehost Enter passphrase for key ‘.ssh/key-with-pass’: redhatpass …output omitted… [user@remotehost ~]$ exit logout Connection to remotehost closed. [user@host ~]$
Uso do ssh-agent para autenticação não interativa
Se a chave privada SSH estiver protegida com uma senha, você normalmente terá que digitar a senha para usar a chave privada para autenticação. No entanto, você pode usar um programa chamado ssh-agent para armazenar em cache temporariamente a senha na memória. Então, sempre que você usar SSH para fazer login em outro sistema com a chave privada, ssh-agent fornecerá automaticamente a senha para você. Isso é conveniente e pode melhorar a segurança, oferecendo menos oportunidades para alguém olhar por cima do seu ombro e ver você digitar a senha.
Dependendo da configuração do seu sistema local, se você inicialmente fazer login no ambiente de área de trabalho gráfica do GNOME, o programa ssh-agent poderá ser iniciado e configurado automaticamente para você.
Se você fazer login em um console de texto, faça o login usando ssh, ou use sudo ou su. Provavelmente, será necessário iniciar ssh-agent manualmente para essa sessão. Você pode fazer isso com o seguinte comando:
[user@host ~]$ eval $(ssh-agent) Agent pid 10155 [user@host ~]$
Nota
Quando você executa ssh-agent, ele imprime alguns comandos do shell. Você precisa executar esses comandos para definir variáveis de ambiente usadas por programas como ssh-add para se comunicar com ele. O comando eval $(ssh-agent) inicia ssh-agent e executa esses comandos para definir automaticamente essas variáveis de ambiente para essa sessão do shell. Ele também exibe a PID do processo ssh-agent.
Quando ssh-agent está em execução, você precisa informar a senha da(s) chave(s) privada(s). Você pode fazer isso com o comando ssh-add.
Os comandos ssh-add a seguir adicionam as chaves privadas de /home/user/.ssh/id_rsa (o padrão) e arquivos /home/user/.ssh/key-with-pass, respectivamente.
[user@host ~]$ ssh-add Identity added: /home/user/.ssh/id_rsa (user@host.lab.example.com) [user@host ~]$ ssh-add .ssh/key-with-pass Enter passphrase for .ssh/key-with-pass: redhatpass Identity added: .ssh/key-with-pass (user@host.lab.example.com)
Depois de adicionar com sucesso as chaves privadas ao processo ssh-agent, você pode invocar uma conexão por SSH usando o comando ssh. Se você estiver usando qualquer arquivo de chave privada diferente do arquivo /home/user/.ssh/id_rsa padrão, você deve usar a opção -i com o comando ssh para especificar o caminho para o arquivo de chave privada.
O exemplo a seguir do comando ssh usa o arquivo de chave privada padrão para autenticar em um servidor SSH.
[user@host ~]$ ssh user@remotehost Last login: Fri Apr 5 10:53:50 2019 from host.example.com [user@remotehost ~]$
O exemplo a seguir do comando ssh usa o arquivo de chave privada (não padrão) /home/user/.ssh/key-with-pass para autenticar em um servidor SSH. A chave privada no exemplo a seguir já foi descriptografada e adicionada ao seu processo pai ssh-agent, portanto, o comando ssh não solicita que você descriptografe a chave privada digitando interativamente sua senha.
[user@host ~]$ ssh -i .ssh/key-with-pass user@remotehost Last login: Mon Apr 8 09:44:20 2019 from host.example.com [user@remotehost ~]$
Quando você fizer o logout da sessão que iniciou ssh-agent, o processo será encerrado e as senhas das chaves privadas serão apagadas da memória.
Personalização da configuração do serviço OpeSSH
Objetivos
Depois de concluir esta seção, você deverá ser capaz de restringir logins diretos como root e desativar a autenticação baseada em senha para o serviço OpenSSH. Configuração do servidor OpenSSH
O serviço OpenSSH é fornecido por um daemon chamado sshd. O arquivo de configuração principal é /etc/ssh/sshd_config.
A configuração padrão do servidor OpenSSH funciona bem. No entanto, você pode fazer algumas alterações para fortalecer a segurança do seu sistema. Existem duas mudanças comuns que você pode fazer. Você pode proibir o login remoto direto para a conta root e pode proibir autenticação baseada em senha (em favor da autenticação de chave privada SSH). Proibição do superusuário de fazer login usando SSH
É uma boa prática proibir o login direto na conta de usuário root de sistemas remotos. Alguns dos riscos de permitir login direto como root incluem:
O nome de usuário root existe em cada sistema Linux por padrão. Assim, um invasor em potencial precisa apenas adivinhar a senha, ao invés de uma combinação de nome de usuário e senha válidos. Isso reduz a complexidade de um invasor.
O usuário root tem privilégios irrestritos, portanto, seu comprometimento pode levar a danos máximos ao sistema.
Do ponto de vista da auditoria, pode ser difícil rastrear qual usuário autorizado fez login como root e fez alterações. Se os usuários tiverem que fazer o login como um usuário comum e mudar para a conta root, isso gera um evento de log que pode ser usado para ajudar a fornecer responsabilidade.
O servidor OpenSSH usa definição da configuração PermitRootLogin no arquivo de configuração /etc/ssh/sshd_config para permitir ou proibir usuários de fazer login no sistema root.
PermitRootLogin yes
Com o parâmetro PermitRootLogin definido como sim, como é padrão, as pessoas têm permissão para fazer login como root. Para evitar isso, defina o valor como não. Como alternativa, para evitar a autenticação baseada em senha, mas permitir autenticação baseada em chave privada para root, defina o parâmetro PermitRootLogin como without-password.
O servidor SSH (sshd) deve ser carregado novamente para que as alterações entrem em vigor.
[root@host ~]# systemctl reload sshd
Proibição da autenticação baseada em senha para SSH
Permitir somente logins baseados em chave privada à linha de comando remoto tem várias vantagens:
Os invasores não podem usar ataques de adivinhação de senha para invadir contas remotas no sistema.
Com chaves privadas protegidas por senha, um invasor precisa da senha e de uma cópia da chave privada. Com senhas, um invasor precisa apenas da senha.
Usando chaves privadas protegidas por senha em conjunto com ssh-agent, a senha é exposta com menos frequência, pois ela é inserida com menos frequência e o login é mais conveniente para o usuário.
O servidor OpenSSH usa o parâmetro PasswordAuthentication no arquivo de configuração /etc/ssh/sshd_config para controlar se os usuários podem usar a autenticação baseada em senha ao fazer login no sistema.
PasswordAuthentication yes
O valor padrão sim para o parâmetro PasswordAuthentication no arquivo de configuração /etc/ssh/sshd_config faz com que o servidor SSH permita que os usuários usem a autenticação baseada em senha ao fazer login. O valor não para PasswordAuthentication impede que os usuários usem a autenticação baseada em senha.
Tenha em mente que sempre que você alterar o arquivo /etc/ssh/sshd_config, será necessário recarregar o serviço sshd para que as alterações entrem em vigor. Importante
Se você desativar a autenticação baseada em senha para ssh, deverá ter uma maneira de garantir que o arquivo ~/.ssh/authorized_keys do usuário no servidor remoto seja preenchido com sua chave pública, para que eles possam fazer login.
Capítulo 11. Análise e armazenamento de logs
Descrição da arquitetura de log do sistema
Objetivos
Depois de concluir esta seção, você deverá ser capaz de descrever a arquitetura básica de registro em log usada pelo Red Hat Enterprise Linux para registrar eventos. Registro em log do sistema
Os processos e o kernel do sistema operacional registram em log os eventos que ocorrem. Esses logs são usados para a auditoria do sistema e para a solução de problemas.
Muitos sistemas registram logs de eventos em arquivos de texto que são mantidos no diretório /var/log. Esses logs podem ser inspecionados usando utilitários de texto normais, como less e tail.
Um sistema de registro em log padrão com base no protocolo Syslog é integrado ao Red Hat Enterprise Linux. Muitos programas usam esse sistema para registrar eventos e organizá-los em arquivos de log. Os serviços systemd-journald e rsyslog controlam as mensagens do syslog no Red Hat Enterprise Linux 8.
O serviço systemd-journald está no centro da arquitetura de log de eventos do sistema operacional. Ele coleta mensagens de eventos de várias fontes, incluindo o kernel, a saída dos estágios iniciais do processo de boot, a saída padrão e o erro padrão dos daemons quando eles são inicializados e executados, além dos eventos do syslog. Em seguida, ele os reestrutura em um formato padrão e os grava em um diário estruturado e indexado do sistema. Por padrão, esse diário é armazenado em um sistema de arquivos que não persiste nas reinicializações.
No entanto, o serviço rsyslog lê mensagens do syslog recebidas por systemd-journald do diário quando eles chegam. Em seguida, ele processa os eventos syslog, registrando-os em seus arquivos de log ou encaminhando-os para outros serviços de acordo com sua própria configuração.
O serviço rsyslog classifica e grava as mensagens do syslog nos arquivos de log que persistem em reinicializações em /var/log. O serviço rsyslog classifica as mensagens de log para arquivos de log específicos com base no tipo de programa que enviou cada mensagem, ou facility, e a prioridade de cada mensagem do syslog.
Além dos arquivos de mensagens do syslog, o diretório /var/log contém arquivos de log de outros serviços no sistema. A tabela a seguir lista alguns arquivos úteis no diretório /var/log.
Tabela 11.1. Arquivos de log do sistema selecionados
log_a1.png
Nota
Alguns aplicativos não usam o syslog para gerenciar suas mensagens de log, embora, normalmente, eles salvem seus arquivos de log em um subdiretório de /var/log. Por exemplo, o servidor web Apache salva as mensagens de log em arquivos de um subdiretório do diretório /var/log.
Análise dos arquivos do syslog
Objetivos
Depois de concluir esta seção, você deverá ser capaz de interpretar eventos nos arquivos do syslog relevantes para solucionar problemas ou revisar o status do sistema. Registro de eventos no sistema
Vários programas usam o protocolo syslog para registrar eventos no sistema. Cada mensagem de log é categorizada por um recurso (o tipo de mensagem) e uma prioridade (a gravidade da mensagem). Os recursos disponíveis estão documentados na página do man rsyslog.conf(5).
A tabela a seguir lista as oito prioridades padrão do syslog da mais alta à mais baixa.
Tabela 11.2. Visão geral das prioridades do syslog
syslog_a1.png
O serviço rsyslog usa o recurso e a prioridade das mensagens de log para determinar como lidar com elas. Ele é configurado por regras no arquivo /etc/rsyslog.conf e qualquer arquivo no diretório /etc/rsyslog.d que tem uma extensão de nome de arquivo .conf. Os pacotes de software podem facilmente adicionar regras instalando um arquivo apropriado no diretório /etc/rsyslog.d.
Cada regra que controla como classificar mensagens de syslog é uma linha em um dos arquivos de configuração. O lado esquerdo de cada linha indica os recursos e a gravidade das mensagens de syslog que correspondem à regra. O lado direito de cada linha indica o arquivo onde a mensagem de log será salva (ou onde entregar a mensagem). Um asterisco (*) é um curinga que corresponde a todos os valores.
Por exemplo, a seguinte linha registraria mensagens enviadas para o recurso authpriv em qualquer prioridade no arquivo /var/log/secure:
authpriv.* /var/log/secure
Às vezes, as mensagens de log correspondem a mais de uma regra em rsyslog.conf. Nesses casos, uma mensagem é armazenada em mais de um arquivo de log. Para limitar o número de mensagens armazenadas, a palavra-chave none no campo de prioridade indica que nenhuma mensagem para o recurso indicado deve ser armazenada em um determinado arquivo.
Em vez de registrar as mensagens do syslog em um arquivo, elas também podem ser impressas nos terminais de todos os usuários conectados. O arquivo rsyslog.conf tem uma configuração para imprimir todas as mensagens do syslog com a prioridade emerg nos terminais de todos os usuários conectados. Exemplos de regras do rsyslog
RULES
Log all kernel messages to the console.
Logging much else clutters up the screen.
#kern.* /dev/console
Log anything (except mail) of level info or higher.
Don’t log private authentication messages!
*.info;mail.none;authpriv.none;cron.none /var/log/messages
The authpriv file has restricted access.
authpriv.* /var/log/secure
Log all the mail messages in one place.
mail.* -/var/log/maillog
Log cron stuff
cron.* /var/log/cron
Everybody gets emergency messages
.emerg :omusrmsg:
Save news errors of level crit and higher in a special file.
uucp,news.crit /var/log/spooler
Save boot messages also to boot.log
local7.* /var/log/boot.log
Nota
O subsistema syslog tem muito mais recursos além do escopo deste curso. Quem desejar saber mais, pode consultar a página do man rsyslog.conf(5) e a vasta documentação HTML em /usr/share/doc/rsyslog/html/index.html incluída no pacote rsyslog-doc, que está disponível no repositório AppStream no Red Hat Enterprise Linux 8. Rodízio de arquivos de log
A ferramenta logrotate faz o rodízio dos arquivos de log para evitar que eles ocupem muito espaço no sistema de arquivos que contém o diretório /var/log. Quando ocorre o rodízio de um arquivo de log, ele é renomeado com uma extensão que indica a data do rodízio. Por exemplo, o arquivo /var/log/messages antigo poderá se tornar /var/log/messages-20190130 se o rodízio ocorrer em 30/01/2019. Depois que o arquivo de log antigo sofrer rodízio, um novo arquivo de log será criado, e o serviço que escreve nele será notificado.
Após um determinado número de rodízios (geralmente após quatro semanas), o arquivo de log mais antigo é descartado para liberar espaço em disco. Uma tarefa agendada executa o programa logrotate diariamente para verificar se algum log precisa sofrer rodízio. A maioria dos arquivos de log sofrem rodízio semanalmente, mas o logrotate faz o rodízio de alguns de maneira mais rápida ou mais lenta ou quando atingem um determinado tamanho.
A configuração do logrotate não é abordada neste curso. Para obter mais informações, consulte a página do man logrotate(8). Análise de uma entrada do syslog
As mensagens de log iniciam com a mensagem mais antiga no topo e as mensagens mais recentes no final do arquivo de log. O serviço rsyslog usa um formato padrão ao gravar entradas em arquivos de log. O exemplo a seguir explica a anatomia de uma mensagem de log no arquivo de log /var/log/secure.
logs_a2.png
Monitoramento de logs
Monitorar um ou mais arquivos de log de eventos é importante para reproduzir problemas e questões. O comando tail -f /path/to/file exibe as últimas 10 linhas do arquivo especificado e continua a mostrar as novas linhas do arquivo conforme são gravadas.
Por exemplo, para monitorar as tentativas de login com falha, execute o comando tail em um terminal e, em outro terminal, execute o comando ssh com o usuário root enquanto um usuário tenta fazer login no sistema.
No primeiro terminal, execute o seguinte comando tail:
[root@host ~]# tail -f /var/log/secure
No segundo terminal, execute o seguinte comando ssh:
[root@host ~]# ssh root@localhost root@localhost’s password: redhat …output omitted… [root@host ~]#
Volte para o primeiro terminal e visualize os logs.
…output omitted… Feb 10 09:01:13 host sshd[2712]: Accepted password for root from 172.25.254.254 port 56801 ssh2 Feb 10 09:01:13 host sshd[2712]: pam_unix(sshd:session): session opened for user root by (uid=0)
Envio manual de mensagens do syslog
O comando logger pode enviar mensagens para o serviço do rsyslog. Por padrão, ele envia a mensagem para o recurso user com a prioridade notice (user.notice), a menos que especificado de outra forma com a opção -p. Ele é útil para testar as alterações na configuração do serviço rsyslog.
Para enviar uma mensagem para o serviço rsyslog que fique gravada no arquivo de log /var/log/boot.log, execute o seguinte comando logger:
[root@host ~]# logger -p local7.notice “Log entry created on host”
Análise das entradas do diário do sistema
Objetivos
Depois de concluir esta seção, você deverá ser capaz de localizar e interpretar entradas de log no diário do sistema para solucionar problemas ou revisar o status do sistema. Localização de eventos
O serviço systemd-journald armazena dados de registro em um arquivo binário estruturado e indexado, denominado diário. Esses dados incluem informações adicionais sobre o evento de log. Por exemplo, para eventos do syslog, isso inclui o recurso e a prioridade da mensagem original. Importante
No Red Hat Enterprise Linux 8, o diretório /run/log armazena o diário do sistema por padrão. O conteúdo do diretório /run/log é limpo após a reinicialização. Você pode alterar essa configuração e aprenderá a fazer isso neste capítulo.
Para recuperar mensagens de log do diário, use o comando journalctl. Você pode usar esse comando para visualizar todas as mensagens no diário ou para procurar eventos específicos com base em uma ampla variedade de opções e critérios. Se você executar o comando como root, terá acesso total ao diário. Os usuários regulares também podem usar esse comando, mas podem ser impedidos de ver certas mensagens.
[root@host ~]# journalctl …output omitted… Feb 21 17:46:25 host.lab.example.com systemd[24263]: Stopped target Sockets. Feb 21 17:46:25 host.lab.example.com systemd[24263]: Closed D-Bus User Message Bus Socket. Feb 21 17:46:25 host.lab.example.com systemd[24263]: Closed Multimedia System. Feb 21 17:46:25 host.lab.example.com systemd[24263]: Reached target Shutdown. Feb 21 17:46:25 host.lab.example.com systemd[24263]: Starting Exit the Session… Feb 21 17:46:25 host.lab.example.com systemd[24268]: pam_unix(systemd-user:session): session c> Feb 21 17:46:25 host.lab.example.com systemd[1]: Stopped User Manager for UID 1001. Feb 21 17:46:25 host.lab.example.com systemd[1]: user-runtime-dir@1001.service: Unit not neede> Feb 21 17:46:25 host.lab.example.com systemd[1]: Stopping /run/user/1001 mount wrapper… Feb 21 17:46:25 host.lab.example.com systemd[1]: Removed slice User Slice of UID 1001. Feb 21 17:46:25 host.lab.example.com systemd[1]: Stopped /run/user/1001 mount wrapper. Feb 21 17:46:36 host.lab.example.com sshd[24434]: Accepted publickey for root from 172.25.250.> Feb 21 17:46:37 host.lab.example.com systemd[1]: Started Session 20 of user root. Feb 21 17:46:37 host.lab.example.com systemd-logind[708]: New session 20 of user root. Feb 21 17:46:37 host.lab.example.com sshd[24434]: pam_unix(sshd:session): session opened for u> Feb 21 18:01:01 host.lab.example.com CROND[24468]: (root) CMD (run-parts /etc/cron.hourly) Feb 21 18:01:01 host.lab.example.com run-parts[24471]: (/etc/cron.hourly) starting 0anacron Feb 21 18:01:01 host.lab.example.com run-parts[24477]: (/etc/cron.hourly) finished 0anacron lines 1464-1487/1487 (END) q
O comando journalctl realça as mensagens de log importantes: as mensagens com prioridade notice ou warning estão em negrito e as mensagens com prioridade error ou superior estão escritas em vermelho.
A chave para usar o diário para solução de problemas e auditoria é limitar as pesquisas do diário para que mostrem somente os resultados relevantes.
Por padrão, journalctl -n mostra pelo menos 10 entradas de log. Você pode ajustar isso com um argumento opcional que especifica quantas entradas de log devem ser exibidas. Para as últimas cinco entradas de log, execute o seguinte comando journalctl:
[root@host ~]# journalctl -n 5 – Logs begin at Wed 2019-02-20 16:01:17 +07, end at Thu 2019-02-21 18:01:01 +07. – …output omitted… Feb 21 17:46:37 host.lab.example.com systemd-logind[708]: New session 20 of user root. Feb 21 17:46:37 host.lab.example.com sshd[24434]: pam_unix(sshd:session): session opened for u> Feb 21 18:01:01 host.lab.example.com CROND[24468]: (root) CMD (run-parts /etc/cron.hourly) Feb 21 18:01:01 host.lab.example.com run-parts[24471]: (/etc/cron.hourly) starting 0anacron Feb 21 18:01:01 host.lab.example.com run-parts[24477]: (/etc/cron.hourly) finished 0anacron lines 1-6/6 (END) q
De maneira semelhante ao comando tail -f, o comando journalctl -f exibe as últimas 10 linhas do diário e continua a mostrar resultados de novas entradas conforme são gravadas no diário. Para sair do processo journalctl -f, use a combinação de teclas Ctrl+C.
[root@host ~]# journalctl -f – Logs begin at Wed 2019-02-20 16:01:17 +07. – …output omitted… Feb 21 18:01:01 host.lab.example.com run-parts[24477]: (/etc/cron.hourly) finished 0anacron Feb 21 18:22:42 host.lab.example.com sshd[24437]: Received disconnect from 172.25.250.250 port 48710:11: disconnected by user Feb 21 18:22:42 host.lab.example.com sshd[24437]: Disconnected from user root 172.25.250.250 port 48710 Feb 21 18:22:42 host.lab.example.com sshd[24434]: pam_unix(sshd:session): session closed for user root Feb 21 18:22:42 host.lab.example.com systemd-logind[708]: Session 20 logged out. Waiting for processes to exit. Feb 21 18:22:42 host.lab.example.com systemd-logind[708]: Removed session 20. Feb 21 18:22:43 host.lab.example.com sshd[24499]: Accepted publickey for root from 172.25.250.250 port 48714 ssh2: RSA SHA256:1UGybTe52L2jzEJa1HLVKn9QUCKrTv3ZzxnMJol1Fro Feb 21 18:22:44 host.lab.example.com systemd-logind[708]: New session 21 of user root. Feb 21 18:22:44 host.lab.example.com systemd[1]: Started Session 21 of user root. Feb 21 18:22:44 host.lab.example.com sshd[24499]: pam_unix(sshd:session): session opened for user root by (uid=0) ^C [root@host ~]#
Para solucionar problemas, é útil filtrar a saída do diário por prioridade das entradas do diário. O journalctl -p seleciona o nome ou o número de um nível de prioridade e exibe as entradas do diário para entradas com essa prioridade e superiores. O comando journalctl reconhece os níveis de prioridade debug, info, notice, warning, err, crit, alert e emerg.
Execute o seguinte comando journalctl para listar entradas do diário com prioridade err ou superior:
[root@host ~]# journalctl -p err – Logs begin at Wed 2019-02-20 16:01:17 +07, end at Thu 2019-02-21 18:01:01 +07. – ..output omitted… Feb 20 16:01:17 host.lab.example.com kernel: Detected CPU family 6 model 13 stepping 3 Feb 20 16:01:17 host.lab.example.com kernel: Warning: Intel Processor - this hardware has not undergone testing by Red Hat and might not be certif> Feb 20 16:01:20 host.lab.example.com smartd[669]: DEVICESCAN failed: glob(3) aborted matching pattern /dev/discs/disc* Feb 20 16:01:20 host.lab.example.com smartd[669]: In the system’s table of devices NO devices found to scan lines 1-5/5 (END) q
Ao procurar por eventos específicos, você pode limitar os resultados a um determinado período de tempo. O comando journalctl tem duas opções para limitar os resultados a um período de tempo específico: as opções –since e –until. As duas opções usam um argumento de tempo no formato “AAAA-MM-DD hh:mm:ss” (as aspas duplas são necessárias para manter o espaço na opção). Se a data for omitida, o comando presumirá a data atual; se o tempo for omitido, ele presumirá que o período é todo o dia, com início às 00:00:00. As duas opções utilizam yesterday, today e tomorrow como argumentos válidos, além do campo de data e hora.
Execute o comando journalctl a seguir para listar todas as entradas de diário dos registros de hoje.
[root@host ~]# journalctl –since today – Logs begin at Wed 2019-02-20 16:01:17 +07, end at Thu 2019-02-21 18:31:14 +07. – …output omitted… Feb 21 18:22:44 host.lab.example.com systemd-logind[708]: New session 21 of user root. Feb 21 18:22:44 host.lab.example.com systemd[1]: Started Session 21 of user root. Feb 21 18:22:44 host.lab.example.com sshd[24499]: pam_unix(sshd:session): session opened for user root by (uid=0) Feb 21 18:31:13 host.lab.example.com systemd[1]: Starting dnf makecache… Feb 21 18:31:14 host.lab.example.com dnf[24533]: Red Hat Enterprise Linux 8.0 AppStream (dvd) 637 kB/s | 2.8 kB 00:00 Feb 21 18:31:14 host.lab.example.com dnf[24533]: Red Hat Enterprise Linux 8.0 BaseOS (dvd) 795 kB/s | 2.7 kB 00:00 Feb 21 18:31:14 host.lab.example.com dnf[24533]: Metadata cache created. Feb 21 18:31:14 host.lab.example.com systemd[1]: Started dnf makecache. lines 533-569/569 (END) q
Execute o comando journalctl a seguir para listar todas as entradas de diário de 2019-02-10 20:30:00 a 2019-02-13 12:00:00.
[root@host ~]# journalctl –since “2019-02-10 20:30:00”
–until “2019-02-13 12:00:00”
…output omitted…
Você também pode especificar todas as entradas desde um tempo relativo até o presente. Por exemplo, para especificar todas as entradas na última hora, você pode usar o seguinte comando:
[root@host ~]# journalctl –since “-1 hour” …output omitted…
Nota
Você pode usar outras especificações de tempo mais sofisticadas com as opções –since e –until. Para alguns exemplos, veja a página do man systemd.time(7).
Além do conteúdo visível do diário, existem campos conectados às entradas de log que só podem ser exibidos quando a opção de resultado detalhado está ativada. Qualquer campo adicional pode ser usado para filtrar o resultado de uma consulta ao diário. Isso é recomendado para reduzir o resultado das pesquisas de determinados eventos complexos no diário.
[root@host ~]# journalctl -o verbose – Logs begin at Wed 2019-02-20 16:01:17 +07, end at Thu 2019-02-21 18:31:14 +07. – …output omitted… Thu 2019-02-21 18:31:14.509128 +07… PRIORITY=6 _BOOT_ID=4409bbf54680496d94e090de9e4a9e23 _MACHINE_ID=73ab164e278e48be9bf80e80714a8cd5 SYSLOG_FACILITY=3 SYSLOG_IDENTIFIER=systemd _UID=0 _GID=0 CODE_FILE=../src/core/job.c CODE_LINE=826 CODE_FUNC=job_log_status_message JOB_TYPE=start JOB_RESULT=done MESSAGE_ID=39f53479d3a045ac8e11786248231fbf _TRANSPORT=journal _PID=1 _COMM=systemd _EXE=/usr/lib/systemd/systemd _CMDLINE=/usr/lib/systemd/systemd –switched-root –system –deserialize 18 _CAP_EFFECTIVE=3fffffffff _SELINUX_CONTEXT=system_u:system_r:init_t:s0 _SYSTEMD_CGROUP=/init.scope _SYSTEMD_UNIT=init.scope _SYSTEMD_SLICE=-.slice UNIT=dnf-makecache.service MESSAGE=Started dnf makecache. _HOSTNAME=host.lab.example.com INVOCATION_ID=d6f90184663f4309835a3e8ab647cb0e _SOURCE_REALTIME_TIMESTAMP=1550748674509128 lines 32239-32275/32275 (END) q
A lista a seguir fornece os campos comuns do diário do sistema que podem ser usados para procurar linhas relevantes para um processo ou evento específico.
_COMM é o nome do comando
_EXE é o caminho para o executável do processo
_PID é a PID do processo
_UID é a UID do usuário que está executando o processo
_SYSTEMD_UNIT é a unidade do systemd que iniciou o processo
É possível combinar mais de um dos campos de diário do sistema para formar uma consulta de pesquisa granular com o comando journalctl. Por exemplo, o comando journalctl a seguir mostra todas as entradas de diário relacionadas à unidade sshd.service systemd de um processo com PID 1182.
[root@host ~]# journalctl _SYSTEMD_UNIT=sshd.service _PID=1182 Apr 03 19:34:27 host.lab.example.com sshd[1182]: Accepted password for root from ::1 port 52778 ssh2 Apr 03 19:34:28 host.lab.example.com sshd[1182]: pam_unix(sshd:session): session opened for user root by (uid=0) …output omitted…
Nota
Para obter uma lista dos campos de diário normalmente usados, consulte a página do man systemd.journal-fields(7).
Preservação do diário do sistema
Objetivos
Depois de concluir esta seção, você deverá ser capaz de configurar o diário do sistema para manter o registro dos eventos quando um servidor for reinicializado. Armazenamento permanente do diário do sistema
Por padrão, os diários do sistema são mantidos no diretório /run/log/journal, o que significa que os diários são limpos quando o sistema é reiniciado. Você pode alterar as configurações do serviço systemd-journald no arquivo /etc/systemd/journald.conf para manter os diários após as reinicializações.
O parâmetro Storage no arquivo /etc/systemd/journald.conf define se os diários do sistema devem ser armazenados de maneira volátil ou persistente nas reinicializações. Defina o parâmetro como persistent, volatile, auto ou none desta forma:
persistent: armazena os diários no diretório /var/log/journal, que é mantido nas reinicializações.
Se /var/log/journal não existir, o serviço systemd-journald criará o diretório.
volatile: armazena os diários no diretório /run/log/journal volátil.
Como o sistema de arquivos /run é temporário e existe somente na memória de tempo de execução, os dados armazenados nele, inclusive os diários do sistema, não são mantidos na reinicialização.
auto: se o diretório /var/log/journal existir, systemd-journald usará o armazenamento persistente, caso contrário, usará o armazenamento volátil.
Essa será a ação padrão se o parâmetro Storage não estiver definido.
none: não usa nenhum armazenamento. Todos os logs serão descartados, mas o encaminhamento de log ainda funcionará conforme o esperado.
A vantagem dos diários do sistema persistente é que os dados históricos são disponibilizados imediatamente no boot. No entanto, mesmo com um diário persistente, nem todos os dados são mantidos para sempre. O diário tem um mecanismo integrado de rodízio de logs que é acionado mensalmente. Além disso, por padrão, o diário não pode ocupar mais de 10% do sistema de arquivos em que reside nem deixar menos de 15% do sistema de arquivos livre. Esses valores podem ser ajustados para os diários de tempo de execução e persistentes em /etc/systemd/journald.conf. Os limites atuais de tamanho do diário são registrados em log quando o processo systemd-journald é iniciado. A seguinte saída do comando mostra as entradas de diário que refletem os limites atuais de tamanho:
[user@host ~]$ journalctl | grep -E ‘Runtime|System journal’ Feb 25 13:01:46 localhost systemd-journald[147]: Runtime journal (/run/log/journal/ae06db7da89142138408d77efea9229c) is 8.0M, max 91.4M, 83.4M free. Feb 25 13:01:48 remotehost.lab.example.com systemd-journald[548]: Runtime journal (/run/log/journal/73ab164e278e48be9bf80e80714a8cd5) is 8.0M, max 91.4M, 83.4M free. Feb 25 13:01:48 remotehost.lab.example.com systemd-journald[548]: System journal (/var/log/journal/73ab164e278e48be9bf80e80714a8cd5) is 8.0M, max 3.7G, 3.7G free. Feb 25 13:01:48 remotehost.lab.example.com systemd[1]: Starting Tell Plymouth To Write Out Runtime Data… Feb 25 13:01:48 remotehost.lab.example.com systemd[1]: Started Tell Plymouth To Write Out Runtime Data.
Nota
Acima, em grep, o símbolo de barra vertical (|) age como um operador ou, isto é, grep corresponde a qualquer linha que contenha a string Runtime ou System journal na saída de journalctl. Ele busca os limites atuais de tamanho do armazenamento volátil de diários (Runtime), bem como do armazenamento persistente (System).
Configuração de diários do sistema persistentes
Para configurar o serviço systemd-journald de modo a manter os diários do sistema de forma persistente nas reinicializações, defina Storage como persistent no arquivo /etc/systemd/journald.conf. Execute o editor de texto de sua escolha como superusuário para editar arquivo /etc/systemd/journald.conf.
[Journal] Storage=persistent …output omitted…
Depois de editar o arquivo de configuração, reinicie o serviço systemd-journald para que as alterações de configuração entrem em vigor.
[root@host ~]# systemctl restart systemd-journald
Se o serviço systemd-journald for reiniciado com êxito, você verá que o diretório /var/log/journal foi criado e contém um ou mais subdiretórios. Esses subdiretórios têm caracteres hexadecimais em seus nomes longos e contêm arquivos *.journal. Os arquivos *.journal são os arquivos binários que armazenam as entradas de diário estruturadas e indexadas.
[root@host ~]# ls /var/log/journal 73ab164e278e48be9bf80e80714a8cd5 [root@host ~]# ls /var/log/journal/73ab164e278e48be9bf80e80714a8cd5 system.journal user-1000.journal
Embora os diários do sistema sejam mantidos na reinicialização, você recebe um grande número de entradas na saída do comando journalctl, incluindo entradas da inicialização do sistema atual e das anteriores. Para limitar a saída a uma inicialização específica do sistema, use a opção -b com o comando journalctl. O seguinte comando journalctl recupera as entradas da primeira inicialização do sistema:
[root@host ~]# journalctl -b 1 …output omitted…
O comando journalctl a seguir recupera as entradas do segundo boot do sistema. Este argumento será relevante apenas se o sistema tiver sido reinicializado pelo menos duas vezes:
[root@host ~]# journalctl -b 2
O seguinte comando journalctl recupera as entradas do boot atual do sistema:
[root@host ~]# journalctl -b
Nota
Ao depurar uma falha do sistema com um diário persistente, normalmente é necessário limitar a consulta do diário à reinicialização anterior à falha. A opção -b pode estar acompanhada de um número negativo, indicando quantas inicializações anteriores do sistema o resultado deve incluir. Por exemplo, journalctl -b -1 limita o resultado apenas à inicialização anterior.
Manutenção de hora precisa
Objetivos
Depois de concluir esta seção, você deverá ser capaz de manter a sincronização de hora precisa usando NTP e configurar o fuso horário para garantir data e hora corretas nos eventos registrados pelos logs e pelo diário do sistema. Definição do fuso horário local e dos relógios locais
Ter a hora do sistema sincronizada e correta é essencial para a análise de arquivos de log em vários sistemas. O Network Time Protocol (NTP) é uma forma padrão na qual as máquinas fornecem e obtêm informações corretas de hora na Internet. Uma máquina pode obter informações precisas de hora por meio de serviços NTP públicos na Internet, como o NTP Pool Project. Um relógio de hardware de alta qualidade para fornecer a hora precisa para clientes locais é outra opção.
O comando timedatectl mostra uma visão geral das configurações do sistema com relação à hora, incluindo a hora atual, o fuso horário e as configurações de sincronização de NTP do sistema.
[user@host ~]$ timedatectl Local time: Fri 2019-04-05 16:10:29 CDT Universal time: Fri 2019-04-05 21:10:29 UTC RTC time: Fri 2019-04-05 21:10:29 Time zone: America/Chicago (CDT, -0500) System clock synchronized: yes NTP service: active RTC in local TZ: no
Um banco de dados de fusos horários está disponível e pode ser listado usando o comando timedatectl list-timezones.
[user@host ~]$ timedatectl list-timezones Africa/Abidjan Africa/Accra Africa/Addis_Ababa Africa/Algiers Africa/Asmara Africa/Bamako …
Nomes de fusos horários são baseados no banco de dados público mantido pela IANA. Os fusos horários são nomeados com base no continente ou no oceano, geralmente seguidos, porém nem sempre, da maior cidade dentro da região do fuso horário. Por exemplo, a maior parte do fuso horário MT (Mountain time) dos EUA é America/Denver.
Selecionar o nome correto poderá ser contraintuitivo em casos nos quais as localidades dentro do fuso horário têm regras diferentes para o horário de verão. Por exemplo, nos EUA, grande parte do Estado do Arizona (MT) não tem ajuste algum no horário de verão e se encontra no fuso horário America/Phoenix.
O comando tzselect é útil para identificar nomes corretos de fusos horários no zoneinfo. Ele faz perguntas de modo interativo ao usuário sobre o local do sistema e mostra o nome do fuso horário correto. Ele não faz alterações na configuração de fuso horário do sistema.
O superusuário pode alterar a configuração do sistema para atualizar o fuso horário usando o comando timedatectl set-timezone. O comando timedatectl a seguir atualiza o fuso horário atual para America/Phoenix.
[root@host ~]# timedatectl set-timezone America/Phoenix [root@host ~]# timedatectl Local time: Fri 2019-04-05 14:12:39 MST Universal time: Fri 2019-04-05 21:12:39 UTC RTC time: Fri 2019-04-05 21:12:39 Time zone: America/Phoenix (MST, -0700) System clock synchronized: yes NTP service: active RTC in local TZ: no
Nota
Se você precisar usar UTC (Coordinated Universal Time) em um determinado servidor, defina o fuso horário como UTC. O comando tzselect não inclui o nome do fuso horário UTC. Use o comando timedatectl set-timezone UTC para definir o fuso horário atual do sistema como UTC.
Use o comando timedatectl set-time para alterar o horário atual do sistema. O tempo é especificado no formato “AAAA-MM-DD hh:mm:ss”, no qual é possível omitir a data ou a hora. O comando timedatectl a seguir altera o horário para 09:00:00.
[root@host ~]# timedatectl set-time 9:00:00 [root@host ~]# timedatectl Local time: Fri 2019-04-05 09:00:27 MST Universal time: Fri 2019-04-05 16:00:27 UTC RTC time: Fri 2019-04-05 16:00:27 Time zone: America/Phoenix (MST, -0700) System clock synchronized: yes NTP service: active RTC in local TZ: no
O comando timedatectl set-ntp ativa ou desativa a sincronização de NTP para ajuste automático de hora. A opção requer um argumento true ou false para ser ativada ou desativada. O comando timedatectl a seguir ativa a sincronização de NTP.
[root@host ~]# timedatectl set-ntp true
Nota
No Red Hat Enterprise Linux 8, o comando timedatectl set-ntp ajustará se o serviço NTP chronyd está operando ou não. Outras distribuições do Linux podem usar essa configuração para ajustar um serviço NTP ou SNTP diferente.
Ativar ou desativar o NTP usando outros utilitários no Red Hat Enterprise Linux, como no aplicativo Settings do GNOME gráfico, também atualiza essa configuração. Configuração e monitoramento do chronyd
O relógio de hardware local (RTC), que normalmente é impreciso, é mantido atualizado pelo serviço chronyd, que o sincroniza com os servidores NTP configurados. Se não houver conectividade de rede disponível, chronyd calculará o desvio de tempo do RTC, que é gravado no driftfile especificado no arquivo de configuração /etc/chrony.conf.
Por padrão, o serviço chronyd usa servidores do NTP Pool Project para a sincronização de horário e não precisa de configurações adicionais. Ele pode ser útil para alterar os servidores NTP quando a máquina em questão estiver em uma rede isolada.
A camada da fonte de tempo do NTP determina sua qualidade. A camada determina o número de saltos que a máquina está em relação a um relógio de referência de alto desempenho. O relógio de referência é uma fonte de tempo stratum 0. Um servidor NTP diretamente anexado a ele é um stratum 1, enquanto uma máquina que esteja sincronizando a hora de acordo com o servidor NTP é uma fonte de tempo stratum 2.
server e par são as duas categorias de fontes de tempo que podem ser alteradas no arquivo de configuração /etc/chrony.conf. A categoria server fica um estrato acima do servidor NTP local, e a peer fica no mesmo nível de camada. Mais de um servidor e mais de um par podem ser especificados, sendo um por linha.
O primeiro argumento da linha server é o endereço IP ou o nome DNS do servidor NTP. Depois do endereço IP ou do nome do servidor, uma série de opções para o servidor pode ser exibida. É recomendável usar a opção iburst, porque depois que o serviço é iniciado, quatro medidas são obtidas em um curto período de tempo para uma sincronização inicial de relógio mais precisa.
A linha server classroom.example.com iburst a seguir no arquivo /etc/chrony.conf faz com que o serviço chronyd use a fonte de tempo do NTP classroom.example.com.
Use public servers from the pool.ntp.org project.
…output omitted… server classroom.example.com iburst …output omitted…
Depois de apontar chronyd para a fonte de tempo local, classroom.example.com, você deverá reiniciar o serviço.
[root@host ~]# systemctl restart chronyd
O comando chronyc atua como um cliente para o serviço chronyd. Depois de definir a sincronização do NTP, verifique se o sistema local está usando o servidor NTP para sincronizar o relógio do sistema usando o comando chronyc sources. Para obter um resultado mais descritivo e com explicações adicionais sobre a saída, use o comando chronyc sources -v.
[root@host ~]# chronyc sources -v 210 Number of sources = 1
.– Source mode ‘^’ = server, ‘=’ = peer, ‘#’ = local clock. / .- Source state ‘*’ = current synced, ‘+’ = combined , ‘-’ = not combined, | / ‘?’ = unreachable, ‘x’ = time may be in error, ‘~’ = time too variable. || .- xxxx [ yyyy ] +/- zzzz || / xxxx = adjusted offset, || Log2(Polling interval) -. | yyyy = measured offset, || \ | zzzz = estimated error. || | | MS Name/IP address Stratum Poll Reach LastRx Last sample
^* classroom.example.com 8 6 17 23 -497ns[-7000ns] +/- 956us
O caractere * no campo S (estado de origem) indica que o servidor classroom.example.com foi usado como uma fonte de tempo e que é o servidor NTP com o qual a máquina está atualmente sincronizada.
Capítulo 12. Gerenciamento de redes
Descrição de conceitos de rede
Liste recursos de rede do computador. Objetivos
Depois de concluir esta seção, você deverá ser capaz de descrever os conceitos fundamentais de endereçamento e roteamento de redes de um servidor. Modelo de rede TCP/IP
O modelo de rede TCP/IP é um conjunto de abstrações simplificado em quatro camadas que descreve como diferentes protocolos interagem para que os computadores enviem tráfego de uma máquina para outra pela Internet. É especificado no RFC 1122: Requisitos para hosts de Internet – camadas de comunicação. As quatro camadas são:
Aplicativo
Cada aplicativo tem especificações de comunicação, para que os clientes e os servidores possam se comunicar entre plataformas. Os protocolos comuns incluem SSH (login remoto), HTTPS (Web segura), NFS ou CIFS (compartilhamento de arquivos) e a SMTP (distribuição eletrônica de e-mail).
Transporte
Os protocolos de transporte são TCP e UDP. O protocolo TCP é uma comunicação confiável orientada a conexões, mas o UDP é um protocolo de datagrama sem correção. Os protocolos de aplicativos usam portas TCP ou UDP. Uma lista de portas conhecidas e registradas pode ser encontrada no arquivo /etc/services.
Quando um pacote é enviado na rede, a combinação da porta de serviço e do endereço IP forma um soquete. Cada pacote tem um soquete de origem e um soquete de destino. Essas informações poderão ser usadas durante o monitoramento e a filtragem.
Internet
A Internet, ou a camada de rede, carrega os dados do host de origem para o host de destino. Os protocolos IPv4 e IPv6 são protocolos de camada de Internet. Cada host tem um endereço IP e um prefixo usados para determinar endereços de rede. Os roteadores são usados para conectar as redes.
Link
A camada de link, ou o acesso a mídias, fornece a conexão a mídias físicas. Os tipos de redes mais comuns são ethernet cabeada (802.3) e WLAN sem fio (802.11). Cada dispositivo físico tem um endereço de hardware (MAC) que é usado para identificar o destino dos pacotes no segmento da rede local.
tcp-ip-model-vs-osi-model.svg
Descrição dos nomes de interfaces de rede
Cada porta de rede de um sistema tem um nome usado para configurá-lo e identificá-lo.
As versões mais antigas do Red Hat Enterprise Linux usavam nomes como eth0, eth1 e eth2 para cada interface de rede. O nome eth0 era a primeira porta de rede detectada pelo sistema operacional, eth1 era a segunda e assim por diante. No entanto, à medida que eram adicionados e removidos dispositivos, o mecanismo que detectava os dispositivos e definia seus nomes podia mudar qual interface receberia que nome. Além disso, o padrão PCIe não garante a ordem na qual os dispositivos PCIe serão detectados no boot, o que pode alterar a nomenclatura do dispositivo inesperadamente devido a variações durante a inicialização do dispositivo ou do sistema.
As versões mais recentes do Red Hat Enterprise Linux usam um sistema de nomenclatura diferente. Em vez de se basear na ordem de detecção, os nomes das interfaces de rede são atribuídos com base nas informações do firmware, na topologia do barramento PCI e no tipo de dispositivo de rede.
Os nomes das interfaces de rede começam com o tipo de interface:
As interfaces de ethernet começam com en
As interfaces de WLAN começam com wl
As interfaces de WWAN começam com ww
O restante do nome da interface após o tipo será baseado nas informações fornecidas pelo firmware do servidor ou determinado pela localização do dispositivo na topologia do PCI.
oN indica que esse é um dispositivo inicial e que o número de índice fornecido pelo firmware do servidor é N para o dispositivo. Assim, eno1 é o dispositivo 1 inicial de ethernet. Muitos servidores não fornecem essas informações.
sN indica que esse dispositivo está no slot hotplug PCI N. Assim, ens3 é uma placa de ethernet no slot hotplug PCI 3.
pMsN indica que esse [e um dispositivo PCI no barramento M no slot N. Assim, wlp4s0 é uma placa WLAN no barramento PCI 4 no slot 0. Se a placa for um dispositivo multifuncional (possível com uma placa de ethernet com várias portas, ou dispositivos que tenham ethernet mais algum outro recurso), você poderá ver fN adicionado ao nome do dispositivo. Assim, enp0s1f0 é a função 0 da placa de ethernet no barramento 0 no slot 1. Também pode haver uma segunda interface chamada enp0s1f1, a função 1 desse mesmo dispositivo.
A nomenclatura persistente significa que, uma vez que você sabe qual é o nome de uma interface de rede no sistema, também sabe que ela não será alterada posteriormente. A desvantagem é que você não pode assumir que um sistema com uma interface nomeará essa interface eth0 . Redes IPv4
IPv4 é o principal protocolo de rede usado na Internet atualmente. Você precisa ter pelo menos a compreensão básica da rede IPv4 para gerenciar a comunicação de redes em seus servidores.
Endereços IPv4
Um endereço IPv4 é um número de 32 bits, normalmente expresso em base decimal como quatro octetos de 8 bits com valores de 0 a 255, separados por pontos. O endereço é dividido em duas partes: a parte da rede e a parte do host. Todos os hosts na mesma sub-rede que podem se comunicar entre si diretamente sem um roteador têm a mesma parte de rede. Essa parte indica a sub-rede. Não pode haver mais de um host na sub-rede com a mesma parte de host. A parte de host identifica um host específico em uma sub-rede.
Na Internet moderna, o tamanho de uma sub-rede IPv4 pode variar. Para saber qual parte de um endereço IPv4 é da rede e qual é a parte do host, o administrador precisa saber que máscara de rede está atribuída à sub-rede. A máscara de rede indica quantos bits do endereço IPv4 pertencem à sub-rede. Quanto mais bits estiverem disponíveis para a parte do host, maior será o número de hosts possíveis na sub-rede.
O menor endereço possível em uma sub-rede (a parte de host preenchida por zeros em binário) às vezes é chamado de endereço de rede. O maior endereço possível em uma sub-rede (a parte de host toda em número um em binário) é usado para transmitir mensagens de transmissão no IPv4 e é chamado de endereço de transmissão.
As máscaras de rede são expressas de duas formas. A sintaxe mais antiga de máscara de rede usa 24 bits para a parte da rede e exibe 255.255.255.0. Uma nova sintaxe, chamada de notação CIDR, especifica um prefixo de rede de /24. Ambas as formas carregam as mesmas informações; especificamente, quantos bits à esquerda no endereço IP contribuem para seu endereço de rede.
Os exemplos a seguir ilustram como o endereço IP, o prefixo (máscara de rede), a parte da rede e a parte do host estão relacionados.
ipv4prefix.svg
Tabela 12.1. Cálculo do endereço de rede para 192.168.1.107/24
table_save_1.png
Tabela 12.2. Cálculo do endereço de rede para 10.1.1.18/8
table_save_2.png
Tabela 12.3. Cálculo do endereço de rede para 172.16.181.23/19
table_save_3.png
O endereço especial 127.0.0.1 sempre aponta para o sistema local (“localhost”), e a rede 127.0.0.0/8 pertence ao sistema local, para que ele possa se comunicar consigo mesmo usando protocolos de rede.
Roteamento IPv4
Seja com IPv4 ou IPv6, o tráfego da rede precisa se mover de host para host e de rede para rede. Cada host tem uma tabela de roteamento que diz a ele como rotear o tráfego para redes específicas. Uma entrada da tabela de roteamento mostra uma rede de destino, qual interface deve ser usada ao enviar o tráfego e o endereço IP de qualquer roteador intermediário necessário para retransmitir a mensagem a seu destino final. A entrada da tabela de roteamento que corresponde ao destino do tráfego de rede é usada para roteá-la. Se dois itens se corresponderem, o que tiver o prefixo mais longo será usado.
Se o tráfego de rede não corresponder a uma rota mais específica, normalmente a tabela de roteamento terá uma entrada de rota padrão para toda a Internet com IPv4: 0.0.0.0/0. Essa rota padrão aponta para um roteador em uma sub-rede acessível (ou seja, em uma sub-rede que tenha uma rota mais específica na tabela de roteamento do host).
Se um roteador receber tráfego não endereçado a ele, em vez de ignorá-lo como um host normal, ele o encaminhará com base em sua própria tabela de roteamento. Isso poderá enviar o tráfego diretamente para o host de destino (se o roteador por acaso estiver na sub-rede de destino) ou ele poderá ser encaminhado para outro roteador. Esse processo de encaminhamento continua até que o tráfego atinja o destino final.
ip4network.svg
Tabela 12.4. Exemplo de tabela de roteamento
table_save_4.png
Neste exemplo, o tráfego direcionado para o endereço IP 192.0.2.102 desse host é transmitido diretamente para o destino pela interface sem fio wlo1, pois é o que melhor corresponde à rota 192.0.2.0/24. O tráfego do endereço IP 192.168.5.3 é transmitido diretamente para esse destino pela interface Ethernet enp3s0, pois é o que melhor corresponde à rota 192.168.5.0/24.
O tráfego para o endereço IP 10.2.24.1 é transmitido sem a interface Ethernet enp3s0 para um roteador em 192.168.5.254, que encaminha esse tráfego a seu destino final. Esse tráfego é o que melhor corresponde à rota 0.0.0.0/0, pois não existe uma rota mais específica na tabela de roteamento desse host. O roteador usa sua própria tabela de roteamento para determinar aonde encaminhar esse tráfego a seguir.
Configuração do endereço IPv4 e da rota
Um servidor pode definir automaticamente suas configurações de rede IPv4 no momento da inicialização de um servidor DHCP. Um daemon de cliente local consulta o link das configurações de um servidor e da rede e obtém uma concessão para usar essas configurações por um período específico. Se o cliente não solicitar a renovação da concessão periodicamente, poderá perder suas configurações de rede.
Como alternativa, você pode configurar um servidor para usar a configuração de rede estática. Nesse caso, as configurações de rede são lidas nos arquivos de configuração locais. Você deve obter as configurações corretas do administrador da rede e atualizá-las manualmente, conforme necessário, para evitar conflitos com outros servidores. Redes IPv6
IPv6 destina-se a ser um substituto eventual do protocolo de rede IPv4. Você precisa entender como ele funciona devido ao crescente número de sistemas de produção que usam endereçamento IPv6. Por exemplo, muitos ISPs já usam IPv6 para comunicação interna e redes de gerenciamento de dispositivos, a fim de preservar os escassos endereços IPv4 para fins relacionados aos clientes.
IPv6 também pode ser usado em paralelo com IPv4 em um modelo de pilha dual. Nessa configuração, uma interface de rede pode ter um endereço ou endereços IPv6, bem como endereços IPv4. O Red Hat Enterprise Linux opera no modo de pilha dual por padrão.
Endereços IPv6
Um endereço IPv6 é um número de 128 bits, normalmente expresso como oito grupos separados por dois-pontos de quatro nibbles (semibytes) hexadecimais. Cada nibble representa quatro bits do endereço IPv6, de modo que cada grupo representa 16 bits do endereço IPv6.
2001:0db8:0000:0010:0000:0000:0000:0001
Para facilitar a gravação de endereços IPv6, os zeros à esquerda em um grupo separado por dois-pontos não precisam ser gravados. No entanto, pelo menos um dígito hexadecimal deve ser gravado em cada grupo separado por dois-pontos.
2001:db8:0:10:0:0:0:1
Já que os endereços com cadeias longas de zeros são comuns, um ou mais grupos consecutivos de zeros podem ser combinados com exatamente um bloco ::.
2001:db8:0:10::1
Observe que, sob essas regras, 2001:db8::0010:0:0:0:1 seria outra maneira menos conveniente de gravar o exemplo de endereço. Porém, essa é uma representação válida do mesmo endereço, e isso pode confundir os administradores novos em IPv6. Algumas dicas para gravar endereços que podem ser lidos consistentemente:
Elimine os zeros à esquerda de um grupo.
Use :: para encurtar o máximo possível.
Se um endereço contiver dois grupos consecutivos de zeros, iguais em comprimento, é preferível encurtar os grupos de zeros mais à esquerda para :: e os grupos mais à direita para :0: em cada grupo.
Embora isso seja permitido, não use :: para encurtar um grupo de zeros. Em vez disso, use :0: e deixe :: para grupos consecutivos de zeros.
Sempre use letras minúsculas para números hexadecimais de a até f.
Importante
Ao incluir a porta de rede TCP ou UDP depois de um endereço IPv6, sempre anexe o endereço IPv6 em colchetes de modo que a porta pareça fazer parte dele.
Sub-redes IPv6
Um endereço unicast IPv6 normal é dividido em duas partes: o prefixo de rede e a ID da interface. O prefixo de rede identifica a sub-rede. Não existe a possibilidade de duas interfaces de rede na mesma sub-rede terem a mesma ID de interface; a ID de interface identifica as ameaças de uma interface particular na sub-rede.
Diferentemente de IPv4, IPv6 tem uma máscara de sub-rede padrão que é usada para praticamente todos os endereços normais, /64. Nesse caso, metade do endereço é o prefixo da rede, e metade é a ID de interface. Isso significa que uma única sub-rede pode conter tantos hosts quanto necessários.
Normalmente, o fornecedor de rede alocará um prefixo mais curto a uma organização, como /48. Isso deixa o restante da parte da rede para atribuição de sub-redes (sempre de tamanho /64) a partir do prefixo alocado. Para uma alocação /48, que deixa 16 bits para sub-redes (até 65.536 sub-redes).
ipv6-subnets-plain-fit.png
Tabela 12.5. Endereços e redes IPv6 comuns
table_save_5.png
Importante
A tabela acima lista as alocações de endereços de rede que são reservadas para fins específicos. Essas alocações podem consistir em muitas redes diferentes. Lembre-se de que as redes IPv6 alocadas a partir de espaços unicast global e unicast link-local têm uma máscara de sub-rede padrão /64.
Um endereço link-local no IPv6 é um endereço não roteável usado somente para se comunicar com os hosts em um link de rede específico. Cada interface de rede no sistema é configurada automaticamente com um endereço link-local na rede fe80::/64. Para garantir que seja exclusiva, a ID de interface do endereço link-local é construída a partir do endereço de hardware da Ethernet da interface de rede. O procedimento comum para converter o endereço MAC de 48 bits em uma ID de interface de 64 bits é inverter o bit 7 do endereço MAC e inserir ff:fe entre seus dois bytes intermediários.
Prefixo de rede: fe80::/64
Endereço MAC: 00:11:22:aa:bb:cc
Endereço link-local: fe80::211:22ff:feaa:bbcc/64
Os endereços link-local de outras máquinas podem ser usados como endereços normais por outros hosts no mesmo link. Como cada link tem uma rede fe80::/64 nele, a tabela de roteamento não pode ser usada para selecionar a interface de saída corretamente. O link para usar ao falar com um endereço link-local deve ser especificado com um identificador de escopo no final do endereço. O identificador de escopo consiste em % seguido pelo nome da interface de rede.
Por exemplo, para usar ping6 para fazer ping no endereço link-local fe80::211:22ff:feaa:bbcc usando o link conectado à interface de rede ens3, a sintaxe correta do comando é:
[user@host ~]$ ping6 fe80::211:22ff:feaa:bbcc%ens3
Nota
Os identificadores de escopo são necessários apenas quando os endereços de contato têm o escopo “link”. Os endereços globais normais são usados como no IPv4, selecionando as interfaces de saída na tabela de roteamento.
Multicast permite que um sistema envie tráfego para um endereço IP específico recebido por vários sistemas. É diferente da transmissão, pois apenas sistemas específicos na rede recebem o tráfego. Também é diferente da transmissão em IPv4, já que parte do tráfego multicast pode ser roteado para outras sub-redes, dependendo da configuração de seus sistemas e roteadores de rede.
Multicast exerce uma função maior no IPv6 do que no IPv4 porque não existe um endereço de transmissão em IPv6. Um endereço multicast importante no IPv6 é ff02::1, o endereço link-local de all-nodes. Fazer ping desse endereço envia o tráfego a todos os nós no link. Os endereços multicast link-scope (iniciando com ff02::/8) precisam ser especificados com um identificador de escopo, assim como um endereço link-local.
[user@host ~]$ ping6 ff02::1%ens3 PING ff02::1%ens3(ff02::1) 56 data bytes 64 bytes from fe80::211:22ff:feaa:bbcc: icmp_seq=1 ttl=64 time=0.072 ms 64 bytes from fe80::200:aaff:fe33:2211: icmp_seq=1 ttl=64 time=102 ms (DUP!) 64 bytes from fe80::bcd:efff:fea1:b2c3: icmp_seq=1 ttl=64 time=103 ms (DUP!) 64 bytes from fe80::211:22ff:feaa:bbcc: icmp_seq=2 ttl=64 time=0.079 ms …output omitted…
Configuração do endereço IPv6
O IPv4 tem duas maneiras na qual os endereços são configurados nas interfaces de rede. Os endereços de rede podem ser configurados em interfaces manualmente pelo administrador ou dinamicamente a partir da rede usando DHCP. O IPv6 também dá suporte à configuração manual e a dois métodos de configuração dinâmica, um dos quais é DHCPv6.
As IDs de interface dos endereços IPv6 estáticos podem ser selecionadas por vontade, assim como IPv4. No IPv4, existem dois endereços em uma rede que não podem ser usados: o endereço mais baixo e o mais alto na sub-rede. No IPv6, as IDs de interface a seguir são reservadas e não podem ser usadas em um endereço de rede normal em um host.
O identificador composto somente por zeros 0000:0000:0000:0000 (“subnet router anycast”) usado por todos os roteadores no link (para a rede 2001:db8::/64, seria o endereço 2001:db8::).
Os identificadores fdff:ffff:ffff:ff80 a fdff:ffff:ffff:ffff.
O DHCPv6 funciona de maneira diferente do que o DHCP para IPv4, pois não há endereço de transmissão. Basicamente, um host envia uma solicitação de DHCPv6 de seu endereço link-local para a porta 547/UDP em ff02::1:2, o grupo multicast link-local de all-dhcp-servers. O servidor DHCPv6 então geralmente envia uma resposta com informações apropriadas para a porta 546/UDP no endereço link-local do cliente.
O pacote dhcp no Red Hat Enterprise Linux 8 dá suporte a um servidor DHCPv6.
Além de DHCPv6, o IPv6 também dá suporte a um segundo método de configuração dinâmica, chamado de Configuração automática de endereço sem estado (SLAAC). Usando SLAAC, o host traz sua interface com um endereço link-local fe80::/64 normalmente. Em seguida, ele envia uma “solicitação de roteador” para ff02::2, o grupo multicast link-local de todos os roteadores. Um roteador IPv6 no link local responde ao endereço link-local do host com um prefixo de rede e possivelmente outras informações. O host então usa esse prefixo de rede com uma ID de interface que normalmente constrói da mesma maneira que são construídos os endereços link-local. O roteador envia periodicamente atualizações multicast (“anúncios do roteador”) para confirmar ou atualizar as informações que ele forneceu.
O pacote radvd no Red Hat Enterprise Linux 8 permite que um roteador IPv6 baseado no Red Hat Enterprise Linux forneça SLAAC por meio de anúncios do roteador. Importante
Uma máquina típica do Red Hat Enterprise Linux 8 configurada para obter endereços IPv4 por meio do DHCP geralmente é configurada também para usar SLAAC a fim de obter endereços IPv6. Isso pode resultar em máquinas obtendo inesperadamente endereços IPv6 quando um roteador IPv6 é adicionado à rede.
Algumas implantações de IPv6 combinam SLAAC e DHCPv6, usando SLAAC para somente fornecer informações de endereço da rede e DHCPv6 para fornecer outras informações, como quais servidores DNS e domínios de pesquisa devem ser configurados. Nomes de host e endereços IP
Seria inconveniente se você sempre precisasse usar endereços IP para contatar seus servidores. Normalmente, as pessoas preferem trabalhar com nomes do que com cadeias numéricas longas e difíceis de memorizar. Por isso, o Linux tem vários mecanismos para mapear o nome de host a um endereço IP, coletivamente chamados de resolução de nomes.
Uma maneira de fazer isso é definir uma entrada estática para cada nome no arquivo /etc/hosts de cada sistema. Isso exige a atualização manual da cópia do arquivo de cada servidor.
Na maioria dos hosts, você pode procurar o endereço de um nome de host (ou o nome de host de um endereço) em um serviço de rede chamado de Sistema de nomes de domínio (DNS). DNS é uma rede distribuída de servidores que fornece mapeamentos de nomes de host a endereços IP. Para que o serviço de nomes funcione, o host precisa ser apontado para um nameserver. Esse nameserver não precisa estar na mesma sub-rede, mas apenas ser alcançado pelo host. Normalmente, isso é configurado por meio do DHCP ou de uma configuração estática em um arquivo chamado de /etc/resolv.conf. As seções posteriores deste capítulo explicarão como configurar a resolução de nomes.
Validação da configuração de rede
Objetivos
Depois de concluir esta seção, você deverá ser capaz de testar e inspecionar a configuração de rede atual com utilitários de linha de comando. Coleta das informações da interface de rede
Identificação das interfaces de rede
O comando ip link listará todas as interfaces de rede disponíveis em seu sistema:
[user@host ~]$ ip link show 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 2: ens3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP mode DEFAULT group default qlen 1000 link/ether 52:54:00:00:00:0a brd ff:ff:ff:ff:ff:ff 3: ens4: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP mode DEFAULT group default qlen 1000 link/ether 52:54:00:00:00:1e brd ff:ff:ff:ff:ff:ff
No exemplo anterior, o servidor tem três interfaces de rede: lo, que é o dispositivo de loopback que está conectado ao próprio servidor e duas interfaces de ethernet, ens3 e ens4.
Para configurar cada interface de rede corretamente, você precisa saber qual delas está conectada a qual rede. Em muitos casos, você saberá o endereço MAC da interface conectada a cada rede, seja porque está fisicamente impressa na placa ou no servidor ou porque é uma máquina virtual e você sabe como ela está configurada. O endereço MAC do dispositivo é listado após link/ether para cada interface. Então você sabe que a placa de rede com o endereço MAC 52:54:00:00:00:0a é a interface de rede ens3.
Exibição dos endereços IP
Use o comando ip para visualizar as informações do dispositivo e de endereço. Uma interface de rede única pode ter vários endereços IPv4 ou IPv6.
redes_plan_1.png
Exibindo estatísticas de desempenho
O comando ip também pode ser usado para mostrar as estatísticas sobre o desempenho da rede. É possível usar contadores para cada interface de rede para identificar a presença de problemas de rede. Os contadores registram estatísticas de elementos como o número de pacotes recebidos (RX) e transmitidos (TX), erros de pacotes e pacotes que foram descartados.
[user@host ~]$ ip -s link show ens3 2: ens3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000 link/ether 52:54:00:00:00:0a brd ff:ff:ff:ff:ff:ff RX: bytes packets errors dropped overrun mcast 269850 2931 0 0 0 0 TX: bytes packets errors dropped carrier collsns 300556 3250 0 0 0 0
Verificação da conectividade entre hosts
O comando ping é usado para testar a conectividade. O comando continuará sendo executado até você pressionar Ctrl+c, a menos que sejam indicadas opções para limitar o número de pacotes enviados.
[user@host ~]$ ping -c3 192.0.2.254 PING 192.0.2.1 (192.0.2.254) 56(84) bytes of data. 64 bytes from 192.0.2.254: icmp_seq=1 ttl=64 time=4.33 ms 64 bytes from 192.0.2.254: icmp_seq=2 ttl=64 time=3.48 ms 64 bytes from 192.0.2.254: icmp_seq=3 ttl=64 time=6.83 ms
— 192.0.2.254 ping statistics — 3 packets transmitted, 3 received, 0% packet loss, time 2003ms rtt min/avg/max/mdev = 3.485/4.885/6.837/1.424 ms
O comando ping6 é a versão IPv6 do ping no Red Hat Enterprise Linux. Ele se comunica por IPv6 e obtém endereços IPv6, mas funciona como ping.
[user@host ~]$ ping6 2001:db8:0:1::1 PING 2001:db8:0:1::1(2001:db8:0:1::1) 56 data bytes 64 bytes from 2001:db8:0:1::1: icmp_seq=1 ttl=64 time=18.4 ms 64 bytes from 2001:db8:0:1::1: icmp_seq=2 ttl=64 time=0.178 ms 64 bytes from 2001:db8:0:1::1: icmp_seq=3 ttl=64 time=0.180 ms ^C — 2001:db8:0:1::1 ping statistics — 3 packets transmitted, 3 received, 0% packet loss, time 2001ms rtt min/avg/max/mdev = 0.178/6.272/18.458/8.616 ms [user@host ~]$
Quando você faz ping dos endereços link-local e do grupo multicast link-local para todos os nós (ff02::1), a interface de rede a ser usada deve ser explicitamente especificada com um identificador de zona de escopo (como ff02::1%ens3). Se isso não for feito, será exibido o erro connect: Invalid argument
Fazer o ping de ff02::1 pode ser útil para encontrar outros nós de IPv6 na rede local.
[user@host ~]$ ping6 ff02::1%ens4 PING ff02::1%ens4(ff02::1) 56 data bytes 64 bytes from fe80::78cf:7fff:fed2:f97b: icmp_seq=1 ttl=64 time=22.7 ms 64 bytes from fe80::f482:dbff:fe25:6a9f: icmp_seq=1 ttl=64 time=30.1 ms (DUP!) 64 bytes from fe80::78cf:7fff:fed2:f97b: icmp_seq=2 ttl=64 time=0.183 ms 64 bytes from fe80::f482:dbff:fe25:6a9f: icmp_seq=2 ttl=64 time=0.231 ms (DUP!) ^C — ff02::1%ens4 ping statistics — 2 packets transmitted, 2 received, +2 duplicates, 0% packet loss, time 1001ms rtt min/avg/max/mdev = 0.183/13.320/30.158/13.374 ms [user@host ~]$ ping6 -c 1 fe80::f482:dbff:fe25:6a9f%ens4 PING fe80::f482:dbff:fe25:6a9f%ens4(fe80::f482:dbff:fe25:6a9f) 56 data bytes 64 bytes from fe80::f482:dbff:fe25:6a9f: icmp_seq=1 ttl=64 time=22.9 ms
— fe80::f482:dbff:fe25:6a9f%ens4 ping statistics — 1 packets transmitted, 1 received, 0% packet loss, time 0ms rtt min/avg/max/mdev = 22.903/22.903/22.903/0.000 ms
Lembre-se de que os endereços link-local IPv6 podem ser usados por outros hosts no mesmo link, como endereços normais.
[user@host ~]$ ssh fe80::f482:dbff:fe25:6a9f%ens4 user@fe80::f482:dbff:fe25:6a9f%ens4’s password: Last login: Thu Jun 5 15:20:10 2014 from host.example.com [user@server ~]$
Solução de problemas de roteamento
O roteamento de rede é complexo e, às vezes, o tráfego não se comporta como você espera. Aqui estão algumas ferramentas úteis de diagnóstico.
Exibição da tabela de roteamento
Use o comando ip com a opção route para mostrar as informações de roteamento.
[user@host ~]$ ip route default via 192.0.2.254 dev ens3 proto static metric 1024 192.0.2.0/24 dev ens3 proto kernel scope link src 192.0.2.2 10.0.0.0/8 dev ens4 proto kernel scope link src 10.0.0.11
A tabela de roteamento IPv4 é exibida. Todos os pacotes destinados à rede 10.0.0.0/8 são enviados diretamente para o destino pelo dispositivo ens4. Todos os pacotes destinados à rede 192.0.2.0/24 são enviados diretamente para o destino pelo dispositivo ens3. Todos os outros pacotes são enviados para o roteador padrão, localizado em 192.0.2.254 e também pelo dispositivo ens3.
Adicione a opção -6 para mostrar a tabela de roteamento IPv6:
[user@host ~]$ ip -6 route unreachable ::/96 dev lo metric 1024 error -101 unreachable ::ffff:0.0.0.0/96 dev lo metric 1024 error -101 2001:db8:0:1::/64 dev ens3 proto kernel metric 256 unreachable 2002:a00::/24 dev lo metric 1024 error -101 unreachable 2002:7f00::/24 dev lo metric 1024 error -101 unreachable 2002:a9fe::/32 dev lo metric 1024 error -101 unreachable 2002:ac10::/28 dev lo metric 1024 error -101 unreachable 2002:c0a8::/32 dev lo metric 1024 error -101 unreachable 2002:e000::/19 dev lo metric 1024 error -101 unreachable 3ffe:ffff::/32 dev lo metric 1024 error -101 fe80::/64 dev ens3 proto kernel metric 256 default via 2001:db8:0:1::ffff dev ens3 proto static metric 1024
Nesse exemplo, ignore as rotas inacessíveis, que apontam para redes não utilizadas. Sobram três rotas:
A rede 2001:db8:0:1::/64, usando a interface ens3 (que, presumivelmente, tem um endereço nessa rede).
A rede fe80::/64, usando a interface ens3, para o endereço link-local. Em um sistema com várias interfaces, existe uma rota para fe80::/64 saindo de cada interface para cada endereço link-local.
Uma rota padrão para todas as redes na Internet IPv6 (a rede ::/0) que não tem uma rota mais específica no sistema, por meio do roteador em 2001:db8:0:1::ffff, que pode ser acessado com o dispositivo ens3.
Rastreamento das rotas usadas pelo tráfego
Para rastrear o caminho que o tráfego de rede segue para chegar a um host remoto por meio de diversos roteadores, use traceroute ou tracepath. Eles podem identificar se o problema está em um dos seus roteadores ou em um intermediário. Os dois comandos usam pacotes UDP para rastrear o caminho por padrão. Entretanto, muitas redes bloqueiam os tráfegos UDP e ICMP. O comando traceroute tem opções para rastrear o caminho com pacotes UDP (padrão), ICMP (-I) ou TCP (-T). No entanto, normalmente o comando traceroute não está instalado por padrão.
[user@host ~]$ tracepath access.redhat.com …output omitted… 4: 71-32-28-145.rcmt.qwest.net 48.853ms asymm 5 5: dcp-brdr-04.inet.qwest.net 100.732ms asymm 7 6: 206.111.0.153.ptr.us.xo.net 96.245ms asymm 7 7: 207.88.14.162.ptr.us.xo.net 85.270ms asymm 8 8: ae1d0.cir1.atlanta6-ga.us.xo.net 64.160ms asymm 7 9: 216.156.108.98.ptr.us.xo.net 108.652ms 10: bu-ether13.atlngamq46w-bcr00.tbone.rr.com 107.286ms asymm 12 …output omitted…
Cada linha na saída de tracepath representa um roteador ou um salto que o pacote dá da origem até o destino final. Informações adicionais são fornecidas conforme disponíveis, incluindo o tempo de viagem de ida e volta (RTT) e quaisquer alterações no tamanho da unidade máxima de transmissão (MTU). A indicação asymm significa que o tráfego chegou a esse roteador e retornou do roteador usando rotas diferentes (assimétricas). Os roteadores exibidos são os roteadores usados para o tráfego de saída, não para o tráfego de retorno.
Os comandos tracepath6 e traceroute -6 são equivalentes a tracepath e traceroute para IPv6.
[user@host ~]$ tracepath6 2001:db8:0:2::451 1?: [LOCALHOST] 0.091ms pmtu 1500 1: 2001:db8:0:1::ba 0.214ms 2: 2001:db8:0:1::1 0.512ms 3: 2001:db8:0:2::451 0.559ms reached Resume: pmtu 1500 hops 3 back 3
Solução de problemas de portas e serviços
Os serviços de TCP usam soquetes como pontos finais para comunicação e são compostos de um endereço IP, um protocolo e um número de porta. Os serviços tipicamente escutam as portas padrão, enquanto os clientes usam uma porta disponível aleatoriamente. Nomes de portas padrão bem conhecidos são listados no arquivo /etc/services.
O comando ss é usado para exibir as estatísticas de soquete. O comando ss pretende substituir a antiga ferramenta netstat, parte do pacote net-tools, que talvez seja mais conhecida por alguns administradores de sistema, mas nem sempre está instalada.
redes_plan_2.png
Tabela 12.6. Opções para ss e netstat
table_p2.png
Configuração de redes usando a linha de comando
Objetivos
Depois de concluir esta seção, você deverá ser capaz de gerenciar as configurações de rede e de dispositivos usando o comando nmcli. Descrição de conceitos do NetworkManager
O NetworkManager é um daemon que monitora e gerencia as configurações de rede. Além do daemon, há um applet de área de notificação GNOME que fornece informações de status da rede. As ferramentas gráficas e de linha de comando entram em contato com o NetworkManager e salvam os arquivos de configuração no diretório /etc/sysconfig/network-scripts.
Um dispositivo é uma interface de rede.
Uma conexão é um conjunto de configurações que podem ser definidas para um dispositivo.
Somente uma conexão pode ficar ativa para um dispositivo por vez. É possível haver várias conexões para uso por diferentes dispositivos ou para permitir a alteração de uma configuração no mesmo dispositivo. Se você precisar alterar temporariamente as configurações de rede, em vez de mudar a configuração de uma conexão, poderá alterar qual conexão estará ativa em um dispositivo. Por exemplo, um dispositivo em uma interface de rede sem fio de um laptop pode usar conexões diferentes para a rede sem fio em um local de trabalho e para a rede sem fio em casa.
Cada conexão tem um nome ou uma ID que a identifica.
O utilitário nmcli é usado para criar e editar arquivos de conexão a partir da linha de comando.
Visualização de informações da rede
O comando nmcli dev status mostra o status de todos os dispositivos de rede:
[user@host ~]$ nmcli dev status DEVICE TYPE STATE CONNECTION eno1 ethernet connected eno1 ens3 ethernet connected static-ens3 eno2 ethernet disconnected – lo loopback unmanaged –
O comando nmcli con show exibe a lista de todas as conexões. Para listar somente as conexões ativas, adicione a opção –active.
[user@host ~]$ nmcli con show NAME UUID TYPE DEVICE eno2 ff9f7d69-db83-4fed-9f32-939f8b5f81cd 802-3-ethernet – static-ens3 72ca57a2-f780-40da-b146-99f71c431e2b 802-3-ethernet ens3 eno1 87b53c56-1f5d-4a29-a869-8a7bdaf56dfa 802-3-ethernet eno1 [user@host ~]$ nmcli con show –active NAME UUID TYPE DEVICE static-ens3 72ca57a2-f780-40da-b146-99f71c431e2b 802-3-ethernet ens3 eno1 87b53c56-1f5d-4a29-a869-8a7bdaf56dfa 802-3-ethernet eno1
Adição de uma conexão de rede
O comando nmcli con add é usado para adicionar novas conexões de rede. Os exemplos de comandos nmcli con add a seguir pressupõem que o nome da conexão de rede que está sendo adicionada não está em uso.
O comando a seguir adiciona uma nova conexão denominada eno2 à interface eno2, que obtém informações da rede IPv4 usando o DHCP e faz a conexão automática durante a inicialização. Ele também obtém as configurações de rede IPv6 escutando os anúncios do roteador no link local. O nome do arquivo de configuração é baseado no valor da opção con-name, eno2, e é salvo no arquivo /etc/sysconfig/network-scripts/ifcfg-eno2.
[root@host ~]# nmcli con add con-name eno2 type ethernet ifname eno2
O próximo exemplo cria uma conexão eno2 para o dispositivo eno2 com um endereço IPv4 estático, usando o endereço IPv4 e o prefixo de rede 192.168.0.5/24 com o gateway padrão 192.168.0.254, mas ainda se conecta automaticamente na inicialização e salva sua configuração no mesmo arquivo. Devido a limitações de tamanho da tela, encerre a primeira linha com um escape \ de shell e complete o comando na próxima linha.
[root@host ~]# nmcli con add con-name eno2 type ethernet ifname eno2
ipv4.address 192.168.0.5/24 ipv4.gateway 192.168.0.254
O exemplo final cria uma conexão eno2 para o dispositivo eno2 com endereços IPv6 e IPv4 estáticos, usando o endereço IPv6 e o prefixo de rede 2001:db8:0:1::c000:207/64 com o gateway IPv6 padrão 2001:db8:0:1::1, e o endereço IPv4 e o prefixo de rede 192.0.2.7/24 com o gateway IPv4 padrão 192.0.2.1, mas ainda faz a conexão automática e salva sua configuração em /etc/sysconfig/network-scripts/ifcfg-eno2. Devido a limitações de tamanho da tela, encerre a primeira linha com um escape \ de shell e complete o comando na próxima linha.
[root@host ~]# nmcli con add con-name eno2 type ethernet ifname eno2
ipv6.address 2001:db8:0:1::c000:207/64 ipv6.gateway 2001:db8:0:1::1
ipv4.address 192.0.2.7/24 ipv4.gateway 192.0.2.1
Controle de conexões de rede
O comando nmcli con up name ativa o nome da conexão na interface de rede à qual está vinculada. Observe que o comando assume o nome de uma conexão, não o nome da interface de rede. Lembre-se de que o comando nmcli con show exibe os nomes de todas as conexões disponíveis.
[root@host ~]# nmcli con up static-ens3
O comando nmcli dev disconnect device desconecta o dispositivo da interface de rede e o deixa inoperante. Este comando pode ser abreviado como nmcli dev dis device:
[root@host ~]# nmcli dev dis ens3
Importante
Use nmcli dev dis device para desativar uma interface de rede.
Normalmente, o comando nmcli con down name não é a melhor maneira de desativar uma interface de rede porque ele interrompe a conexão. No entanto, por padrão, a maioria das conexões de sistema é configurada com a opção autoconnect habilitada. Isso ativará a conexão assim que a interface de rede estiver disponível. Como a interface de rede da conexão ainda está disponível, nmcli con down name deixa a interface inoperante, mas o NetworkManager a traz de volta imediatamente a menos que a conexão seja totalmente desconectada da interface. Modificação das configurações de conexão de rede
As conexões do NetworkManager têm dois tipos de configuração. Há propriedades de conexão estáticas, configuradas pelo administrador e armazenadas nos arquivos de configuração em /etc/sysconfig/network-scripts/ifcfg-*. Pode haver também dados ativos de conexão, que a conexão obtém de um servidor DHCP e que não estão armazenados de modo persistente.
Para listar as configurações atuais de uma conexão, execute o comando nmcli con show name, em que name é o nome da conexão. As configurações em letras minúsculas são propriedades estáticas que o administrador pode alterar. As configurações em maiúsculas são configurações ativas de uso temporário para essa instância da conexão.
[root@host ~]# nmcli con show static-ens3 connection.id: static-ens3 connection.uuid: 87b53c56-1f5d-4a29-a869-8a7bdaf56dfa connection.interface-name: – connection.type: 802-3-ethernet connection.autoconnect: yes connection.timestamp: 1401803453 connection.read-only: no connection.permissions: connection.zone: – connection.master: – connection.slave-type: – connection.secondaries: connection.gateway-ping-timeout: 0 802-3-ethernet.port: – 802-3-ethernet.speed: 0 802-3-ethernet.duplex: – 802-3-ethernet.auto-negotiate: yes 802-3-ethernet.mac-address: CA:9D:E9:2A:CE:F0 802-3-ethernet.cloned-mac-address: – 802-3-ethernet.mac-address-blacklist: 802-3-ethernet.mtu: auto 802-3-ethernet.s390-subchannels: 802-3-ethernet.s390-nettype: – 802-3-ethernet.s390-options: ipv4.method: manual ipv4.dns: 192.168.0.254 ipv4.dns-search: example.com ipv4.addresses: { ip = 192.168.0.2/24, gw = 192.168.0.254 } ipv4.routes: ipv4.ignore-auto-routes: no ipv4.ignore-auto-dns: no ipv4.dhcp-client-id: – ipv4.dhcp-send-hostname: yes ipv4.dhcp-hostname: – ipv4.never-default: no ipv4.may-fail: yes ipv6.method: manual ipv6.dns: 2001:4860:4860::8888 ipv6.dns-search: example.com ipv6.addresses: { ip = 2001:db8:0:1::7/64, gw = 2001:db8:0:1::1 } ipv6.routes: ipv6.ignore-auto-routes: no ipv6.ignore-auto-dns: no ipv6.never-default: no ipv6.may-fail: yes ipv6.ip6-privacy: -1 (unknown) ipv6.dhcp-hostname: – …output omitted…
O comando nmcli con mod name é usado para alterar as configurações de uma conexão. Essas alterações também são salvas no arquivo /etc/sysconfig/network-scripts/ifcfg-name da conexão. As configurações disponíveis estão documentadas na página de manual nm-settings(5).
Para definir o endereço IPv4 para 192.0.2.2/24 e o gateway padrão para 192.0.2.254 da conexão static-ens3:
[root@host ~]# nmcli con mod static-ens3 ipv4.address 192.0.2.2/24
ipv4.gateway 192.0.2.254
Para definir o endereço IPv6 para 2001:db8:0:1::a00:1/64 e o gateway padrão para 2001:db8:0:1::1 da conexão static-ens3:
[root@host ~]# nmcli con mod static-ens3 ipv6.address 2001:db8:0:1::a00:1/64
ipv6.gateway 2001:db8:0:1::1
Importante
Se uma conexão que receber suas informações de IPv4 de um servidor DHCPv4 for alterada para obtê-las somente de arquivos de configuração estáticos, a configuração ipv4.method também deverá ser alterada de auto para manual.
Da mesma forma, se uma conexão que receber suas informações de IPv6 por SLAAC ou um servidor DHCPv6 for alterada para obtê-las somente de arquivos de configuração estáticos, a configuração ipv6.method também deverá ser alterada de auto ou dhcp para manual.
Caso contrário, a conexão poderá cair ou não ser concluída com êxito quando for ativada ou poderá obter um endereço IPv4 do DHCP ou um endereço IPv6 de SLAAC ou DHCPv6 além do endereço estático.
Diversas configurações podem ter vários valores. Um valor específico pode ser adicionado à ou excluído da lista de uma configuração acrescentando um símbolo de + ou - ao início do nome de configuração. Exclusão de uma conexão de rede
O comando nmcli con del name exclui a conexão denominada nome do sistema, desconectando-a do dispositivo e removendo o arquivo /etc/sysconfig/network-scripts/ifcfg-name.
[root@host ~]# nmcli con del static-ens3
Quem pode modificar as configurações de rede?
O usuário root pode fazer qualquer alteração de configuração de rede necessária com nmcli.
No entanto, usuários regulares que estão conectados no console local também podem fazer várias alterações de configuração de rede no sistema. Eles precisam fazer o login no teclado do sistema para um console virtual baseado em texto ou o ambiente de área de trabalho gráfica para obter esse controle. A lógica por trás disso é que, se alguém estiver fisicamente presente no console do computador, este provavelmente será usado como estação de trabalho ou laptop e poderá precisar configurar, ativar e desativar interfaces de rede com ou sem fio à vontade. Por outro lado, se o sistema é um servidor no data center, geralmente os únicos usuários que fazem login localmente na própria máquina devem ser administradores.
Os usuários regulares que fazem login usando ssh não têm acesso para alterar as permissões de rede sem se tornar root.
Você pode usar o comando nmcli gen permissions para ver quais são as suas permissões atuais.
Sumário de comandos
A tabela a seguir apresenta uma lista dos principais comandos nmcli abordados nesta seção.
nmcli.png
Edição de arquivos de configuração de rede
Objetivos
Depois de concluir esta seção, você deverá ser capaz de modificar a configuração da rede por meio da edição dos arquivos de configuração. Descrição dos arquivos de configuração de conexão
Por padrão, as alterações feitas com nmcli con mod name são salvas automaticamente em /etc/sysconfig/network-scripts/ifcfg-name. Esse arquivo também pode ser editado manualmente com um editor de texto. Depois de fazer isso, execute nmcli con reload de modo que o NetworkManager leia as alterações de configuração.
Por razões de compatibilidade retroativa, as diretivas salvas nesse arquivo possuem nomes e sintaxe diferentes dos nomes nm-settings(5). A tabela a seguir mapeia alguns dos principais nomes de configuração para as diretivas ifcfg-*.
Tabela 12.7. Comparação das diretivas nm-settings e ifcfg-*
Modificação da configuração de rede
Também é possível configurar a rede por meio da edição direta dos arquivos de configuração da conexão. Os arquivos de configuração da conexão controlam as interfaces de software dos dispositivos de rede individuais. Esses arquivos geralmente recebem o nome de /etc/sysconfig/network-scripts/ifcfg-name, onde name se refere ao nome do dispositivo ou da conexão que o arquivo de configuração controla. Os itens a seguir são variáveis padrão encontradas no arquivo usado para a configuração IPv4 estática ou dinâmica.
Tabela 12.8. Opções de configuração de IPv4 para o arquivo ifcfg
ifctg.png
Na configuração estática, variáveis por endereço IP, prefixo e o gateway têm um número ao final. Isso permite que vários conjuntos de valores sejam atribuídos à interface. A variável DNS também tem um número usado para determinar a ordem da consulta quando vários servidores são especificados.
Depois de modificar os arquivos de configuração, execute nmcli con reload para fazer com que o NetworkManager leia as alterações de configuração. A interface ainda precisa ser reiniciada para que as alterações tenham efeito.
[root@host ~]# nmcli con reload [root@host ~]# nmcli con down “static-ens3” [root@host ~]# nmcli con up “static-ens3”
Configuração de nomes de host e resolução de nomes
Objetivos
Depois de concluir esta seção, você deverá ser capaz de configurar o nome do host estático do servidor e sua resolução de nomes e testar os resultados. Alteração do nome do host do sistema
O comando hostname exibe ou modifica temporariamente o nome do host totalmente qualificado do sistema.
[root@host ~]# hostname host.example.com
Um nome do host estático pode ser especificado no arquivo /etc/hostname. O comando hostnamectl é usado para modificar esse arquivo e pode ser utilizado para visualizar o status do nome do host totalmente qualificado do sistema. Se esse arquivo não existir, o nome do host será configurado por uma consulta de DNS reverso quando a interface tiver um endereço IP atribuído.
[root@host ~]# hostnamectl set-hostname host.example.com [root@host ~]# hostnamectl status Static hostname: host.example.com Icon name: computer-vm Chassis: vm Machine ID: f874df04639f474cb0a9881041f4f7d4 Boot ID: 6a0abe03ef0b4a97bcb8afb7b281e4d3 Virtualization: kvm Operating System: Red Hat Enterprise Linux 8.2 (Ootpa) CPE OS Name: cpe:/o:redhat:enterprise_linux:8.2:GA Kernel: Linux 4.18.0-193.el8.x86_64 Architecture: x86-64 [root@host ~]# cat /etc/hostname host.example.com
Importante
No Red Hat Enterprise Linux 7 e posterior, o nome do host estático é armazenado em /etc/hostname. O Red Hat Enterprise Linux 6 e anterior armazena o nome do host como uma variável no arquivo /etc/sysconfig/network. Configuração da resolução de nomes
O resolvedor stub é usado para converter nomes do host em endereços IP ou vice-versa. Ele determina onde procurar com base na configuração do arquivo /etc/nsswitch.conf. Por padrão, o conteúdo do arquivo /etc/hosts é verificado primeiro.
[root@host ~]# cat /etc/hosts 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
172.25.254.254 classroom.example.com 172.25.254.254 content.example.com
O comando getent hosts hostname pode ser usado para testar a resolução do nome do host com o arquivo /etc/hosts.
Se não for possível encontrar uma entrada no arquivo /etc/hosts, por padrão o resolvedor stub procurará o nome do host usando um nameserver DNS. O arquivo /etc/resolv.conf controla como a consulta é realizada:
search: uma lista de nomes de domínio a serem tentados com um nome de host curto. Ele não deve ser definido junto com domain no mesmo arquivo. Caso ambos sejam definidos, a última instância prevalecerá. Consulte resolv.conf(5) para obter detalhes.
nameserver: o endereço IP de um nameserver a ser consultado. Até três diretivas de nameserver poderão ser fornecidas para oferecer backups se uma estiver inoperante.
[root@host ~]# cat /etc/resolv.conf
Generated by NetworkManager
domain example.com search example.com nameserver 172.25.254.254
O NetworkManager atualiza o arquivo /etc/resolv.conf usando as configurações de DNS nos arquivos de configuração da conexão. Use o comando nmcli para modificar as conexões.
[root@host ~]# nmcli con mod ID ipv4.dns IP [root@host ~]# nmcli con down ID [root@host ~]# nmcli con up ID [root@host ~]# cat /etc/sysconfig/network-scripts/ifcfg-ID …output omitted… DNS1=8.8.8.8 …output omitted…
O comportamento padrão de nmcli con mod ID ipv4.dns IP é substituir as configurações de DNS pela nova lista de IP fornecida. Um símbolo de + ou - antes do argumento ipv4.dns adiciona ou remove uma entrada individual.
[root@host ~]# nmcli con mod ID +ipv4.dns IP
Para adicionar o servidor DNS com endereço IPv6 2001:4860:4860::8888 à lista de nameservers para usar com a conexão static-ens3:
[root@host ~]# nmcli con mod static-ens3 +ipv6.dns 2001:4860:4860::8888
Nota
Todas as configurações DNS IPv4 e IPv6 estáticas terminam como diretivas de nameserver em /etc/resolv.conf. Você deve garantir que haja, no mínimo, um servidor de nomes acessível por IPv4 listado (em um sistema de pilha dual). É melhor ter, pelo menos, um servidor de nomes que use IPv4 e outro que use IPv6 caso você tenha problemas com a rede IPv4 ou IPv6.
Teste da resolução de nomes DNS
O comando host HOSTNAME pode ser usado para testar a conectividade do servidor de DNS.
[root@host ~]# host classroom.example.com classroom.example.com has address 172.25.254.254 [root@host ~]# host 172.25.254.254 254.254.25.172.in-addr.arpa domain name pointer classroom.example.com.
Importante
O DHCP regrava automaticamente o arquivo /etc/resolv.conf quando as interfaces são iniciadas, a menos que você especifique PEERDNS=no nos arquivos de configuração de interface relevantes. Estabeleça essa definição usando o comando nmcli.
[root@host ~]# nmcli con mod “static-ens3” ipv4.ignore-auto-dns yes
Capítulo 13. Arquivamento e transferência de arquivos
Gerenciamento de arquivos tar compactados Objetivos
Depois de concluir esta seção, você deverá ser capaz de arquivar arquivos e diretórios em um arquivo compactado usando tar e extrair o conteúdo de um arquivo tar existente. O comando tar
Arquivos compactados são úteis na criação de backups e na transferência de dados através de uma rede. Um dos comandos mais antigos e mais comuns para criar e trabalhar com arquivos de backup é o comando tar.
Com o tar, os usuários podem reunir grandes conjuntos de arquivos em um único arquivo (arquivo compactado). Um arquivo tar é uma sequência estruturada de dados de arquivos misturados com metadados sobre cada arquivo e um índice para que arquivos individuais possam ser extraídos. O arquivo compactado pode ser feito com compactação gzip, bzip2 ou xz.
O comando tar também lista o conteúdo de arquivos compactados ou extrai os respectivos arquivos no sistema atual. Opções selecionadas do tar
As opções do comando tar são divididas em operações (a ação que você deseja executar): opções gerais e opções de compactação. A tabela abaixo mostra opções comuns, versão longa das opções e sua descrição:
Tabela 13.1. Visão geral das operações de tar
tar_a1.png
Tabela 13.2. Opções gerais selecionadas do tar
tar_a2.png
Tabela 13.3. Visão geral das opções de compactação tar
tar_a3.png
Opções de listagem do comando tar
O comando tar espera uma das seguintes três opções:
Use a opção -c ou --create para criar um arquivo.
Use a opção -t ou --list para listar o conteúdo de um arquivo compactado.
Use a opção -x ou --extract para extrair um arquivo compactado.
Outras opções normalmente usadas são:
Use a opção -f ou --file= com um nome de arquivo como argumento do arquivo a ser operado.
Use a opção -v ou --verbose para detalhamento; útil para saber quais arquivos são adicionados ou extraídos no arquivo compactado.
Nota
O comando tar na verdade é compatível com um terceiro estilo de opção antigo que usa o padrão de opções de letra única opções sem - à esquerda. Ainda é comumente encontrado, e você pode se deparar com essa sintaxe ao trabalhar com instruções ou comandos de outras pessoas. O comando info tar ‘old options’ discute mais aprofundadamente como isso difere das opções curtas normais.
Você pode ignorar opções antigas por enquanto e focar na sintaxe padrão de opções curtas e longas. Arquivamento de arquivos e diretórios
A primeira opção a ser usada durante a criação de um novo arquivo compactado é c, seguida pela opção f, seguida então de um único espaço, depois o nome do arquivo a ser criado e, finalmente, a lista de arquivos e diretórios que devem ser adicionados ao arquivo compactado. O arquivo compactado é criado no diretório atual, a menos que especificado de outra maneira. Atenção
Antes de criar um arquivo compactado tar, verifique se não há outro arquivo no diretório com o mesmo nome do arquivo a ser criado. O comando tar substitui um arquivo existente sem qualquer aviso.
O comando a seguir cria um arquivo compactado chamado archive.tar com o conteúdo de file1, file2 e file3 no diretório pessoal do usuário.
[user@host ~]$ tar -cf archive.tar file1 file2 file3 [user@host ~]$ ls archive.tar archive.tar
O comando tar acima também pode ser executado usando as opções de versão longa.
[user@host ~]$ tar –file=archive.tar –create file1 file2 file3
Nota
Durante o arquivamento de arquivos com nomes de caminho absolutos, a / à esquerda do caminho é removida do nome de arquivo por padrão. Remover o / à esquerda do caminho ajuda os usuários a evitar a substituição de arquivos importantes ao extrair o arquivo. O comando tar extrai arquivos em relação ao diretório de trabalho atual.
Para que o tar possa arquivar os arquivos selecionados, o usuário que executa o comando tar pode ler os arquivos. Por exemplo, a criação de um novo arquivo da pasta /etc e todo o seu conteúdo exige privilégios root, porque somente o usuário root tem permissão para ler os arquivos presentes nesse diretório /etc. Um usuário sem privilégios pode criar um arquivo compactado do diretório /etc mas o arquivo compactado omite os arquivos que não incluem permissão de leitura para o usuário, bem como os diretórios que não incluem as permissões de leitura e execução para o usuário.
Para criar, como usuário root, o arquivo compactado tar chamado /root/etc.tar com o diretório /etc como conteúdo:
[root@host ~]# tar -cf /root/etc.tar /etc tar: Removing leading `/’ from member names [root@host ~]#
Importante
Algumas permissões avançadas que não cobrimos neste curso, como ACLs e contextos SELinux, não são armazenadas automaticamente em um arquivo compactado tar. Use a opção –xattrs ao criar um arquivo compactado para armazenar os atributos estendidos no arquivo compactado tar. Listagem do conteúdo de um arquivo compactado
A opção t direciona tar para listar o conteúdo (índice, portanto t) do arquivo compactado. Use a opção f com o nome do arquivo compactado a ser consultado. Por exemplo:
[root@host ~]# tar -tf /root/etc.tar etc/ etc/fstab etc/crypttab etc/mtab …output omitted…
Extração de arquivos a partir de um arquivo compactado
Geralmente, um arquivo compactado tar deverá ser extraído em um diretório vazio, para garantir que não substitua arquivos existentes. Quando o root extrai um arquivo, o comando tar preserva o usuário original e a propriedade do grupo dos arquivos. Se um usuário comum extrair arquivos usando tar, a propriedade do arquivo pertence ao usuário que está extraindo os arquivos do arquivo compactado.
Para restaurar arquivos do arquivo compactado /root/etc.tar para o diretório /root/etcbackup, execute:
[root@host ~]# mkdir /root/etcbackup [root@host ~]# cd /root/etcbackup [root@host etcbackup]# tar -tf /root/etc.tar etc/ etc/fstab etc/crypttab etc/mtab …output omitted… [root@host etcbackup]# tar -xf /root/etc.tar
Por padrão, quando os arquivos são extraídos de um arquivo compactado, o umask é subtraído das permissões do conteúdo do arquivo compactado. Para preservar as permissões de um arquivo compactado, use a opção p durante a extração de um arquivo compactado.
No exemplo, um arquivo compactado chamado /root/myscripts.tar é extraído para o diretório /root/scripts ao preservar as permissões dos arquivos extraídos:
[root@host ~]# mkdir /root/scripts [root@host ~]# cd /root/scripts [root@host scripts]# tar -xpf /root/myscripts.tar
Criação de um arquivo compactado
O comando tar é compatível com três métodos de compactação. Existem três métodos de compactação diferentes suportados pelo comando tar. A compactação gzip é a compactação mais rápida, mais antiga e de maior disponibilidade nas distribuições e até nas plataformas. A compactação bzip2 cria arquivos de compactação menores em comparação à gzip, mas é menos disponível que a gzip, embora o método de compactação xz seja relativamente novo, mas geralmente ofereça a melhor taxa de compactação dos métodos disponíveis. Nota
A eficácia de qualquer algoritmo de compactação depende do tipo dos dados a serem compactados. Arquivos de dados que já estão compactados, como formatos de imagem compactados ou arquivos RPM, geralmente levam a uma taxa de compactação mais baixa.
É uma boa prática usar um único diretório de nível superior, que pode conter outros arquivos e diretórios, para simplificar a extração de arquivos de forma organizada.
Use uma das seguintes opções para criar um arquivo compactado tar:
-z ou --gzip para compactação gzip (filename.tar.gz ou filename.tgz)
-j ou --bzip2 para compactação bzip2 (filename.tar.bz2)
-J ou -xz para compactação xz (filename.tar.xz)
Para criar um arquivo compactado gzip chamado /root/etcbackup.tar.gz, com o conteúdo do diretório /etc no host:
[root@host ~]# tar -czf /root/etcbackup.tar.gz /etc tar: Removing leading `/’ from member names
Para criar um arquivo compactado bzip2 chamado /root/logbackup.tar.bz2, com o conteúdo do diretório /var/log no host:
[root@host ~]$ tar -cjf /root/logbackup.tar.bz2 /var/log tar: Removing leading `/’ from member names
Para criar um arquivo compactado xz chamado /root/sshconfig.tar.xz, com o conteúdo do diretório /etc/ssh no host:
[root@host ~]$ tar -cJf /root/sshconfig.tar.xz /etc/ssh tar: Removing leading `/’ from member names
Depois de criar um arquivo compactado, verifique o conteúdo usando as opções tf. Não é obrigatório usar a opção para agente de compactação ao listar o conteúdo de um arquivo compactado. Por exemplo, para listar o conteúdo compactado no arquivo /root/etcbackup.tar.gz, que usa a compactação gzip, use o seguinte comando:
[root@host ~]# tar -tf /root/etcbackup.tar.gz /etc etc/ etc/fstab etc/crypttab etc/mtab …output omitted…
Extração de um arquivo compactado
A primeira etapa durante a extração de um arquivo compactado tar é determinar onde os arquivos compactados devem ser extraídos, criar e passar para o diretório de destino. O comando tar determina qual compactação foi usada e, em geral, não é necessário usar a mesma opção de compactação usada na criação do arquivo compactado. É válido adicionar o método de descompactação ao comando tar. Se escolher fazer isso, a opção do tipo de descompactação correta deve ser usada; caso contrário, o tar produz um erro sobre o tipo de descompactação especificado nas opções que não correspondem ao tipo de descompactação do arquivo.
Para extrair o conteúdo de um arquivo compactado gzip chamado /root/etcbackup.tar.gz no diretório /tmp/etcbackup:
[root@host ~]# mkdir /tmp/etcbackup [root@host ~]# cd /tmp/etcbackup [root@host etcbackup]# tar -tf /root/etcbackup.tar.gz etc/ etc/fstab etc/crypttab etc/mtab …output omitted… [root@host etcbackup]# tar -xzf /root/etcbackup.tar.gz
Para extrair o conteúdo de um arquivo compactado bzip2 chamado /root/logbackup.tar.bz2 no diretório /tmp/logbackup:
[root@host ~]# mkdir /tmp/logbackup [root@host ~]# cd /tmp/logbackup [root@host logbackup]# tar -tf /root/logbackup.tar.bz2 var/log/ var/log/lastlog var/log/README var/log/private/ var/log/wtmp var/log/btmp …output omitted… [root@host logbackup]# tar -xjf /root/logbackup.tar.bz2
Para extrair o conteúdo de um arquivo compactado xz chamado /root/sshbackup.tar.xz no diretório /tmp/sshbackup:
[root@host ~]$ mkdir /tmp/sshbackup [root@host ~]# cd /tmp/sshbackup [root@host logbackup]# tar -tf /root/sshbackup.tar.xz etc/ssh/ etc/ssh/moduli etc/ssh/ssh_config etc/ssh/ssh_config.d/ etc/ssh/ssh_config.d/05-redhat.conf etc/ssh/sshd_config …output omitted… [root@host sshbackup]# tar -xJf /root/sshbackup.tar.xz
Listar um arquivo compactado tar funciona da mesma forma que listar um arquivo descompactado tar. Nota
Além disso, gzip, bzip2 e xz podem ser usados independentemente para compactar arquivos individuais. Por exemplo, o comando gzip etc.tar resulta no arquivo compactado etc.tar.gz, enquanto o comando bzip2 abc.tar resulta no arquivo compactado abc.tar.bz2, e o comando xz myarchive.tar resulta no arquivo compactado myarchive.tar.xz.
Os comandos de descompactação correspondentes são gunzip, bunzip2 e unxz. Por exemplo, o comando gunzip /tmp/etc.tar.gz resulta no arquivo tar descompactado etc.tar, enquanto o comando bunzip2 abc.tar.bz2 resulta no arquivo tar descompactado abc.tar, e o comando unxz myarchive.tar.xz resulta no arquivo tar descompactado myarchive.tar.
Transferência de arquivos entre sistemas com segurança
Objetivos
Depois de concluir esta seção, você deverá ser capaz de transferir arquivos de e para um sistema remoto com segurança usando o SSH. Transferência de arquivos usando cópia segura
O OpenSSH é útil para a execução segura de comandos shell em sistemas remotos. O comando de cópia segura, scp, parte do conjunto OpenSSH, copia arquivos de um sistema remoto para o sistema local ou do sistema local para um sistema remoto. O comando usa o servidor SSH para autenticação e criptografa dados durante a transferência.
Você pode especificar um local remoto para a origem ou o destino dos arquivos que está copiando. O formato da localização remota deve ser [user@]host:/path. A porção user@ do argumento é opcional. Se estiver faltando, seu nome de usuário local atual será usado. Quando você executa o comando, seu cliente scp autenticará para o servidor SSH remoto assim como ssh, usando autenticação baseada em chave ou solicitando sua senha.
O seguinte exemplo mostra como copiar os arquivos locais /etc/yum.conf e /etc/hosts no host com segurança para o diretório pessoal do remoteuser no sistema remoto remotehost:
[user@host ~]$ scp /etc/yum.conf /etc/hosts remoteuser@remotehost:/home/remoteuser remoteuser@remotehost’s password: password yum.conf 100% 813 0.8KB/s 00:00 hosts 100% 227 0.2KB/s 00:00
Você também pode copiar um arquivo na outra direção, de um sistema remoto para o sistema de arquivos local. Neste exemplo, o arquivo /etc/hostname em remotehost é copiado para o diretório local /home/user. O comando scp autentica para o remotehost como o usuário remoteuser.
[user@host ~]$ scp remoteuser@remotehost:/etc/hostname /home/user remoteuser@remotehost’s password: password hostname 100% 22 0.0KB/s 00:00
Para copiar toda uma árvore de diretório recursivamente, use a opção -r. No exemplo a seguir, o nome do diretório remoto /var/log no remotehost é copiado recursivamente para o diretório local /tmp/ no host. Você deve se conectar ao sistema remoto como root para ter certeza de que pode ler todos os arquivos no diretório remoto /var/log.
[user@host ~]$ scp -r root@remoteuser:/var/log /tmp root@remotehost’s password: password …output omitted…
Transferência de arquivos usando o programa de transferência segura de arquivos
Para fazer o upload ou o download de arquivos de maneira interativa a partir de um servidor SSH, use o comando sftp. Uma sessão com o comando sftp usa o mecanismo de autenticação segura e transferência de dados criptografados de e para um servidor SSH.
Assim como com o comando scp, o comando sftp usa [user@]host para identificar o sistema de destino e o nome do usuário. Se você não especificar um usuário, o comando tentará fazer login usando seu nome de usuário local como o nome de usuário remoto. Será então exibida uma solicitação sftp>.
[user@host ~]$ sftp remoteuser@remotehost remoteuser@remotehost’s password: password Connected to remotehost. sftp>
A sessão interativa sftp aceita vários comandos que funcionam no sistema de arquivos remoto da mesma forma como funcionam no sistema de arquivos local, como ls, cd, mkdir, rmdir e pwd. O comando put faz o upload de um arquivo para o sistema remoto. O comando get faz o download de um arquivo para o sistema remoto. O comando exit sai da sessão sftp.
Para fazer upload do arquivo /etc/hosts no sistema local para o diretório recém-criado /home/remoteuser/hostbackup no remotehost. A sessão sftp sempre supõe que o comando put é seguido de um arquivo no sistema de arquivos local e inicia no diretório pessoal do usuário em conexão; neste caso, /home/remoteuser:
sftp> mkdir hostbackup sftp> cd hostbackup sftp> put /etc/hosts Uploading /etc/hosts to /home/remoteuser/hostbackup/hosts /etc/hosts 100% 227 0.2KB/s 00:00 sftp>
Para fazer download de /etc/yum.conf do host remoto para o diretório atual no sistema local, execute o comando get /etc/yum.conf e saia da sessão sftp com o comando exit.
sftp> get /etc/yum.conf Fetching /etc/yum.conf to yum.conf /etc/yum.conf 100% 813 0.8KB/s 00:00 sftp> exit [user@host ~]$
Sincronização segura de arquivos entre sistemas
Objetivos
Depois de concluir esta seção, você deverá ser capaz de sincronizar o conteúdo de um arquivo ou diretório local com uma cópia no servidor remoto, de modo seguro e eficiente. Sincronizar arquivos e pastas com rsync
O comando rsync é outra maneira de copiar arquivos com segurança de um sistema para outro. A ferramenta usa um algoritmo que minimiza a quantidade de dados copiados, sincronizando somente as partes dos arquivos que foram alteradas. A diferença em relação ao scp é que, se dois arquivos ou diretórios forem semelhantes entre dois servidores, o rsync copia apenas as diferenças entre os sistemas de arquivos, enquanto o scp copiará tudo.
Uma vantagens do rsync é que ele pode copiar arquivos entre um sistema local e um sistema remoto com segurança e eficiência. Enquanto a sincronização inicial do diretório leva mais ou menos o tempo de uma cópia, as sincronizações subsequentes somente exigem que as diferenças sejam copiadas pela rede, acelerando significativamente as atualizações.
Uma opção importante do rsync é a opção -n para execução de um dry run. Um dry run é uma simulação do que acontece quando o comando é executado. O dry run mostra as mudanças que rsync realiza quando o comando é executado normalmente. Execute um dry run antes de uma operação rsync real para garantir que arquivos importantes não sejam substituídos ou excluídos.
Duas opções comuns na sincronização com o rsync são as opções -v e -a.
As opções -v ou –verbose fornecem saída mais detalhada. Isso é útil para solucionar problemas e visualizar o progresso ao vivo.
As opções -a ou –archive ativam o “modo de arquivo compactado”. Isso permite a cópia recursiva e ativa um grande número de opções úteis que preservam a maioria das características dos arquivos. O modo de arquivo compactado é o mesmo que especificar as seguintes opções:
Tabela 13.4. Opções habilitadas com rsync -a (modo de arquivo compactado)
sync_a1.png
O modo de arquivo compactado não preserva links físicos porque isso pode adicionar um tempo significativo à sincronização. Se você desejar preservar os links físicos também, adicione a opção -H. Nota
Se você estiver usando permissões avançadas, poderá precisar de duas opções adicionais:
-A para preservar as ACLs
-X para preservar os contextos do SELinux
Você pode usar rsync para sincronizar o conteúdo de um arquivo ou diretório locais com um arquivo ou diretório em uma máquina remota, usando qualquer uma das máquinas como a origem. Você também pode sincronizar o conteúdo de dois arquivos ou diretórios locais.
Por exemplo, para sincronizar o conteúdo do diretório /var/log com o diretório /tmp:
[user@host ~]$ su - Password: password [root@host ~]# rsync -av /var/log /tmp receiving incremental file list log/ log/README log/boot.log …output omitted… log/tuned/tuned.log
sent 11,592,423 bytes received 779 bytes 23,186,404.00 bytes/sec total size is 11,586,755 speedup is 1.00 [user@host ~]$ ls /tmp log ssh-RLjDdarkKiW1 [user@host ~]$
Uma barra à direita do diretório de origem sincroniza o conteúdo do diretório sem criar um subdiretório no diretório de destino. Neste exemplo, o diretório log não é criado no diretório /tmp, somente o conteúdo do /var/log/ é sincronizado no /tmp.
[root@host ~]# rsync -av /var/log/ /tmp sending incremental file list ./ README boot.log …output omitted… tuned/tuned.log
sent 11,592,389 bytes received 778 bytes 23,186,334.00 bytes/sec total size is 11,586,755 speedup is 1.00 [root@host ~]# ls /tmp anaconda dnf.rpm.log-20190318 private audit dnf.rpm.log-20190324 qemu-ga boot.log dnf.rpm.log-20190331 README …output omitted…
Importante
Ao digitar o diretório de origem no comando rsync, a presença da barra à direita no nome do diretório é significativa. Ela determina se o diretório ou apenas o conteúdo do diretório será sincronizado no destino.
O preenchimento com Tab no Bash adiciona automaticamente uma barra à direita nos nomes de diretórios.
Como com os comandos scp e sftp, o rsync especifica locais remotos usando o formato [user@]host:/path. O local remoto pode ser o sistema de origem ou de destino, mas uma das duas máquinas deve ser local.
Para preservar a propriedade do arquivo, você deve ser o root no sistema de destino. Se o destino for remoto, autentique como o root. Se o destino é local, você deve executar rsync como o root .
Neste exemplo, sincronize o diretório local /var/log com o diretório /tmp no sistema remotehost:
[root@host ~]# rsync -av /var/log remotehost:/tmp root@remotehost’s password: password receiving incremental file list log/ log/README log/boot.log …output omitted… sent 9,783 bytes received 290,576 bytes 85,816.86 bytes/sec total size is 11,585,690 speedup is 38.57
Da mesma forma, o diretório remoto /var/log no remotehost pode ser sincronizado com o diretório local /tmp no host:
[root@host ~]# rsync -av remotehost:/var/log /tmp root@remotehost’s password: password receiving incremental file list log/boot.log log/dnf.librepo.log log/dnf.log …output omitted…
sent 9,783 bytes received 290,576 bytes 85,816.86 bytes/sec total size is 11,585,690 speedup is 38.57
Capítulo 14. Instalação e atualização de pacotes de software
Registro de sistemas no Red Hat Support
Objetivos
Depois de concluir esta seção, você deverá ser capaz de registrar um sistema em sua conta da Red Hat e atribuir direitos para atualizações de software e serviços de suporte usando o Red Hat Subscription Management. Red Hat Subscription Management
O Red Hat Subscription Management oferece ferramentas que podem ser usadas para autorizar máquinas a obter subscrições de produtos, permitindo aos administradores receber atualizações de pacotes de software e rastrear informações sobre contratos de suporte e subscrições usadas pelos sistemas. Ferramentas padrão, como PackageKit e yum, podem obter pacotes e atualizações de software por meio de uma rede de distribuição de conteúdo fornecida pela Red Hat.
Existem quatro tarefas básicas realizadas com as ferramentas do Red Hat Subscription Management:
Registrar um sistema para associá-lo a uma conta da Red Hat. Isso permite que o Subscription Manager gere um identificador único para o sistema no inventário. Quando não estiver mais em uso, o registro do sistema poderá ser cancelado.
Subscrever um sistema para autorizar que ele receba atualizações de produtos Red Hat selecionados. As subscrições apresentam níveis de suporte, datas de vencimento e repositórios padrão específicos. As ferramentas podem ser usadas para conectar automaticamente ou selecionar um determinado direito. Conforme mudanças nas necessidades, as subscrições podem ser removidas.
Ativar repositórios para fornecer pacotes de software. Vários repositórios são ativados por padrão com cada subscrição, mas outros repositórios, como atualizações ou código-fonte, poderão ser ativados ou desativados conforme necessário.
Revisar e rastrear os direitos que estão disponíveis ou estão sendo consumidos. As informações de subscrição podem ser exibidas localmente em um sistema específico ou, para uma conta, na página de subscrições do Red Hat Customer Portal ou no Subscription Asset Manager (SAM).
Registro de um sistema
Existem várias maneiras diferentes de registrar um sistema com o Red Hat Customer Portal. Existe uma interface gráfica que você pode acessar com um aplicativo GNOME ou no serviço do console da web e há uma ferramenta de linha de comando.
Para registrar um sistema usando o aplicativo GNOME, inicie o Red Hat Subscription Manager selecionando Activities. Digite subscription no campo Type to search… e clique em Red Hat Subscription Manager. Digite a senha apropriada quando for solicitada a autenticação. A janela Subscriptions é exibida:
cockpit_start.png
Essa caixa de diálogo registra um sistema em um servidor de subscrições. Por padrão, ele registra o servidor para o Red Hat Customer Portal. Forneça Login e Password da conta do Red Hat Customer Portal em que deseja registrar o sistema e clique no botão Register.
Quando registrado, o sistema automaticamente tem uma subscrição conectada se houver uma disponível.
Depois que o sistema é registrado e uma subscrição atribuída, feche a janela Subscriptions. O sistema agora está corretamente subscrito e pronto para receber atualizações ou instalar novos softwares da Red Hat. Registro da linha de comando
Use subscription-manager(8) para registrar um sistema sem usar um ambiente gráfico. O comando subscription-manager pode anexar automaticamente um sistema às subscrições mais compatíveis com ele.
Registre um sistema em uma conta da Red Hat:
[user@host ~]$ subscription-manager register --username=yourusername \
--password=yourpassword
Exibir as subscrições disponíveis:
[user@host ~]$ subscription-manager list --available | less
Conectar automaticamente uma subscrição:
[user@host ~]$ subscription-manager attach --auto
Como alternativa, anexe uma subscrição de um pool específico da lista de subscrições disponíveis:
[user@host ~]$ subscription-manager attach --pool=poolID
Exibir as subscrições consumidas:
[user@host ~]$ subscription-manager list --consumed
Cancelar o registro de um sistema:
[user@host ~]$ subscription-manager unregister
Nota
O subscription-manager também pode ser usado em conjunto com chaves de ativação, o que permite registrar e atribuir subscrições predefinidas sem usar um nome de usuário ou uma senha. Esse método de registro pode ser bastante útil para instalações e implantações automatizadas. As chaves de ativação geralmente são emitidas por um serviço de gerenciamento de subscrições no local, como o Subscription Asset Manager ou Red Hat Satellite, e não são abordadas detalhadamente neste curso. Certificados de direito
Um direito é uma subscrição que foi anexada a um sistema. Certificados digitais são usados para armazenar informações atuais sobre os direitos no sistema local. Depois de registrados, os certificados de direito são armazenados em /etc/pki e em seus subdiretórios.
/etc/pki/product contém os certificados que indicam quais produtos Red Hat estão instalados no sistema.
/etc/pki/consumer contém os certificados que identificam a conta da Red Hat na qual o sistema está registrado.
/etc/pki/entitlement contém os certificados que indicam quais subscrições estão anexadas ao sistema.
Os certificados podem ser inspecionados diretamente com o utilitário rct, mas as ferramentas do subscription-manager oferecem maneiras mais fáceis de examinar as subscrições conectadas ao sistema.
Explicação e investigação de pacotes de software RPM
Objetivos
Depois de concluir esta seção, você deverá ser capaz de explicar como o software é fornecido como pacotes RPM e investigar os pacotes instalados no sistema com o YUM e o RPM. Pacotes de software e RPM
Originalmente, a Red Hat desenvolveu o RPM Package Manager, que oferece uma forma padrão para o empacotamento de software para distribuição. O gerenciamento de software na forma de pacotes RPM é muito mais simples do que o trabalho com software simplesmente extraído para um sistema de arquivos a partir de um arquivo compactado. Ele permite que os administradores rastreiem quais arquivos foram instalados pelo pacote de software e quais precisarão ser removidos quando ele for desinstalado, bem como verificar se os pacotes de suporte estão presentes quando ele está instalado. As informações sobre pacotes instalados são armazenadas em um banco de dados RPM local em cada sistema. Todo software fornecido pela Red Hat para o Red Hat Enterprise Linux é oferecido como um pacote RPM.
Os nomes dos arquivos do pacote RPM consistem em quatro elementos (com o sufixo .rpm): name-version-release.architecture:
rpm-name-structure.png
NAME é uma ou mais palavras que descrevem o conteúdo (coreutils).
VERSION é o número da versão do software original (8.30).
RELEASE é o número do lançamento do pacote com base na versão, e é definido pelo empacotador, que pode não ser o desenvolvedor de software original (4.el8).
ARCH é a arquitetura do processador para a qual o pacote foi compilado. noarch indica que o conteúdo do pacote não é específico de uma arquitetura (diferentemente de x86_64 para 64 bits, aarch64 para ARM de 64 bits e assim por diante).
Apenas o nome do pacote é necessário para instalar pacotes de repositórios. Se existirem diversas versões, o pacote com o número de versão superior será instalado. Se existirem diversos lançamentos de uma só versão, o pacote com o número superior será instalado.
Cada pacote RPM é um arquivo especial formado por três componentes:
Os arquivos instalados pelo pacote.
As informações sobre o pacote (metadados), como nome, versão, lançamento, arquitetura; um sumário e uma descrição do pacote; se ele exige que outros pacotes sejam instalados; suas licenças; um registro das alterações do pacote; e outros detalhes.
Os scripts que poderão ser executados quando o pacote for instalado, atualizado ou removido, ou ainda os que serão acionados quando os pacotes forem instalados, atualizados ou removidos.
Normalmente, os provedores de software assinam digitalmente os pacotes RPM usando chaves GPG (a Red Hat assina digitalmente todos os pacotes lançados). O sistema RPM verifica a integridade do pacote confirmando se o pacote foi assinado pela chave GPG apropriada. O sistema RPM se recusará a instalar um pacote se a assinatura GPG não corresponder.
Atualização de software com pacotes RPM
A Red Hat gera um pacote RPM completo para atualizar o software. O administrador que instala esse pacote obtém apenas sua versão mais recente. A Red Hat não exige que os pacotes mais antigos sejam instalados e depois corrigidos com patches. Para atualizar o software, o RPM remove a versão mais antiga do pacote e instala a nova versão. As atualizações geralmente mantêm os arquivos de configuração, mas o empacotador da nova versão define o comportamento exato.
Na maioria dos casos, apenas uma versão ou um lançamento de um pacote pode ser instalado por vez. No entanto, se um pacote for compilado de maneira que não haja conflito de nomes de arquivos, várias versões poderão ser instaladas. O exemplo mais importante disso é o pacote kernel. Como só é possível testar um novo kernel com o boot desse kernel específico, o pacote é projetado especificamente para que várias versões possam ser instaladas de uma vez. Se o novo kernel falhar durante o boot, o kernel antigo ainda estará disponível e poderá ser inicializado. Exame dos pacotes RPM
O utilitário rpm é uma ferramenta de nível inferior que pode obter informações sobre o conteúdo de arquivos de pacote e pacotes instalados. Por padrão, ele obtém informações do banco de dados local de pacotes instalados. No entanto, você pode usar a opção -p para especificar que você deseja obter informações sobre um arquivo de pacote baixado. Você pode fazer isso para inspecionar o conteúdo do arquivo do pacote antes de instalá-lo.
A forma geral de uma consulta é:
rpm -q [select-options] [query-options]
Consultas RPM: informações gerais sobre pacotes instalados
rpm -qa: lista todos os pacotes instalados
rpm -qf FILENAME: encontra que pacote fornece o FILENAME
[user@host ~]$ rpm -qf /etc/yum.repos.d
redhat-release-8.0-0.39.el8.x86_64
Consultas RPM: informações sobre pacotes específicos
rpm -q: lista qual versão do pacote está instalada atualmente
[user@host ~]$ rpm -q yum
yum-4.0.9.2-4.el8.noarch
rpm -qi: fornece informações detalhadas sobre um pacote
rpm -ql: lista os arquivos instalados pelo pacote
[user@host ~]$ rpm -ql yum
/etc/yum.conf
/etc/yum/pluginconf.d
/etc/yum/protected.d
/etc/yum/vars
/usr/bin/yum
/usr/share/man/man1/yum-aliases.1.gz
/usr/share/man/man5/yum.conf.5.gz
/usr/share/man/man8/yum-shell.8.gz
/usr/share/man/man8/yum.8.gz
rpm -qc: lista apenas os arquivos de configuração instalados pelo pacote
[user@host ~]$ rpm -qc openssh-clients
/etc/ssh/ssh_config
/etc/ssh/ssh_config.d/05-redhat.conf
rpm -qd: lista apenas os arquivos de documentação instalados pelo pacote
[user@host ~]$ rpm -qd openssh-clients
/usr/share/man/man1/scp.1.gz
/usr/share/man/man1/sftp.1.gz
/usr/share/man/man1/ssh-add.1.gz
/usr/share/man/man1/ssh-agent.1.gz
/usr/share/man/man1/ssh-copy-id.1.gz
/usr/share/man/man1/ssh-keyscan.1.gz
/usr/share/man/man1/ssh.1.gz
/usr/share/man/man5/ssh_config.5.gz
/usr/share/man/man8/ssh-pkcs11-helper.8.gz
rpm -q --scripts: lista os scripts de shell que são executados antes e depois de o pacote ter sido instalado ou removido
[user@host ~]$ rpm -q --scripts openssh-server
preinstall scriptlet (using /bin/sh):
getent group sshd >/dev/null || groupadd -g 74 -r sshd || :
getent passwd sshd >/dev/null || \
useradd -c "Privilege-separated SSH" -u 74 -g sshd \
-s /sbin/nologin -r -d /var/empty/sshd sshd 2> /dev/null || :
postinstall scriptlet (using /bin/sh):
if [ $1 -eq 1 ] ; then
# Initial installation
/usr/bin/systemctl preset sshd.service sshd.socket >/dev/null 2>&1 || :
fi
preuninstall scriptlet (using /bin/sh):
if [ $1 -eq 0 ] ; then
# Package removal, not upgrade
/usr/bin/systemctl --no-reload disable sshd.service sshd.socket > /dev/null 2>&1 || :
/usr/bin/systemctl stop sshd.service sshd.socket > /dev/null 2>&1 || :
fi
postuninstall scriptlet (using /bin/sh):
/usr/bin/systemctl daemon-reload >/dev/null 2>&1 || :
if [ $1 -ge 1 ] ; then
# Package upgrade, not uninstall
/usr/bin/systemctl try-restart sshd.service >/dev/null 2>&1 || :
fi
rpm -q --changelog: lista as informações de alterações do pacote
[user@host ~]$ rpm -q --changelog audit
* Wed Jan 09 2019 Steve Grubb <sgrubb@redhat.com> 3.0-0.10.20180831git0047a6c
resolves: rhbz#1655270] Message "audit: backlog limit exceeded" reported
- Fix annobin failure
* Fri Dec 07 2018 Steve Grubb <sgrubb@redhat.com> 3.0-0.8.20180831git0047a6c
resolves: rhbz#1639745 - build requires go-toolset-7 which is not available
resolves: rhbz#1643567 - service auditd stop exits prematurely
resolves: rhbz#1616428 - Update git snapshot of audit package
- Remove static libs subpackage
...output omitted...
Consulta de arquivos de pacotes:
[user@host ~]$ ls -l wonderwidgets-1.0-4.x86_64.rpm -rw-rw-r–. 1 user user 257 Mar 13 20:06 wonderwidgets-1.0-4.x86_64.rpm [user@host ~]$ rpm -qlp wonderwidgets-1.0-4.x86_64.rpm /etc/wonderwidgets.conf /usr/bin/wonderwidgets /usr/share/doc/wonderwidgets-1.0 /usr/share/doc/wonderwidgets-1.0/README.txt
Instalação de pacotes RPM
O comando rpm também pode ser usado para instalar um pacote RPM que você baixou para seu diretório local.
[root@host ~]# rpm -ivh wonderwidgets-1.0-4.x86_64.rpm Verifying… ################################# [100%] Preparing… ################################# [100%] Updating / installing… 1:wonderwidgets-1.0-4 ################################# [100%] [root@host ~]#
No entanto, a próxima seção deste capítulo discutirá uma ferramenta mais avançada para gerenciar a instalação e as atualizações do RPM a partir da linha de comando, yum. Atenção
Tenha cuidado ao instalar pacotes de terceiros, não só devido aos softwares que eles podem instalar, mas também porque o pacote RPM pode conter scripts arbitrários que são executados com o usuário root como parte do processo de instalação. Nota
Você pode extrair arquivos de um arquivo de pacote RPM sem instalar o pacote. O utilitário rpm2cpio pode passar o conteúdo do RPM para uma ferramenta especial de arquivamento chamada cpio, que pode extrair todos os arquivos ou arquivos individuais.
Redirecione a saída de rpm2cpio PACKAGEFILE.rpm para cpio -id a fim de extrair todos os arquivos armazenados no pacote RPM. Árvores de subdiretório são criadas conforme necessário, relativas ao diretório de trabalho atual.
[user@host tmp-extract]$ rpm2cpio wonderwidgets-1.0-4.x86_64.rpm | cpio -id
Os arquivos individuais são extraídos ao especificar o caminho do arquivo:
[user@host ~]$ rpm2cpio wonderwidgets-1.0-4.x86_64.rpm | cpio -id “*txt” 11 blocks [user@host ~]$ ls -l usr/share/doc/wonderwidgets-1.0/ total 4 -rw-r–r–. 1 user user 76 Feb 13 19:27 README.txt
Sumário dos comandos de consulta do RPM
Os pacotes instalados podem ser consultados diretamente com o comando rpm. Adicione a opção -p para consultar um arquivo de pacote antes da instalação.
rpm_commands.png
Instalação e atualização de pacotes de software com YUM
Objetivos
Depois de concluir esta seção, você deverá ser capaz de localizar, instalar e atualizar pacotes de software usando o comando yum. Gerenciamento de pacotes de software com YUM
O comando de baixo nível rpm pode ser usado para instalar pacotes, mas não é projetado para trabalhar com repositórios de pacotes ou resolver dependências de várias fontes automaticamente.
O Yum é projetado para ser um sistema melhor para gerenciar instalação e atualizações de software baseadas em RPM. O comando yum permite instalar, atualizar, remover e obter informações sobre pacotes de software e suas dependências. Você pode obter um histórico das transações realizadas e trabalhar com vários repositórios de software da Red Hat e de terceiros.
Localização de software com yum
yum help exibe informações de uso.
yum list exibe os pacotes instalados e disponíveis.
[user@host ~]$ yum list 'http*'
Available Packages
http-parser.i686 2.8.0-2.el8 rhel8-appstream
http-parser.x86_64 2.8.0-2.el8 rhel8-appstream
httpcomponents-client.noarch 4.5.5-4.module+el8+2452+b359bfcd rhel8-appstream
httpcomponents-core.noarch 4.4.10-3.module+el8+2452+b359bfcd rhel8-appstream
httpd.x86_64 2.4.37-7.module+el8+2443+605475b7 rhel8-appstream
httpd-devel.x86_64 2.4.37-7.module+el8+2443+605475b7 rhel8-appstream
httpd-filesystem.noarch 2.4.37-7.module+el8+2443+605475b7 rhel8-appstream
httpd-manual.noarch 2.4.37-7.module+el8+2443+605475b7 rhel8-appstream
httpd-tools.x86_64 2.4.37-7.module+el8+2443+605475b7 rhel8-appstream
yum search KEYWORD lista pacotes por palavras-chave encontradas somente nos campos de nome e sumário.
Para procurar pacotes que tenham “servidor web” nos campos de nome, sumário e descrição, use search all:
[user@host ~]$ yum search all 'web server'
================= Summary & Description Matched: web server ====================
pcp-pmda-weblog.x86_64 : Performance Co-Pilot (PCP) metrics from web server logs
nginx.x86_64 : A high performance web server and reverse proxy server
======================== Summary Matched: web server ===========================
libcurl.x86_64 : A library for getting files from web servers
libcurl.i686 : A library for getting files from web servers
libcurl.x86_64 : A library for getting files from web servers
====================== Description Matched: web server =========================
httpd.x86_64 : Apache HTTP Server
git-instaweb.x86_64 : Repository browser in gitweb
...output omitted...
yum info PACKAGENAME fornece informações detalhadas sobre um pacote, incluindo o espaço em disco necessário para a instalação.
Para obter informações sobre o Servidor HTTP Apache:
[user@host ~]$ yum info httpd
Available Packages
Name : httpd
Version : 2.4.37
Release : 7.module+el8+2443+605475b7
Arch : x86_64
Size : 1.4 M
Source : httpd-2.4.37-7.module+el8+2443+605475b7.src.rpm
Repo : rhel8-appstream
Summary : Apache HTTP Server
URL : https://httpd.apache.org/
License : ASL 2.0
Description : The Apache HTTP Server is a powerful, efficient, and extensible
: web server.
yum provides PATHNAME exibe os pacotes correspondentes ao nome do caminho especificado (que, muitas vezes, inclui caracteres curinga).
Para encontrar pacotes que fornecem o diretório /var/www/html, use:
[user@host ~]$ yum provides /var/www/html
httpd-filesystem-2.4.37-7.module+el8+2443+605475b7.noarch : The basic directory layout for the Apache HTTP server
Repo : rhel8-appstream
Matched from:
Filename : /var/www/html
Instalação e remoção de software com yum
yum install PACKAGENAME obtém e instala um pacote de software, incluindo todas as dependências.
[user@host ~]$ yum install httpd
Dependencies resolved.
================================================================================
Package Arch Version Repository Size
================================================================================
Installing:
httpd x86_64 2.4.37-7.module... rhel8-appstream 1.4 M
Installing dependencies:
apr x86_64 1.6.3-8.el8 rhel8-appstream 125 k
apr-util x86_64 1.6.1-6.el8 rhel8-appstream 105 k
...output omitted...
Transaction Summary
================================================================================
Install 9 Packages
Total download size: 2.0 M
Installed size: 5.4 M
Is this ok [y/N]: y
Downloading Packages:
(1/9): apr-util-bdb-1.6.1-6.el8.x86_64.rpm 464 kB/s | 25 kB 00:00
(2/9): apr-1.6.3-8.el8.x86_64.rpm 1.9 MB/s | 125 kB 00:00
(3/9): apr-util-1.6.1-6.el8.x86_64.rpm 1.3 MB/s | 105 kB 00:00
...output omitted...
Total 8.6 MB/s | 2.0 MB 00:00
Running transaction check
Transaction check succeeded.
Running transaction test
Transaction test succeeded.
Running transaction
Preparing : 1/1
Installing : apr-1.6.3-8.el8.x86_64 1/9
Running scriptlet: apr-1.6.3-8.el8.x86_64 1/9
Installing : apr-util-bdb-1.6.1-6.el8.x86_64 2/9
...output omitted...
Installed:
httpd-2.4.37-7.module+el8+2443+605475b7.x86_64 apr-util-bdb-1.6.1-6.el8.x86_64
apr-util-openssl-1.6.1-6.el8.x86_64 apr-1.6.3-8.el8.x86_64
...output omitted...
Complete!
yum update PACKAGENAME obtém e instala uma versão mais recente do pacote especificado, incluindo todas as dependências. Em geral, o processo tenta preservar os arquivos de configuração no local, mas em alguns casos eles poderão ser renomeados se o empacotador achar que o antigo não funcionará após a atualização. Sem um PACKAGENAME especificado, ele instala todas as atualizações relevantes.
[user@host ~]$ sudo yum update
Como só é possível testar um novo kernel com o boot desse kernel específico, o pacote é projetado especificamente para que várias versões possam ser instaladas de uma vez. Se o novo kernel falhar durante o boot, o kernel antigo ainda estará disponível. O uso de yum update kernel instalará de fato o novo kernel. Os arquivos de configuração mantêm uma lista de pacotes para sempre instalar, mesmo se o administrador solicitar uma atualização.
Nota
Use yum list kernel para listar todos os kernels instalados e disponíveis. Para ver qual kernel está em execução, use o comando uname. A opção -r mostra apenas a versão e o lançamento do kernel; a opção -a mostra o lançamento do kernel e informações adicionais.
[user@host ~]$ yum list kernel
Installed Packages
kernel.x86_64 4.18.0-60.el8 @anaconda
kernel.x86_64 4.18.0-67.el8 @rhel-8-for-x86_64-baseos-htb-rpms
[user@host ~]$ uname -r
4.18.0-60.el8.x86_64
[user@host ~]$ uname -a
Linux host.lab.example.com 4.18.0-60.el8.x86_64 #1 SMP Fri Jan 11 19:08:11 UTC 2019 x86_64 x86_64 x86_64 GNU/Linux
yum remove PACKAGENAME remove um pacote de software instalado, incluindo todos os pacotes compatíveis.
[user@host ~]$ sudo yum remove httpd
Atenção
O comando yum remove remove os pacotes listados e todos os pacotes que exigem os pacotes que estão sendo removidos (e os pacotes que exigem esses pacotes e assim por diante). Isso pode levar à remoção inesperada de pacotes; portanto, revise cuidadosamente a lista de pacotes a serem removidos.
Instalação e remoção de grupos de software com yum
O yum também tem o conceito de grupos, que são coleções de softwares relacionados e instalados em conjunto para uma finalidade específica. No Red Hat Enterprise Linux 8, há dois tipos de grupo. Grupos regulares são coleções de pacotes. Grupos de ambiente são coleções de grupos regulares. Os pacotes ou os grupos fornecidos por um grupo podem ser obrigatórios (deverão ser instalados se o grupo estiver instalado), padrão (normalmente, estarão instalados se o grupo estiver instalado) ou opcionais (não serão instalados quando o grupo for instalado, a menos que solicitados especificamente).
Assim como yum list, o comando yum group list exibe os nomes dos grupos instalados e disponíveis.
[user@host ~]$ yum group list
Available Environment Groups:
Server with GUI
Minimal Install
Server
...output omitted...
Available Groups:
Container Management
.NET Core Development
RPM Development Tools
...output omitted...
Alguns grupos são normalmente instalados por meio de grupos de ambiente e são ocultos por padrão. Liste os grupos ocultos com o comando yum group list hidden.
yum group info exibe informações sobre um grupo. Inclui uma lista de nomes de pacotes obrigatórios, padrão e opcionais.
[user@host ~]$ yum group info "RPM Development Tools"
Group: RPM Development Tools
Description: These tools include core development tools such rpmbuild.
Mandatory Packages:
redhat-rpm-config
rpm-build
Default Packages:
rpmdevtools
Optional Packages:
rpmlint
yum group install instala um grupo que faz a instalação de seus pacotes obrigatórios e padrão, além daqueles dos quais ele depende.
[user@host ~]$ sudo yum group install "RPM Development Tools"
...output omitted...
Installing Groups:
RPM Development Tools
Transaction Summary
===============================================================================
Install 64 Packages
Total download size: 21 M
Installed size: 62 M
Is this ok [y/N]: y
...output omitted...
Importante
O comportamento dos grupos YUM mudou a partir do Red Hat Enterprise Linux 7. No RHEL 7 e posteriores, os grupos são tratados como objetos e rastreados pelo sistema. Se um grupo instalado for atualizado e novos pacotes obrigatórios ou padrão tiverem sido adicionados ao grupo pelo repositório YUM, esses novos pacotes serão instalados na atualização.
O RHEL 6 (e anteriores) considerará um grupo instalado se todos os pacotes obrigatórios tiverem sido instalados, se ele não tiver pacotes obrigatórios ou se qualquer pacote padrão ou opcional do grupo estiver instalado. A partir do RHEL 7, um grupo será considerado instalado somente se yum group install tiver sido usado para instalá-lo. O comando yum group mark install GROUPNAME pode ser usado para marcar um grupo como instalado, e todos os pacotes ausentes e suas dependências serão instalados na próxima atualização.
Por fim, o RHEL 6 (e anteriores) não tem a forma de duas palavras dos comandos yum group. Em outras palavras, no RHEL 6, o comando yum grouplist existe, mas o comando equivalente yum group list do RHEL 7 e RHEL 8 não.
Visualização do histórico de transações
Todas as transações de instalação e remoção são registradas em log em /var/log/dnf.rpm.log.
[user@host ~]$ tail -5 /var/log/dnf.rpm.log
2019-02-26T18:27:00Z SUBDEBUG Installed: rpm-build-4.14.2-9.el8.x86_64
2019-02-26T18:27:01Z SUBDEBUG Installed: rpm-build-4.14.2-9.el8.x86_64
2019-02-26T18:27:01Z SUBDEBUG Installed: rpmdevtools-8.10-7.el8.noarch
2019-02-26T18:27:01Z SUBDEBUG Installed: rpmdevtools-8.10-7.el8.noarch
2019-02-26T18:38:40Z INFO --- logging initialized ---
yum history exibe um sumário das transações de instalação e remoção.
[user@host ~]$ sudo yum history
ID | Command line | Date and time | Action(s) | Altered
-------------------------------------------------------------------------------
7 | group install RPM Develo | 2019-02-26 13:26 | Install | 65
6 | update kernel | 2019-02-26 11:41 | Install | 4
5 | install httpd | 2019-02-25 14:31 | Install | 9
4 | -y install @base firewal | 2019-02-04 11:27 | Install | 127 EE
3 | -C -y remove firewalld - | 2019-01-16 13:12 | Removed | 11 EE
2 | -C -y remove linux-firmw | 2019-01-16 13:12 | Removed | 1
1 | | 2019-01-16 13:05 | Install | 447 EE
A opção history undo inverte uma transação.
[user@host ~]$ sudo yum history undo 5
Undoing transaction 7, from Tue 26 Feb 2019 10:40:32 AM EST
Install apr-1.6.3-8.el8.x86_64 @rhel8-appstream
Install apr-util-1.6.1-6.el8.x86_64 @rhel8-appstream
Install apr-util-bdb-1.6.1-6.el8.x86_64 @rhel8-appstream
Install apr-util-openssl-1.6.1-6.el8.x86_64 @rhel8-appstream
Install httpd-2.4.37-7.module+el8+2443+605475b7.x86_64 @rhel8-appstream
...output omitted...
Sumário de comandos yum
É possível localizar, instalar, atualizar e remover pacotes por nome ou grupos de pacotes.
yum_commands.png
Ativação de repositórios de software YUM
Objetivos
Depois de concluir esta seção, você deverá ser capaz de ativar e desativar o uso de repositórios YUM da Red Hat ou de terceiros por um servidor. Ativação de repositórios de software da Red Hat
O registro de um sistema no serviço de gerenciamento de subscrições configura automaticamente o acesso a repositórios de software com base nas subscrições anexadas. Para ver todos os repositórios disponíveis:
[user@host ~]$ yum repolist all …output omitted… rhel-8-for-x86_64-appstream-debug-rpms … AppStream (Debug RPMs) disabled rhel-8-for-x86_64-appstream-rpms … AppStream (RPMs) enabled: 5,045 rhel-8-for-x86_64-appstream-source-rpms … AppStream (Source RPMs) disabled rhel-8-for-x86_64-baseos-debug-rpms … BaseOS (Debug RPMs) enabled: 2,270 rhel-8-for-x86_64-baseos-rpms … BaseOS (RPMs) enabled: 1,963 …output omitted…
O comando yum config-manager pode ser usado para ativar ou desativar repositórios. Para ativar um repositório, o comando define o parâmetro enabled como 1. Por exemplo, o seguinte comando ativa o repositório rhel-8-server-debug-rpms:
[user@host ~]$ yum config-manager –enable rhel-8-server-debug-rpms Updating Subscription Management repositories. ============= repo: rhel-8-for-x86_64-baseos-debug-rpms ============ [rhel-8-for-x86_64-baseos-debug-rpms] bandwidth = 0 baseurl = [https://cdn.redhat.com/content/dist/rhel8/8/x86_64/baseos/debug] cachedir = /var/cache/dnf cost = 1000 deltarpm = 1 deltarpm_percentage = 75 enabled = 1 …output omitted…
As fontes que não sejam a Red Hat fornecem softwares por meio de repositórios de terceiros, os quais podem ser acessados pelo comando yum em um site, um servidor FTP ou o sistema de arquivos local. Por exemplo, a Adobe fornece alguns de seus softwares para Linux por meio de um repositório YUM. Na sala de aula da Red Hat, o servidor da sala de aula content.example.com hospeda repositórios YUM.
Para ativar o suporte a um novo repositório de terceiros, crie um arquivo no diretório /etc/yum.repos.d/. Os arquivos de configuração do repositório devem terminar com a extensão .repo. A definição do repositório contém o URL do repositório, um nome, se o GPG deve ou não ser usado para verificar as assinaturas do pacote e, se for o caso, o URL apontando para a chave GPG confiável.
Criação de repositórios YUM
Crie repositórios YUM com o comando yum config-manager. O comando a seguir cria um arquivo denominado /etc/yum.repos.d/dl.fedoraproject.org_pub_epel_8_Everything_x86_64_.repo com a saída apresentada.
[user@host ~]$ yum config-manager
–add-repo=“https://dl.fedoraproject.org/pub/epel/8/Everything/x86_64/"
Adding repo from: https://dl.fedoraproject.org/pub/epel/8/Everything/x86_64/
[dl.fedoraproject.org_pub_epel_8_Everything_x86_64_] name=created by yum config-manager from https://dl.fedoraproject.org/pub/epel/8/Everything/x86_64/ baseurl=https://dl.fedoraproject.org/pub/epel/8/Everything/x86_64/ enabled=1
Modifique o arquivo para fornecer valores personalizados e o local de uma chave GPG. As chaves são armazenadas em vários locais no site do repositório remoto, como http://dl.fedoraproject.org/pub/epel/RPM-GPG-KEY-EPEL-8. Os administradores devem fazer o download da chave para um arquivo local em vez de permitir que o yum obtenha a chave de uma fonte externa. Por exemplo:
[EPEL] name=EPEL 8 baseurl=https://dl.fedoraproject.org/pub/epel/8/Everything/x86_64/ enabled=1 gpgcheck=1 gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-EPEL-8
Pacotes de configuração RPM para repositórios locais
Alguns repositórios fornecem um arquivo de configuração e a chave pública GPG como parte de um pacote RPM, que pode ser baixado e instalado usando o comando yum localinstall. Por exemplo, o projeto voluntário denominado Pacotes adicional para Enterprise Linux (EPEL, Extra Packages for Enterprise Linux) fornece software que não tem suporte da Red Hat, mas é compatível com o Red Hat Enterprise Linux.
O seguinte comando instala o pacote de repositório do EPEL para Red Hat Enterprise Linux 8:
[user@host ~]$ rpm –import
http://dl.fedoraproject.org/pub/epel/RPM-GPG-KEY-EPEL-8
[user@host ~]$ yum install
https://dl.fedoraproject.org/pub/epel/epel-release-latest-8.noarch.rpm
Os arquivos de configuração geralmente listam várias referências de repositório em um só arquivo. Cada referência de repositório começa com um nome de uma única palavra entre colchetes.
[user@host ~]$ cat /etc/yum.repos.d/epel.repo [epel] name=Extra Packages for Enterprise Linux $releasever - $basearch #baseurl=https://download.fedoraproject.org/pub/epel/$releasever/Everything/$basearch metalink=https://mirrors.fedoraproject.org/metalink?repo=epel-$releasever&arch=$basearch&infra=$infra&content=$contentdir enabled=1 gpgcheck=1 gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-EPEL-8
[epel-debuginfo] name=Extra Packages for Enterprise Linux $releasever - $basearch - Debug #baseurl=https://download.fedoraproject.org/pub/epel/$releasever/Everything/$basearch/debug metalink=https://mirrors.fedoraproject.org/metalink?repo=epel-debug-$releasever&arch=$basearch&infra=$infra&content=$contentdir enabled=0 gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-EPEL-8 gpgcheck=1
[epel-source] name=Extra Packages for Enterprise Linux $releasever - $basearch - Source #baseurl=https://download.fedoraproject.org/pub/epel/$releasever/Everything/SRPMS metalink=https://mirrors.fedoraproject.org/metalink?repo=epel-source-$releasever&arch=$basearch&infra=$infra&content=$contentdir enabled=0 gpgkey=file:///etc/pki/rpm-gpg/RPM-GPG-KEY-EPEL-8 gpgcheck=1
Para definir um repositório, mas não pesquisar nele por padrão, insira o parâmetro enabled=0. Os repositórios podem ser ativados e desativados de modo persistente com o comando yum config-manager ou temporariamente com as opções de comando do yum, –enablerepo=PATTERN e –disablerepo=PATTERN. Atenção
Instale a chave GPG do RPM antes de instalar pacotes assinados. Isso verifica se os pacotes pertencem a uma chave que foi importada. Caso contrário, ocorre uma falha no comando yum devido à ausência da chave. A opção –nogpgcheck pode ser usada para ignorar chaves GPG ausentes, mas isso faz com que pacotes forjados ou sem proteção sejam instalados no sistema, comprometendo potencialmente a segurança.
Gerenciamento de fluxos de módulos de pacote
Objetivos
Depois de concluir esta seção, você deverá ser capaz de:
Explicar como os módulos permitem a instalação de versões específicas do software.
Saber listar, ativar e alternar os fluxos de módulos.
Instalar e atualizar pacotes a partir de um módulo.
Introdução ao fluxo de aplicativos
O Red Hat Enterprise Linux 8.0 apresenta o conceito de fluxos de aplicativos. Várias versões de componentes do espaço do usuário fornecidas com a distribuição agora são entregues ao mesmo tempo. Eles podem ser atualizados com mais frequência do que os pacotes principais do sistema operacional. Isso proporciona maior flexibilidade para personalizar o Red Hat Enterprise Linux sem afetar a estabilidade subjacente da plataforma ou de implementações específicas.
Tradicionalmente, gerenciar versões alternativas do pacote de software de um aplicativo e seus pacotes relacionados significava manter repositórios diferentes para cada versão. Para os desenvolvedores que desejavam usar a versão mais recente de um aplicativo e os administradores que desejavam usar a versão mais estável do aplicativo, isso criava uma situação monótona de gerenciar. Todo esse processo foi simplificado no Red Hat Enterprise Linux 8 usando uma nova tecnologia denominada Modularidade. A modularidade permite que um só repositório hospede diversas versões de pacote de um aplicativo e suas dependências.
O conteúdo do Red Hat Enterprise Linux 8 é distribuído por meio de dois repositórios de software principais: BaseOS e fluxo de aplicativos (AppStream).
BaseOS
O repositório BaseOS fornece o conteúdo do sistema operacional principal para o Red Hat Enterprise Linux como pacotes de RPM. Os componentes do BaseOS têm um ciclo de vida idêntico ao do conteúdo das versões anteriores do Red Hat Enterprise Linux.
Fluxo de aplicativos
O repositório AppStream fornece conteúdo com ciclos de vida variados, que incluem módulos e pacotes tradicionais. O AppStream contém partes necessárias do sistema, bem como uma ampla variedade de aplicativos disponíveis anteriormente junto com as coleções de software da Red Hat e com outros produtos e programas. Importante
O BaseOS e o AppStream são uma parte necessária do sistema Red Hat Enterprise Linux 8.
O repositório AppStream contém dois tipos de conteúdo: módulos e pacotes RPM tradicionais. Um módulo consiste em um conjunto de pacotes RPM que estão interligados. Os módulos podem conter vários fluxos para disponibilizar diversas versões de aplicativos para instalação. A ativação de um fluxo de módulo fornece ao sistema acesso aos pacotes RPM que estão nesse fluxo. Módulos
Um módulo é um conjunto de pacotes RPM que são um conjunto consistente e estão interligados. Normalmente, é organizado em torno de uma versão específica de um aplicativo de software ou linguagem de programação. Um módulo típico pode conter pacotes com um aplicativo, pacotes com as bibliotecas de dependência específicas do aplicativo, pacotes com documentação do aplicativo e pacotes com utilitários auxiliares.
Fluxos de módulos
Cada módulo pode ter um ou mais fluxos de módulos, que contêm versões diferentes do conteúdo. Cada um dos fluxos recebe atualizações de forma independente. Pense no fluxo de módulos como um repositório virtual no repositório físico AppStream.
Para cada módulo, apenas um de seus fluxos pode ser ativado e fornecer seus pacotes.
Perfis de módulos
Cada módulo pode ter um ou mais perfis. Um perfil é uma lista de determinados pacotes a serem instalados juntos para um caso de uso específico, como servidor ou cliente ou para desenvolvimento, instalação mínima, entre outros.
A instalação de um perfil de módulo específico simplesmente instala um conjunto específico de pacotes do fluxo do módulo. Você pode posteriormente instalar ou desinstalar pacotes normalmente. Se você não especificar um perfil, o módulo instalará seu perfil padrão. Gerenciamento de módulos usando yum
O yum versão 4, novo no Red Hat Enterprise Linux 8, adiciona suporte para os novos recursos modulares do fluxo de aplicativos.
Para lidar com o conteúdo modular, o comando yum module foi adicionado. De outra forma, o yum funciona com módulos assim como com pacotes regulares.
Lista de módulos
Para exibir a lista de módulos disponíveis, use yum module list:
[user@host ~]$ yum module list Red Hat Enterprise Linux 8 for x86_64 - AppStream (RPMs) Name Stream Profiles Summary 389-ds 1.4 default 389 Directory Server (base) ant 1.10 [d] common [d] Java build tool container-tools 1.0 [d] common [d] Common tools and dependencies for container runtimes …output omitted… Hint: [d]efault, [e]nabled, [x]disabled, [i]nstalled
Nota
Use a opção Hint no final da saída para ajudar a determinar quais fluxos e perfis estão ativados, desativados, instalados e quais deles são as opções padrão.
Para listar os fluxos de um módulo específico e recuperar o status:
[user@host ~]$ yum module list perl Red Hat Enterprise Linux 8 for x86_64 - AppStream (RPMs) Name Stream Profiles Summary perl 5.24 common [d], minimal Practical Extraction and Report Language perl 5.26 [d] common [d], minimal Practical Extraction and Report Language
Para exibir detalhes de um módulo:
[user@host ~]$ yum module info perl Name : perl Stream : 5.24 Version : 820190207164249 Context : ee766497 Profiles : common [d], minimal Default profiles : common Repo : rhel-8-for-x86_64-appstream-rpms Summary : Practical Extraction and Report Language …output omitted… Artifacts : perl-4:5.24.4-403.module+el8+2770+c759b41a.x86_64 : perl-Algorithm-Diff-0:1.1903-9.module+el8+2464+d274aed1.noarch : perl-Archive-Tar-0:2.30-1.module+el8+2464+d274aed1.noarch …output omitted…
Nota
Se o fluxo de módulos não for especificado, yum module info mostra uma lista dos pacotes instalados pelo perfil padrão de um módulo usando o fluxo padrão. Use o formato nome-do-módulo:fluxo para visualizar um fluxo de módulos específico. Adicione a opção –profile para exibir informações sobre os pacotes instalados por cada um dos perfis do módulo. Por exemplo:
[user@host ~]$ yum module info –profile perl:5.24
Ativação de fluxos de módulos e instalação de módulos
Os fluxos de módulos devem estar ativados para instalar o módulo correspondente. Para simplificar esse processo, quando um módulo é instalado, ele ativa seu fluxo de módulo se necessário. Os fluxos de módulos podem ser ativados manualmente usando yum module enable e fornecendo o nome do fluxo de módulo. Importante
Apenas um fluxo de módulo pode ser ativado para um determinado módulo. Ativar um fluxo de módulo adicional desativará o fluxo de módulo original.
Instale um módulo usando o fluxo e os perfis padrão:
[user@host ~]$ sudo yum module install perl Dependencies resolved.
Package Arch Version Repository Size
Installing group/module packages: perl x86_64 4:5.26.3-416.el8 rhel-8-for-x86_64-appstream-htb-rpms 72 k Installing dependencies: …output omitted… Running transaction Preparing : 1/1 Installing : perl-Exporter-5.72-396.el8.noarch 1/155 Installing : perl-Carp-1.42-396.el8.noarch 2/155 …output omitted… Installed: perl-4:5.26.3-416.el8.x86_64 perl-Encode-Locale-1.05-9.el8.noarch …output omitted… Complete!
Nota
Os mesmos resultados poderiam ter sido obtidos executando yum install @perl. A notação @ informa ao yum que o argumento é um nome de módulo em vez de um nome de pacote.
Para verificar o status do fluxo de módulo e do perfil instalado:
[user@host ~]$ yum module list perl Red Hat Enterprise Linux 8 for x86_64 - AppStream (RPMs) Name Stream Profiles Summary perl 5.24 common, minimal Practical Extraction and Report Language perl 5.26 [d][e] common [i], minimal Practical Extraction and Report Language
Hint: [d]efault, [e]nabled, [x]disabled, [i]nstalled
Remoção de módulos e desativação de fluxos de módulos
A remoção de um módulo exclui todos os pacotes instalados pelos perfis do fluxo de módulo ativado no momento e todos os demais pacotes e módulos que dependem deles. Os pacotes instalados com esse fluxo de módulos não listado em nenhum de seus perfis permanecem instalados no sistema e podem ser removidos manualmente. Atenção
Remover módulos e alternar fluxos de módulos pode ser um pouco complicado. Alternar o fluxo ativado para um módulo é equivalente a redefinir o fluxo atual e ativar o novo fluxo. Isso não altera automaticamente nenhum pacote instalado. Você tem que fazer isso manualmente.
A instalação direta de um fluxo de módulos diferente do que está atualmente instalado não é recomendada, porque os scripts de upgrade podem ser executados durante a instalação, o que romperia o fluxo do módulo original. Isso pode levar à perda de dados ou outros problemas de configuração.
Prossiga com cuidado.
Para remover um módulo instalado:
[user@host ~]$ sudo yum module remove perl Dependencies resolved.
Package ArchVersion Repository Size
Removing: perl x86_644:5.26.3-416.el8 @rhel-8.0-for-x86_64-appstream-rpms 0 Removing unused dependencies: …output omitted… Running transaction Preparing : 1/1 Erasing : perl-4:5.26.3-416.el8.x86_64 1/155 Erasing : perl-CPAN-2.18-397.el8.noarch 2/155 …output omitted… Removed: perl-4:5.26.3-416.el8.x86_64 dwz-0.12-9.el8.x86_64 …output omitted… Complete!
Depois que o módulo for removido, o fluxo de módulo ainda estará ativado. Para verificar se o fluxo de módulo ainda está ativado:
[user@host ~]$ yum module list perl Red Hat Enterprise Linux 8 for x86_64 - AppStream (RPMs) Name Stream Profiles Summary perl 5.24 common [d], minimal Practical Extraction and Report Language perl 5.26 [d][e] common [d], minimal Practical Extraction and Report Language
Hint: [d]efault, [e]nabled, [x]disabled, [i]nstalled
Para desativar o fluxo de módulo:
[user@host ~]$ sudo yum module disable perl …output omitted… Dependencies resolved.
Package Arch Version Repository Size
Disabling module streams: perl 5.26 Is this ok [y/N]: y Complete!
Troca de fluxos de módulos
Normalmente, a troca de fluxos de módulos exige a atualização ou o downgrade do conteúdo para uma versão diferente.
Para garantir uma troca limpa, você deve remover os módulos fornecidos pelo fluxo do módulo primeiro. Dessa forma, serão removidos todos os pacotes instalados pelos perfis do módulo e os módulos e pacotes nos quais esses pacotes tenham dependências.
Para listar os pacotes instalados com o módulo, no exemplo abaixo o módulo postgresql:9.6 está instalado:
[user@host ~]$ sudo yum module info postgresql | grep module+el8 |
sed ’s/.*: //g;s/\n/ /g’ | xargs yum list installed
Installed Packages
postgresql.x86_64 9.6.10-1.module+el8+2470+d1bafa0e @rhel-8.0-for-x86_64-appstream-rpms
postgresql-server.x86_64 9.6.10-1.module+el8+2470+d1bafa0e @rhel-8.0-for-x86_64-appstream-rpms
Remova os pacotes listados no comando anterior. Marque os perfis do módulo a serem desinstalados.
[user@host ~]$ sudo yum module remove postgresql …output omitted… Is this ok [y/N]: y …output omitted… Removed: postgresql-server-9.6.10-1.module+el8+2470+d1bafa0e.x86_64 libpq-10.5-1.el8.x86_64 postgresql-9.6.10-1.module+el8+2470+d1bafa0e.x86_64 Complete
Depois de remover os perfis do módulo, reinicie o fluxo do módulo. Use o comando yum module reset para redefinir o fluxo do módulo.
[user@host ~]$ sudo yum module reset postgresql
Package Arch Version Repository Size
Resetting module streams: postgresql 9.6
Transaction Summary
Is this ok [y/N]: y Complete!
Para ativar um fluxo de módulo diferente e instalar o módulo:
[user@host ~]$ sudo yum module install postgresql:10
O novo fluxo de módulo será ativado e o fluxo atual será desativado. Talvez seja necessário atualizar ou fazer downgrade de pacotes do fluxo de módulo anterior que não estão listados no novo perfil. Use yum distro-sync para executar essa tarefa se necessário. Também pode haver pacotes do fluxo de módulo anterior que continuam instalados. Remova-os usando yum remove.
Capítulo 15. Acesso a sistemas de arquivos Linux
Identificação de sistemas de arquivos e dispositivos Objetivos
Depois de concluir esta seção, você deverá ser capaz de identificar um diretório na hierarquia do sistema de arquivos e em que dispositivo ele está armazenado. Conceitos de gerenciamento de armazenamento
Os arquivos em um servidor Linux são acessados pela hierarquia do sistema de arquivos, uma única árvore invertida de diretórios. Essa hierarquia do sistema de arquivos é montada a partir dos sistemas de arquivos fornecidos pelos dispositivos de armazenamento disponíveis para o sistema. Cada sistema de arquivos é um dispositivo de armazenamento que foi formatado para armazenar arquivos.
De certo modo, a hierarquia de sistema de arquivos do Linux apresenta uma coleção de sistemas de arquivos em dispositivos de armazenamento separados, como se fosse um conjunto de arquivos em um dispositivo de armazenamento gigante que você pode navegar. Na maior parte do tempo, você não precisa saber em qual dispositivo de armazenamento um arquivo específico está, basta saber o diretório em que o arquivo está.
Às vezes, no entanto, isso pode ser importante. Pode ser necessário determinar o tamanho de um dispositivo de armazenamento e quais diretórios na hierarquia de sistema de arquivos são afetados. Pode haver erros nos logs de um dispositivo de armazenamento, e você precisa saber quais sistemas de arquivos estão em risco. Você pode apenas querer criar um link físico entre dois arquivos, e você precisa saber se eles estão no mesmo sistema de arquivos para determinar se é possível.
Sistemas de arquivos e pontos de montagem
Para disponibilizar o conteúdo de um sistema de arquivos na hierarquia de sistema de arquivos, ele deve ser montado em um diretório vazio. Esse diretório é chamado de ponto de montagem. Uma vez montado, se você usar ls para listar esse diretório, você verá o conteúdo do sistema de arquivos montado e poderá acessar e usar esses arquivos normalmente. Muitos sistemas de arquivos são montados automaticamente como parte do processo do boot.
Se você trabalhou apenas com as letras de unidades do Microsoft Windows, esse é um conceito fundamentalmente diferente. É um pouco semelhante ao recurso de pastas montadas do NTFS.
Sistemas de arquivos, armazenamento e dispositivos de blocos
O acesso de baixo nível a dispositivos de armazenamento no Linux é fornecido por um tipo especial de arquivo chamado dispositivo de blocos. Esses dispositivos de blocos devem ser formatados com um sistema de arquivos antes de poderem ser montados.
Os arquivos de dispositivo de blocos são armazenados no diretório /dev, juntamente com outros arquivos de dispositivo. Os arquivos de dispositivo são criados automaticamente pelo sistema operacional. No Red Hat Enterprise Linux, o primeiro disco rígido SATA/PATA, SAS, SCSI ou USB detectado é chamado /dev/sda, o segundo é /dev/sdb e assim por diante. Esses nomes representam o disco rígido inteiro.
Outros tipos de armazenamento terão outras formas de nomenclatura.
Tabela 15.1. Nomenclatura do dispositivo de blocos
nav_linux_1.png
Nota
Muitas máquinas virtuais usam o mais recente armazenamento paravirtualizado virtio-scsi que terá nomenclatura no estilo /dev/sd*.
Partições de disco
Normalmente, você não transforma todo o dispositivo de armazenamento em um sistema de arquivos. Geralmente, os dispositivos de armazenamento são divididos em partes menores chamadas de partições.
As partições permitem que você compartimentalize um disco: as diversas partições podem ser formatadas com diferentes sistemas de arquivos ou usadas para diferentes finalidades. Por exemplo, uma partição pode conter os diretórios pessoais do usuário, enquanto outra pode conter os dados e logs do sistema. Se um usuário preencher a partição do diretório pessoal com dados, a partição do sistema ainda poderá ter espaço disponível.
As partições são dispositivos de blocos em si. Em armazenamento conectado a SATA, a primeira partição no primeiro disco é /dev/sda1. A terceira partição no segundo disco é /dev/sdb3 e assim por diante. Dispositivos de armazenamento paravirtualizados possuem um sistema de nomenclatura semelhante.
Um dispositivo SSD conectado a NVMe nomeia suas partições de maneira diferente. Nesse caso, a primeira partição no primeiro disco é /dev/nvme0p1. A terceira partição no segundo disco é /dev/nvme1p3 e assim por diante. Os cartões SD ou MMC possuem um sistema de nomenclatura semelhante.
Uma listagem longa do arquivo de dispositivos de /dev/sda1 no host revela seu tipo de arquivo especial como b, que significa “dispositivo de blocos”:
[user@host ~]$ ls -l /dev/sda1 brw-rw—-. 1 root disk 8, 1 Feb 22 08:00 /dev/sda1
Volumes lógicos
Outra maneira de organizar discos e partições é com o gerenciamento de volume lógico (LVM). Com o LVM, um ou mais dispositivos de blocos podem ser agregados em um pool de armazenamento chamado de grupo de volumes. O espaço em disco no grupo de volumes é dividido entre um ou mais volumes lógicos, que são o equivalente funcional de uma partição que reside em um disco físico.
O sistema de LVM atribui nomes a grupos de volumes e volumes lógicos na criação. O LVM cria um diretório em /dev que corresponde ao nome do grupo e, em seguida, cria um link simbólico nesse novo diretório com o mesmo nome do volume lógico. Esse arquivo de volume lógico fica disponível para montagem. Por exemplo, se um grupo de volumes for chamado de myvg e o volume lógico dentro dele for chamado de mylv, o nome do caminho completo para o arquivo do dispositivo de volume lógico será /dev/myvg/mylv. Nota
A forma do nome do dispositivo de volume lógico mencionado acima é, na verdade, implementada como um link simbólico para o arquivo de dispositivo real usado para acessá-lo, o que pode variar entre os boots. Há outra forma de nome de dispositivo de volume lógico vinculada a arquivos em /dev/mapper que são frequentemente usados e também são links simbólicos para o arquivo de dispositivo real. Verificação de sistemas de arquivos
Para obter uma visão geral dos dispositivos dos sistemas de arquivos locais e remotos e da quantidade de espaço livre disponível, execute o comando df. Quando df é executado sem argumentos, ele informa o espaço em disco total, o espaço em disco utilizado, o espaço em disco livre e a porcentagem do total de espaço em disco usado em todos os sistemas de arquivos normais montados. Ele fornece informações sobre os sistemas de arquivos locais e remotos.
O exemplo a seguir exibe os sistemas de arquivos e os pontos de montagem do host.
[user@host ~]$ df Filesystem 1K-blocks Used Available Use% Mounted on devtmpfs 912584 0 912584 0% /dev tmpfs 936516 0 936516 0% /dev/shm tmpfs 936516 16812 919704 2% /run tmpfs 936516 0 936516 0% /sys/fs/cgroup /dev/vda3 8377344 1411332 6966012 17% / /dev/vda1 1038336 169896 868440 17% /boot tmpfs 187300 0 187300 0% /run/user/1000
O particionamento no sistema host mostra dois sistemas de arquivos físicos, que são montados em / e /boot. Isso é comum para máquinas virtuais. Os dispositivos tmpfs e devtmpfs são sistemas de arquivos na memória do sistema. Todos os arquivos gravados em tmpfs ou em devtmpfs desaparecerão após a reinicialização do sistema.
Para melhorar a legibilidade dos tamanhos da saída, existem duas opções legíveis diferentes: -h ou -H. A diferença entre essas duas opções é que -h informa em KiB (210), MiB (220) ou GiB (230), enquanto a opção -H informa em unidades do SI: KB (103), MB (106) ou GB (109). Os fabricantes de discos rígidos geralmente usam unidades SI ao anunciar seus produtos.
Mostre um relatório sobre os sistemas de arquivos no sistema host com todas as unidades convertidas para formato legível:
[user@host ~]$ df -h Filesystem Size Used Avail Use% Mounted on devtmpfs 892M 0 892M 0% /dev tmpfs 915M 0 915M 0% /dev/shm tmpfs 915M 17M 899M 2% /run tmpfs 915M 0 915M 0% /sys/fs/cgroup /dev/vda3 8.0G 1.4G 6.7G 17% / /dev/vda1 1014M 166M 849M 17% /boot tmpfs 183M 0 183M 0% /run/user/1000
Para obter informações mais detalhadas sobre o espaço usado por uma determinada árvore de diretórios, use o comando du. O comando du tem as opções -h e -H para converter a saída em formato legível. O comando du mostra o tamanho de todos os arquivos na árvore de diretórios atual de modo recursivo.
Mostre um relatório de uso do disco para o diretório /usr/share no host:
[root@host ~]# du /usr/share …output omitted… 176 /usr/share/smartmontools 184 /usr/share/nano 8 /usr/share/cmake/bash-completion 8 /usr/share/cmake 356676 /usr/share
Mostre um relatório de uso do disco em formato legível para o diretório /usr/share no host:
[root@host ~]# du -h /var/log …output omitted… 176K /usr/share/smartmontools 184K /usr/share/nano 8.0K /usr/share/cmake/bash-completion 8.0K /usr/share/cmake 369M /usr/share
Montagem e desmontagem de sistemas de arquivos
Objetivos
Depois de concluir esta seção, você deverá ser capaz de acessar o conteúdo dos sistemas de arquivos adicionando e removendo sistemas de arquivos da hierarquia de sistemas de arquivos. Montagem manual de sistemas de arquivos
Um sistema de arquivos que resida em um dispositivo de armazenamento removível precisa ser montado para poder acessá-lo. O comando mount permite que o usuário root monte manualmente um sistema de arquivos. O primeiro argumento do comando mount especifica o sistema de arquivos a ser montado. O segundo argumento especifica o diretório a ser usado como ponto de montagem na hierarquia do sistema de arquivos.
Existem duas maneiras comuns de especificar o sistema de arquivos em uma partição de disco para o comando mount:
Com o nome do arquivo do dispositivo em /dev contendo o sistema de arquivos.
Com a UUID gravada no sistema de arquivos, um identificador universalmente único.
A montagem de um dispositivo é relativamente simples. Você precisa identificar o dispositivo que deseja montar, verificar se o ponto de montagem existe e montar o dispositivo no ponto de montagem.
Identificação do dispositivo de blocos
Um dispositivo de armazenamento conectável a quente, seja uma unidade de disco rígido (HDD), um dispositivo de estado sólido (SSD) ou um dispositivo de armazenamento USB, esses dispositivos poderão ser conectados a portas diferentes toda vez que forem conectados a um sistema.
Use o comando lsblk para listar os detalhes de um determinado dispositivo de blocos ou de todos os dispositivos disponíveis.
[root@host ~]# lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT vda 253:0 0 12G 0 disk ├─vda1 253:1 0 1G 0 part /boot ├─vda2 253:2 0 1G 0 part [SWAP] └─vda3 253:3 0 11G 0 part / vdb 253:16 0 64G 0 disk └─vdb1 253:17 0 64G 0 part
Se você acabou de adicionar um dispositivo de armazenamento de 64 GB com uma partição, então você pode adivinhar pela saída anterior que /dev/vdb1 é a partição que você deseja montar.
Montagem por nome de dispositivo de blocos
O exemplo a seguir monta o sistema de arquivos na partição /dev/vdb1 no diretório /mnt/data.
[root@host ~]# mount /dev/vdb1 /mnt/data
Para montar um sistema de arquivos, o diretório de destino já deve existir. O diretório /mnt existe por padrão e é destinado para uso como um ponto de montagem temporário.
Você pode usar o diretório /mnt ou, melhor ainda, criar um subdiretório de /mnt para usar como um ponto de montagem temporário, a menos que você tenha um bom motivo para montá-lo em um local específico na hierarquia do sistema de arquivos. Importante
Se o diretório que atua como ponto de montagem não estiver vazio, os arquivos copiados para esse diretório antes de o sistema de arquivos ser montado não estarão acessíveis até que o sistema de arquivos seja desmontado novamente.
Essa abordagem funciona bem no curto prazo. No entanto, a ordem na qual o sistema operacional detecta os discos pode mudar se os dispositivos forem adicionados ou removidos do sistema. Isso mudará o nome do dispositivo associado a esse dispositivo de armazenamento. Uma abordagem melhor seria montar por alguma característica incorporada no sistema de arquivos.
Montagem por UUID de sistema de arquivos
Um identificador estável associado a um sistema de arquivos é sua UUID, um número hexadecimal muito longo que atua como um identificador universalmente único. Essa UUID é parte do sistema de arquivos e permanece a mesma desde que o sistema de arquivos não seja recriado.
O comando lsblk -fp lista o caminho completo do dispositivo, com as UUIDs e os pontos de montagem, bem como o tipo de sistema de arquivos na partição. Se o sistema de arquivos não estiver montado, o ponto de montagem ficará em branco.
[root@host ~]# lsblk -fp
NAME FSTYPE LABEL UUID MOUNTPOINT
/dev/vda
├─/dev/vda1 xfs 23ea8803-a396-494a-8e95-1538a53b821c /boot
├─/dev/vda2 swap cdf61ded-534c-4bd6-b458-cab18b1a72ea [SWAP]
└─/dev/vda3 xfs 44330f15-2f9d-4745-ae2e-20844f22762d /
/dev/vdb
└─/dev/vdb1 xfs 46f543fd-78c9-4526-a857-244811be2d88
Monte o sistema de arquivos pela UUID do sistema de arquivos.
[root@host ~]# mount UUID=“46f543fd-78c9-4526-a857-244811be2d88” /mnt/data
Montagem automática de dispositivos de armazenamento removíveis
Se você estiver conectado e usando o ambiente de área de trabalho gráfica, ela montará automaticamente qualquer mídia de armazenamento removível quando ela for inserida.
O dispositivo de armazenamento removível é montado em /run/media/USERNAME/LABEL, onde USERNAME é o nome do usuário que fez login no ambiente gráfico e LABEL é um identificador, normalmente, o nome dado ao sistema de arquivos quando ele foi criado se um estava disponível.
Antes de remover o dispositivo, você deve desmontá-lo manualmente. Desmontagem de sistemas de arquivos
Os procedimentos de desligamento e reinicialização desmontam todos os sistemas de arquivos automaticamente. Como parte desse processo, todos os dados do sistema de arquivos armazenados em cache na memória são liberados para o dispositivo de armazenamento, garantindo, assim, que os dados não sejam corrompidos no sistema de arquivos. Atenção
Os dados do sistema de arquivos costumam ser armazenados em cache na memória. Portanto, para não corromper os dados no disco, é fundamental que você desmonte as unidades removíveis antes de desconectá-las. O procedimento de desmontagem sincroniza os dados antes de liberar a unidade, garantindo a integridade dos dados.
Para desmontar um sistema de arquivos, o comando umount espera o ponto de montagem como argumento.
[root@host ~]# umount /mnt/data
Não será possível fazer a desmontagem se o sistema de arquivos montado estiver em uso. Para que o comando umount obtenha êxito, é necessário que todos os processos parem de acessar os dados do ponto de montagem.
No exemplo abaixo, o comando umount falha porque o sistema de arquivos está em uso (o shell está usando /mnt/data como diretório de trabalho atual), gerando uma mensagem de erro.
[root@host ~]# cd /mnt/data [root@host data]# umount /mnt/data umount: /mnt/data: target is busy.
O comando lsof lista todos os arquivos abertos e o processo que os está acessando no diretório especificado. Ele é útil para identificar quais são os processos que estão atualmente impedindo o sistema de arquivos de obter êxito na desmontagem.
[root@host data]# lsof /mnt/data COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME bash 1593 root cwd DIR 253,17 6 128 /mnt/data lsof 2532 root cwd DIR 253,17 19 128 /mnt/data lsof 2533 root cwd DIR 253,17 19 128 /mnt/data
Depois que os processos forem identificados, uma ação poderá ser realizada, como aguardar que o processo seja concluído ou enviar um sinal SIGTERM ou SIGKILL para o processo. Nesse caso, basta alterar o diretório de trabalho atual para um diretório fora do ponto de montagem.
[root@host data]# cd [root@host ~]# umount /mnt/data
Nota
Um motivo comum para a falha na desmontagem dos sistemas de arquivos é que um shell Bash está usando o ponto de montagem ou um subdiretório como diretório de trabalho atual. Use o comando cd para alterar o sistema de arquivos a fim de resolver esse problema.
Localização de arquivos no sistema
Objetivos
Depois de concluir esta seção, você deverá ser capaz de procurar arquivos em sistemas de arquivos montados usando find e locate. Pesquisa de arquivos
Um administrador de sistema precisa de ferramentas para procurar arquivos que correspondam a determinados critérios no sistema de arquivos. Esta seção aborda dois comandos que podem pesquisar arquivos na hierarquia do sistema de arquivos.
O comando locate procura um índice pré-gerado de nomes de arquivos ou caminhos de arquivos e retorna os resultados instantaneamente.
O comando find faz uma busca em tempo real por arquivos, rastreando a hierarquia do sistema de arquivos.
Localização de arquivos por nome
O comando locate localiza arquivos com base no nome ou caminho para o arquivo. É rápido porque procura essa informações no banco de dados mlocate. No entanto, esse banco de dados não é atualizado em tempo real e deve ser atualizado com frequência para que os resultados sejam precisos. Isso também significa que locate não encontrará arquivos que foram criados desde a última atualização do banco de dados.
O banco de dados de locate é atualizado automaticamente todos os dias. No entanto, a qualquer momento, o usuário root pode usar o comando updatedb para forçar uma atualização imediata.
[root@host ~]# updatedb
O comando locate restringe os resultados para usuários sem privilégios. Para ver o nome do arquivo resultante, o usuário deve ter permissão de pesquisa no diretório em que o arquivo reside.
Procure arquivos com passwd no nome ou no caminho das árvores de diretórios legíveis para user no host.
[user@host ~]$ locate passwd /etc/passwd /etc/passwd- /etc/pam.d/passwd /etc/security/opasswd /usr/bin/gpasswd /usr/bin/grub2-mkpasswd-pbkdf2 /usr/bin/lppasswd /usr/bin/passwd …output omitted…
Os resultados serão retornados mesmo quando o nome ou o caminho de arquivo for apenas uma correspondência parcial da pesquisa.
[root@host ~]# locate image /etc/selinux/targeted/contexts/virtual_image_context /usr/bin/grub2-mkimage /usr/lib/sysimage /usr/lib/dracut/dracut.conf.d/02-generic-image.conf /usr/lib/firewalld/services/ovirt-imageio.xml /usr/lib/grub/i386-pc/lnxboot.image …output omitted…
A opção -i realiza uma pesquisa que não diferencia maiúsculas e minúsculas. Com essa opção, todas as combinações possíveis de letras maiúsculas e minúsculas correspondem à pesquisa.
[user@host ~]$ locate -i messages …output omitted… /usr/share/vim/vim80/lang/zh_TW/LC_MESSAGES /usr/share/vim/vim80/lang/zh_TW/LC_MESSAGES/vim.mo /usr/share/vim/vim80/lang/zh_TW.UTF-8/LC_MESSAGES /usr/share/vim/vim80/lang/zh_TW.UTF-8/LC_MESSAGES/vim.mo /usr/share/vim/vim80/syntax/messages.vim /usr/share/vim/vim80/syntax/msmessages.vim /var/log/messages
A opção -n limita o número de resultados da pesquisa retornados pelo comando locate. O seguinte exemplo limita os resultados da pesquisa retornados por locate às cinco primeiras ocorrências:
[user@host ~]$ locate -n 5 snow.png /usr/share/icons/HighContrast/16x16/status/weather-snow.png /usr/share/icons/HighContrast/22x22/status/weather-snow.png /usr/share/icons/HighContrast/24x24/status/weather-snow.png /usr/share/icons/HighContrast/256x256/status/weather-snow.png /usr/share/icons/HighContrast/32x32/status/weather-snow.png
Pesquisa de arquivos em tempo real
O comando find localiza os arquivos, executando uma pesquisa em tempo real na hierarquia de sistema de arquivos. É mais lento que locate, mas mais preciso. Ele também pode procurar arquivos com base em critérios diferentes do nome do arquivo, como as permissões do arquivo, o tipo de arquivo, seu tamanho ou sua hora de modificação.
O comando find examina os arquivos do sistema de arquivos usando a conta de usuário que executou a pesquisa. O usuário que invocar o comando find deve ter permissão de leitura e execução em um diretório para examinar o respectivo conteúdo.
O primeiro argumento do comando find é o diretório a ser pesquisado. Se o argumento do diretório for omitido, find iniciará a pesquisa no diretório atual e procurará correspondências em todos os subdiretórios.
Para procurar arquivos pelo nome, use a opção -name FILENAME. Com ela, find retorna o caminho dos arquivos que correspondem exatamente ao NOME DO ARQUIVO. Por exemplo, para procurar arquivos com o nome sshd_config a partir do diretório /, execute o seguinte comando:
[root@host ~]# find / -name sshd_config /etc/ssh/sshd_config
Nota
Com o comando find, as opções de palavras completas usam um único traço e as opções seguem o argumento do nome do caminho, diferentemente da maioria dos outros comandos do Linux.
Caracteres curinga estão disponíveis para pesquisa por nome de arquivo e retornarão todos os resultados que forem correspondências parciais. Ao usar caracteres curinga, é importante citar o nome do arquivo a ser procurado para evitar que o terminal interprete o caractere curinga.
Neste exemplo, procure os arquivos no diretório / que terminam em .txt:
[root@host ~]# find / -name ‘*.txt’ /etc/pki/nssdb/pkcs11.txt /etc/brltty/brl-lt-all.txt /etc/brltty/brl-mb-all.txt /etc/brltty/brl-md-all.txt /etc/brltty/brl-mn-all.txt …output omitted…
Para procurar arquivos no diretório /etc/ que contêm a palavra pass em qualquer lugar de seus nomes no host, execute o seguinte comando:
[root@host ~]# find /etc -name ‘pass’ /etc/security/opasswd /etc/pam.d/passwd /etc/pam.d/password-auth /etc/passwd- /etc/passwd /etc/authselect/password-auth
Para realizar uma pesquisa que não diferencie minúsculas e maiúsculas de um determinado nome de arquivo, use a opção -iname, seguida pelo nome de arquivo que deseja pesquisar. Para pesquisar arquivos com o texto messages, sem diferenciar maiúsculas de minúsculas, em seus nomes no diretório / do host, execute o seguinte comando:
[root@host ~]# find / -iname ‘messages’ …output omitted… /usr/share/vim/vim80/lang/zh_CN.UTF-8/LC_MESSAGES /usr/share/vim/vim80/lang/zh_CN.cp936/LC_MESSAGES /usr/share/vim/vim80/lang/zh_TW/LC_MESSAGES /usr/share/vim/vim80/lang/zh_TW.UTF-8/LC_MESSAGES /usr/share/vim/vim80/syntax/messages.vim /usr/share/vim/vim80/syntax/msmessages.vim
Pesquisa de arquivos com base na propriedade ou permissão
O comando find pode procurar arquivos com base na propriedade ou nas permissões. Opções úteis em uma pesquisa pelo proprietário são -user e -group (que pesquisam por nome) e -uid e -gid (que pesquisam por ID).
Procure arquivos cujo proprietário seja user no diretório /home/user do host.
[user@host ~]$ find -user user . ./.bash_logout ./.bash_profile ./.bashrc ./.bash_history
Procure arquivos cujo proprietário seja o grupo user no diretório /home/user do host.
[user@host ~]$ find -group user . ./.bash_logout ./.bash_profile ./.bashrc ./.bash_history
Procure arquivos cujo proprietário seja a ID de usuário 1000 no diretório /home/user do host.
[user@host ~]$ find -uid 1000 . ./.bash_logout ./.bash_profile ./.bashrc ./.bash_history
Procure arquivos cujo proprietário seja a ID de grupo 1000 no diretório /home/user do host.
[user@host ~]$ find -gid 1000 . ./.bash_logout ./.bash_profile ./.bashrc ./.bash_history
As opções -user e -group podem ser usadas juntas para procurar arquivos em que o proprietário do arquivo e o proprietário do grupo sejam diferentes. O exemplo abaixo lista os arquivos de propriedade do usuário root e afiliados ao grupo mail.
[root@host ~]# find / -user root -group mail /var/spool/mail …output omitted…
A opção -perm é usada para procurar arquivos com um conjunto específico de permissões. As permissões podem ser descritas como valores octais, com algumas combinações de 4, 2 e 1 referentes a leitura, gravação e execução. As permissões podem ser precedidas por uma / ou sinal de -.
Uma permissão numérica precedida de / corresponde a arquivos que têm pelo menos um bit de usuário, de grupo ou de outro para o conjunto de permissões. Um arquivo com permissões r–r–r– não corresponde a /222, mas um com rw-r–r– corresponde. Um sinal de - antes de uma permissão significa que as três instâncias desse bit devem estar habilitadas, de modo que nenhum dos exemplos anteriores seria correspondente, mas um comando como rw-rw-rw-> corresponderia.
Para usar um exemplo mais complexo, o seguinte comando corresponde a qualquer arquivo para o qual o usuário tenha permissões de leitura, gravação e execução, os membros do grupo tenham permissões de leitura e gravação e outros tenham acesso somente leitura:
[root@host ~]# find /home -perm 764
Para corresponder arquivos aos quais o usuário tem pelo menos permissões de gravação e execução e o grupo tem pelo menos permissões de gravação e outros têm pelo menos acesso de leitura:
[root@host ~]# find /home -perm -324
Para corresponder arquivos aos quais o usuário tem permissões de leitura ou o grupo tem pelo menos permissões de leitura ou outros têm pelo menos acesso de gravação:
[root@host ~]# find /home -perm /442
Quando usado com / ou -, um valor de 0 funciona como um caractere curinga, pois significa uma permissão de pelo menos nada.
Para encontrar qualquer arquivo no diretório /home/user ao qual outros usuários têm pelo menos o acesso de leitura no host, execute:
[user@host ~]$ find -perm -004
Localize todos os arquivos no diretório /home/user onde outros têm permissões de gravação no host.
[user@host ~]$ find -perm -002
Pesquisa de arquivos com base no tamanho
O comando find pode procurar arquivos que correspondem a um tamanho especificado com a opção -size seguida de um valor numérico e da unidade. Use a seguinte lista de unidades com a opção -size:
k, para kilobyte
M, para megabyte
G, para gigabyte
O exemplo abaixo mostra como procurar arquivos com 10 megabytes de tamanho, arredondados.
[user@host ~]$ find -size 10M
Para encontrar os arquivos com tamanho superior a 10 gigabytes.
[user@host ~]$ find -size +10G
Para listar todos os arquivos com um tamanho inferior a 10 quilobytes.
[user@host ~]$ find -size -10k
Importante
Os modificadores de unidade da opção -size arredondam os valores para unidades únicas. Por exemplo, o comando find -size 1M mostra os arquivos com menos de 1 MB porque arredonda todos os arquivos de até 1 MB.
Pesquisa de arquivos com base no horário de modificação
A opção -mmin, seguida pelo tempo em minutos, procura todos os arquivos com conteúdo alterado há n minutos. O carimbo de data e hora do arquivo é sempre arredondado para baixo. Ele também dá suporte a valores fracionários quando usados com intervalos (+n e -n).
Para localizar todos os arquivos que tiveram o conteúdo modificado há 120 minutos no host, execute:
[root@host ~]# find / -mmin 120
O modificador + que antecede a quantidade de minutos procura todos os arquivos no diretório / modificados há mais de n minutos. Neste exemplo, os arquivos modificados há mais de 200 minutos estão listados.
[root@host ~]# find / -mmin +200
O modificador - altera a pesquisa para procurar todos os arquivos no diretório / alterados há menos de n minutos. Neste exemplo, os arquivos modificados há menos de 150 minutos estão listados.
[root@host ~]# find / -mmin -150
Pesquisa de arquivos com base no tipo de arquivo
A opção -type no comando find limita o escopo da pesquisa para um determinado tipo de arquivo. Use a seguinte lista para passar os sinalizadores obrigatórios a fim de limitar o escopo da pesquisa:
f, para arquivo normal
d, para diretório
l, para softlink
b, para dispositivo de blocos
Pesquise todos os diretórios no diretório /etc do host.
[root@host ~]# find /etc -type d /etc /etc/tmpfiles.d /etc/systemd /etc/systemd/system /etc/systemd/system/getty.target.wants …output omitted…
Pesquise todos os softlinks no host.
[root@host ~]# find / -type l
Gere a lista de todos os dispositivos de blocos no diretório /dev do host:
[root@host ~]# find /dev -type b /dev/vda1 /dev/vda
A opção -links antes de um número procura todos os arquivos com uma determinada contagem de hardlinks. O número pode ser precedido por um modificador + para procurar arquivos com um número superior ao da contagem de hardlinks fornecida. Se o número for precedido por um modificador -, a pesquisa será limitada a todos os arquivos com uma contagem de hardlinks inferior ao número fornecido.
Pesquise todos os arquivos regulares com mais de um hardlink no host:
[root@host ~]# find / -type f -links +1
Capítulo 16. Análise e obtenção de suporte
Análise e gerenciamento de servidores remotos
Objetivos
Depois de concluir esta seção, você deverá ser capaz de ativar a interface de gerenciamento do console da web para gerenciar e monitorar remotamente o desempenho de um servidor Red Hat Enterprise Linux. Descrição do console da web
O console da web é uma interface de gerenciamento baseada na web para o Red Hat Enterprise Linux 8 projetada para gerenciar e monitorar seus servidores. Ele é baseado no serviço open source Cockpit.
Você pode usar o console da web para monitorar logs do sistema e visualizar gráficos de desempenho do sistema. Além disso, você pode usar o seu navegador para alterar as configurações usando ferramentas gráficas na interface do console da web, incluindo uma sessão de terminal interativa totalmente funcional. Ativação do console da web
O Red Hat Enterprise Linux 8 instala o console da web por padrão em todas as variantes de instalação, exceto uma instalação mínima. Use o seguinte comando para instalar o console da web:
[user@host ~]$ sudo yum install cockpit
Ative e inicie o serviço cockpit.socket, que executa um servidor web. Essa etapa é necessária se você precisar se conectar ao sistema por meio da interface web.
[user@host ~]$ sudo systemctl enable –now cockpit.socket Created symlink /etc/systemd/system/sockets.target.wants/cockpit.socket -> /usr/lib/systemd/system/cockpit.socket.
Se você estiver usando um perfil de firewall personalizado, precisará do serviço cockpit para firewalld para abrir a porta 9090 no firewall:
[user@host ~]$ sudo firewall-cmd –add-service=cockpit –permanent success [user@host ~]$ sudo firewall-cmd –reload success
Login no console da web
O console da web fornece seu próprio servidor web. Inicie o Firefox para fazer login no console da web. Você pode fazer login com o nome de usuário e a senha de qualquer conta local no sistema, incluindo o usuário root.
Abra https://servername:9090 no seu navegador da web, onde servername é o nome do host ou endereço IP do seu servidor. A conexão será protegida por uma sessão TLS. O sistema é instalado com um certificado TLS autoassinado por padrão e, quando você se conecta inicialmente, seu navegador da web provavelmente exibe um aviso de segurança. A página do man cockpit-ws(8) fornece instruções sobre como substituir o certificado TLS por um que esteja devidamente assinado.
Digite o nome de usuário e a senha na tela de login.
cockpit-login.png
Como opção, clique em Reuse my password for privileged tasks. Isso permite que você execute comandos com privilégios sudo, permitindo executar tarefas como modificar informações do sistema ou configurar novas contas.
Clique em Log In.
O console da web exibe o nome do usuário no lado direito da barra de título. Se você escolher a opção Reuse my password for privileged tasks, o ícone Privileged é exibido à esquerda do nome do usuário.
cockpit-title-bar-privileged.png
Se você estiver conectado como um usuário sem privilégios, o ícone Privileged não será exibido.
cockpit-title-bar-nonprivileged.png
Alteração de senhas
Usuários com e sem privilégios podem alterar suas próprias senhas enquanto estiverem conectados ao console da web. Clique em Accounts na barra de navegação. Clique no rótulo da sua conta para abrir a página de detalhes da conta.
accounts-student-main.png
Como um usuário sem privilégios, você está restrito a definir ou redefinir sua senha e gerenciar chaves SSH públicas. Para definir ou redefinir sua senha, clique em Set Password.
accounts-student-details.png
Digite suas informações nos campos Old Password, New Password e Confirm New Password. Clique em Set para ativar a nova senha.
accounts-student-set-new-password.png
Solução de problemas com o console da web
O console da web é uma poderosa ferramenta de solução de problemas. Você pode monitorar as estatísticas básicas do sistema em tempo real, inspecionar os logs do sistema e alternar rapidamente para uma sessão de terminal no console da web para coletar informações adicionais da interface de linha de comando.
Monitoramento das estatísticas do sistema em tempo real
Clique em Overview na barra de navegação para visualizar informações sobre o sistema, como seu tipo de hardware, sistema operacional, nome do host e mais. Se você estiver conectado como usuário sem privilégios, verá todas as informações, mas não terá permissão para modificar valores. A imagem a seguir exibe parte da página Overview.
nonprivileged-system-menu-top.png
Clique em View graphs página Overview para ver gráficos do desempenho atual do sistema para atividade da CPU, uso de memória, E/S do disco e uso da rede.
nonprivileged-system-menu-bottom.png
Inspeção e filtros de eventos do syslog
Na barra de navegação, Logs fornece acesso a ferramentas de análise para os logs do sistema. Você pode usar os menus na página para filtrar mensagens de log com base em um intervalo de datas de registro, nível de gravidade ou ambos. O console da web usa a data atual como o padrão, mas você pode clicar no menu de datas e especificar um intervalo de datas. Da mesma forma, o menu Severity fornece opções que vão de Everything a condições de gravidade mais específicas, como Alert and above, Debug and above, e assim por diante.
nonprivileged-logs-main-filters.png
Clique em uma linha para visualizar detalhes do relatório de log. No exemplo abaixo, observe a primeira linha, que relata em uma mensagem de log sudo.
nonprivileged-logs-eanda.png
O exemplo abaixo mostra os detalhes exibidos ao clicar na linha sudo. Os detalhes do relatório incluem a entrada de log selecionada (sudo), a data, a hora, a prioridade, o recurso de syslog da entrada de log, o nome do host do sistema que relatou a mensagem de log e mais.
nonprivileged-logs-entry.png
Execução de comandos em uma sessão de terminal
Na barra de navegação, Terminal fornece acesso a uma sessão de terminal totalmente funcional na interface do console da web. Isso permite que você execute comandos arbitrários para gerenciar e trabalhar com o sistema e executar tarefas não suportadas por outras ferramentas fornecidas pelo console da web.
A imagem a seguir exibe exemplos de comandos comuns usados para coletar informações adicionais. A listagem do conteúdo do diretório /var/log fornece lembretes sobre os arquivos de log que possam ter informações valiosas. O comando id fornece informações rápidas, como associação de grupo, que podem ajudar a solucionar problemas de restrições de acesso a arquivos. O comando ps au fornece uma visão rápida dos processos em execução no terminal e o usuário associado ao processo.
nonprivileged-terminal.png
Criação de relatórios de diagnóstico
Um relatório de diagnóstico é uma coleção de detalhes de configuração, informações do sistema e informações de diagnóstico de um sistema Red Hat Enterprise Linux. Os dados coletados no relatório concluído incluem logs do sistema e informações para depuração que podem ser usadas para solucionar problemas.
Faça login no console da web como usuário com privilégios. Clique em Diagnostic Reports na barra de navegação para abrir a página que cria esses relatórios. Clique em Create Report para gerar um novo relatório de diagnóstico.
diagnostic-reports-main-page.png
A interface exibe Done! quando o relatório estiver concluído. Clique em Download report para salvar o relatório.
diagnostic-report-download.png
Clique em Save File para salvar o arquivo e concluir o processo.
diagnostic-reports-save-file.png
O relatório concluído está salvo no diretório Downloads no sistema que hospeda o navegador da web usado para acessar o console da web. Neste exemplo, o host é workstation.
diagnostic-reports-workstation-sosreport.png
Gerenciamento de serviços do sistema com o console da web
Como usuário com privilégios no console da web, você pode interromper, iniciar, ativar e reiniciar os serviços do sistema. Além disso, você pode configurar as interfaces de rede, configurar serviços de firewall, administrar contas de usuário e muito mais. As imagens a seguir exibem exemplos comuns de uso das ferramentas de gerenciamento do console da web.
Opções de energia do sistema
O console da web permite reiniciar ou desligar o sistema. Faça login no console da web como usuário com privilégios. Clique em Overview na barra de navegação para acessar as opções de energia do sistema.
Selecione a opção desejada no menu suspenso no canto superior direito para reiniciar ou desligar um sistema.
system-power-options.png
Controle de serviços do sistema em execução
Você pode iniciar, ativar, desativar e interromper serviços com ferramentas gráficas no console da web. Clique em Services na barra de navegação para acessar a página inicial de serviços do console da web. Para gerenciar serviços, clique em System Services na parte superior da página inicial de serviços. Pesquise na barra de pesquisa ou percorra a página para selecionar o serviço que deseja gerenciar.
No exemplo abaixo, selecione a linha chronyd.service para abrir a página de gerenciamento de serviços.
services-main.png
Clique em Stop, Restart ou Disallow running (mask) como adequado para gerenciar o serviço. Neste modo de exibição, o serviço já está em execução. Informações adicionais relacionadas ao serviço estão disponíveis clicando em qualquer um dos links destacados ou percorrendo os logs de serviço exibidos abaixo da seção de gerenciamento de serviços.
services-chronyd.png
Configuração de interfaces de rede e firewall
Para gerenciar regras de firewall e interfaces de rede, clique em Networking na barra de navegação. O exemplo a seguir mostra como coletar informações sobre interfaces de rede e como gerenciá-las.
networking-main-view.png
Clique no nome da interface desejada na seção Interfaces para acessar a página de gerenciamento. Neste exemplo, a interface eth0 está selecionada.
networking-interfaces-section.png
A parte superior da página de gerenciamento exibe a atividade do tráfego de rede para o dispositivo selecionado. Role para baixo para visualizar as configurações e as opções de gerenciamento.
networking-ens3-details.png
Para modificar ou adicionar opções de configuração a uma interface, clique nos links destacados para a configuração desejada. Neste exemplo, o link IPv4 mostra um único endereço IP e máscara de rede, 172.25.250.10/24, para a interface de rede eth0. Para adicionar um endereço IP adicional à interface de rede eth0, clique no link destacado.
networking-ens3-configure-section.png
Clique em + no lado direito da seleção de lista Manual para inserir um endereço IP adicional. Digite um endereço IP e uma máscara de rede nos campos apropriados. Clique em Apply para ativar as novas configurações.
networking-ipv4-add-new-ip.png
A exibição retorna automaticamente para a página de gerenciamento da interface, na qual você pode confirmar o novo endereço IP.
networking-ipv4-confirm-new-ip.png
Administração de contas de usuário
Como usuário com privilégios, você pode criar novas contas de usuário no console da web. Clique em Accounts na barra de navegação para visualizar as contas existentes. Clique em Create New Account para abrir a página de gerenciamento de contas.
accounts-main-view.png
Insira as informações da nova conta e clique em Create.
accounts-create-new-user.png
A exibição retorna automaticamente para a página de gerenciamento da conta, na qual você pode confirmar a nova conta de usuário.
accounts-verify-new-user.png
Obter ajuda do Red Hat Customer Portal
Objetivos
Depois de concluir esta seção, você deverá ser capaz de descrever os principais recursos disponíveis por meio do Red Hat Customer Portal e usá-los para encontrar informações da documentação da Red Hat e da base de conhecimento. Acesso aos recursos de suporte no Red Hat Customer Portal
O Red Hat Customer Portal (https://access.redhat.com) fornece aos clientes acesso a documentação, downloads, ferramentas e conhecimento técnico. Os clientes podem buscar soluções, perguntas frequentes e artigos na base de conhecimento. No Customer Portal, você pode:
Acessar a documentação oficial do produto.
Enviar e gerenciar tíquetes de suporte.
Gerenciar subscrições e direitos de software.
Obter downloads de software, atualizações e avaliações.
Consultar ferramentas que podem ajudar a otimizar a configuração dos seus sistemas.
Partes do site estão acessíveis a todos, enquanto outras são exclusivas para clientes com subscrição ativa. Obtenha ajuda para acessar o Customer Portal em https://access.redhat.com/help/. Orientações sobre o Customer Portal
Os clientes podem acessar o Red Hat Customer Portal por meio de um navegador. Esta seção apresenta o tour do Customer Portal. O tour pode ser encontrado em https://access.redhat.com/start.
O tour é uma ferramenta muito útil para descobrir tudo o que o portal tem a oferecer e como aproveitar ao máximo sua subscrição da Red Hat. Depois de fazer login no Red Hat Customer Portal, clique em Tour the Customer Portal.
tour-portal.png
A janela WELCOME TO THE RED HAT CUSTOMER PORTAL é exibida com duas opções: CLOSE e NEXT. Clique em NEXT para começar o tour. Esta é a primeira de uma sequência de janelas que destacam diferentes partes da interface.
A barra de navegação superior
As três primeiras paradas no Tour do Customer Portal podem ser encontradas na barra de navegação superior do site do Red Hat Customer Portal:
top-bar.png
Subscriptions abre uma nova página na qual você pode gerenciar seus sistemas registrados e seu uso de subscrições e direitos. Ela lista informações sobre erratas aplicáveis e permite que você crie chaves de ativação que poderá usar ao registrar sistemas para garantir que eles obtenham direitos das subscrições corretas. Observe que, se você fizer parte de uma organização, o administrador da sua organização poderá limitar seu acesso a essa página.
Downloads abre uma nova página que fornece acesso aos downloads do produto e solicita direitos de avaliação para produtos para os quais você não possui direitos.
Support Cases abre uma nova página que fornece acesso para criar, rastrear e gerenciar seus casos de suporte por meio do sistema de gerenciamento de casos, pressupondo que sua organização tenha autorizado esse nível de acesso.
Seu nome é o título para o User Menu, que permite gerenciar sua conta, contas nas quais você é administrador da organização, seu perfil pessoal e opções para notificações de e-mail sobre novos conteúdos disponíveis.
O ícone de globo abre o menu Select Your Language para especificar suas preferências de idioma para o Customer Portal.
Menus de tópicos
Abaixo da barra de navegação superior, na página principal do Customer Portal, estão os menus que você pode usar para navegar em quatro categorias principais de recursos disponíveis no site.
banner.png
Products & Services fornece acesso aos hubs de produtos, páginas que fornecem acesso a avaliações específicas de produtos, visões gerais, guias de introdução e outras informações de suporte ao produto. Você também pode acessar a documentação dos produtos da Red Hat, links diretos para a base de conhecimento de artigos de suporte e informações sobre políticas de suporte, além de como entrar em contato com o suporte da Red Hat.
products-services.png
O menu Tools fornece links para ferramentas que ajudam você a obter sucesso com os produtos da Red Hat. A seção Solution Engine oferece uma maneira eficiente de procurar soluções para seus problemas rapidamente e por produto, além de abrir um tíquete de suporte caso você não encontre uma solução satisfatória. A seção Customer Portal Labs fornece uma coleção de aplicativos baseados na web e ferramentas para ajudar você a melhorar o desempenho, diagnosticar problemas, identificar problemas de segurança e otimizar suas configurações. Por exemplo, o Product Life Cycle Checker permite que você selecione um produto específico e visualize seu cronograma de ciclo de vida de suporte. Outra ferramenta, o Rescue Mode Assistant, ajuda a redefinir a senha root de um sistema, gerar relatórios de diagnóstico ou corrigir problemas no momento do boot com sistemas de arquivos. Mas há muitas outras ferramentas disponíveis nesse site.
tools.png
A seção Security fornece acesso ao Red Hat Product Security Center em https://access.redhat.com/security/. Essa seção também fornece informações sobre questões de segurança de alto nível, acesso ao Red Hat CVE Database, o canal de segurança do Blog da Red Hat e recursos sobre o processo de resposta de segurança da Red Hat e como avaliamos os problemas e os resolvemos.
Por fim, a seção Community é um lugar onde especialistas, clientes e parceiros da Red Hat podem se comunicar e colaborar. Aqui, são disponibilizados fóruns de discussão, blogs e informações sobre os próximos eventos em sua área. Nota
Você deve concluir todo o tour em Introdução à Red Hat, incluindo as seções sobre como personalizar sua experiência do Customer Portal e explorar os benefícios da sua subscrição da Red Hat, a fim de conhecer toda a história do Customer Portal. Você precisará de pelo menos uma subscrição ativa na sua conta do Customer Portal para acessar essa página. Pesquisa na base de conhecimento com a ferramenta de suporte da Red Hat
O utilitário da ferramenta de suporte da Red Hat, redhat-support-tool, fornece uma interface baseada em texto que permite pesquisar artigos da base de conhecimento e casos de suporte a arquivos no Customer Portal a partir da linha de comando do seu sistema. A ferramenta não tem interface gráfica e, como interage com o Red Hat Customer Portal, exige acesso à Internet. Execute o comando redhat-support-tool usando qualquer terminal ou conexão SSH.
O comando redhat-support-tool pode ser usado em um modo interativo ou invocado como um comando com opções e argumentos. A sintaxe da ferramenta é idêntica para ambos os métodos. Por padrão, o programa é executado em modo interativo. Use o subcomando help para ver todos os comandos disponíveis. O modo interativo oferece suporte ao preenchimento com Tab e à capacidade de chamar programas no shell pai.
[user@host ~]$ redhat-support-tool Welcome to the Red Hat Support Tool. Command (? for help):
Quando invocado pela primeira vez, o redhat-support-tool pede informações de login do assinante do Red Hat Customer Portal. Para evitar fornecer essas informações repetidamente, a ferramenta pede para armazenar as informações da conta no diretório pessoal do usuário (~/.redhat-support-tool/redhat-support-tool.conf). Se todos os problemas forem arquivados em uma determinada conta do Red Hat Customer Portal, a opção –global pode salvar informações da conta em /etc/redhat-support-tool.conf, junto com outras configurações em todo o sistema. O comando config da ferramenta modifica as definições de configuração da ferramenta.
O comando redhat-support-tool permite que os assinantes pesquisem e exibam o mesmo conteúdo da base de conhecimento do Red Hat Customer Portal. A base de conhecimento permite pesquisas por palavra-chave, de maneira semelhante à do comando man. Você pode digitar códigos de erro, sintaxe de arquivos de registro ou qualquer combinação de palavras-chave para produzir uma lista de documentos de soluções relevantes.
A seguir, vemos uma configuração inicial e uma demonstração de pesquisa básica:
[user@host ~]$ redhat-support-tool Welcome to the Red Hat Support Tool. Command (? for help): search How to manage system entitlements with subscription-manager Please enter your RHN user ID: subscriber Save the user ID in /home/student/.redhat-support-tool/redhat-support-tool.conf (y/n): y Please enter the password for subscriber: password Save the password for subscriber in /home/student/.redhat-support-tool/redhat-support-tool.conf (y/n): y
Depois de solicitar ao usuário a configuração de usuário necessária, a ferramenta continua com a solicitação de pesquisa original:
Type the number of the solution to view or ’e’ to return to the previous menu. 1 [ 253273:VER] How to register and subscribe a system to the Red Hat Customer Portal using Red Hat Subscription-Manager 2 [ 265523:VER] Enabling or disabling a repository using Red Hat Subscription Management 3 [ 100423:VER] Why does subscription-manager list return: “No Installed Products found” ? …output omitted… Select a Solution: 1
Selecione o artigo número 1 conforme acima e será solicitado que você selecione a seção do documento a ser lido. Por fim, use a tecla Q para sair da seção em que está ou use-a repetidamente para sair do comando redhat-support-tool.
Select a Solution: 1
Type the number of the section to view or ’e’ to return to the previous menu. 1 Title 2 Issue 3 Environment 4 Resolution 5 Display all sections End of options. Section: 1
Title
How to register and subscribe a system to the Red Hat Customer Portal using Red Hat Subscription-Manager URL: https://access.redhat.com/solutions/253273 Created On: None Modified On: 2017-11-29T15:33:51Z
(END) q Section: Section: q
Select a Solution: q
Command (? for help): q [user@hosts ~]#
Acesso aos artigos da base de conhecimento pela ID do documento
Localize artigos on-line diretamente usando o comando kb da ferramenta com a ID de documento da base de conhecimento. Um documento retornado rola na tela sem paginação, mas você pode redirecioná-lo para um arquivo a fim de salvá-lo e usar less para percorrer uma tela por vez.
[user@host ~]$ redhat-support-tool kb 253273
Title
How to register and subscribe a system to the Red Hat Customer Portal using Red Hat Subscription-Manager URL: https://access.redhat.com/solutions/253273 Created On: None Modified On: 2017-11-29T15:33:51Z
Issue
- How to register a new
Red Hat Enterprise Linuxsystem to the Customer Portal usingRed Hat Subscription-Manager…output omitted…
Gerenciamento de casos de suporte com a ferramenta Red Hat Support
Uma das vantagens de uma subscrição de produto é o acesso ao suporte técnico por meio do Red Hat Customer Portal. Dependendo do nível de suporte da subscrição do sistema, a Red Hat poderá ser contatada por meio de ferramentas on-line ou por telefone. Consulte https://access.redhat.com/site/support/policy/support_process para obter informações detalhadas.
Preparação de um relatório de erros
Antes de entrar em contato com o Suporte da Red Hat Support, é importante reunir as informações relevantes para seu relatório de erros.
Defina o problema. Esteja pronto a declarar claramente o problema e seus sintomas. Seja o mais específico possível. Detalhe as etapas que reproduzirão o problema.
Reúna informações de contexto. Qual produto e versão são afetados? Esteja preparado para fornecer as informações de diagnóstico relevantes. Isso pode incluir a saída de sosreport, que será discutida posteriormente nesta seção. Para problemas de kernel, poderão ser incluídas informações do despejo de memória kdump do sistema ou uma imagem digital do backtrace do kernel exibida no monitor de um sistema com falha.
Determine o nível de gravidade. A Red Hat usa quatro níveis de gravidade para classificar problemas. Os relatórios de problemas de gravidade Urgente e Alta devem ser seguidos por uma ligação telefônica para a central de suporte local relevante (consulte https://access.redhat.com/site/support/contact/technicalSupport).
redhat_plan1.png
Gerenciamento de um relatório de bugs com redhat-support-tool
Você pode criar, exibir, modificar e fechar Casos de suporte da Red Hat usando o redhat-support-tool. Quando casos de suporte estão com o status opened ou maintained, os usuários podem anexar arquivos ou documentação, tais como relatórios de diagnóstico (sosreport). A ferramenta envia e anexa arquivos para casos.
Os detalhes do caso, incluindo o nome, a versão, o sumário, a descrição, a gravidade e o grupo do caso do produto podem ser atribuídos com as opções de comando ou aguardando que a ferramenta solicite as informações necessárias. No exemplo a seguir, um novo caso é aberto. As opções –product e –version são especificadas.
[user@host ~]$ redhat-support-tool Welcome to the Red Hat Support Tool. Command (? for help): opencase –product=“Red Hat Enterprise Linux” –version=“7.0” Please enter a summary (or ‘q’ to exit): System fails to run without power Please enter a description (Ctrl-D on an empty line when complete): When the server is unplugged, the operating system fails to continue. 1 Urgent 2 High 3 Normal 4 Low Please select a severity (or ‘q’ to exit): 4 Would you like to assign a case group to this case (y/N)? N Would see if there is a solution to this problem before opening a support case? (y/N) N
Support case 01034421 has successfully been opened.
Se as opções –product e –version não forem especificadas, o redhat-support-tool fornece uma lista de alternativas para essas opções.
[user@host ~]$ redhat-support-tool Welcome to the Red Hat Support Tool. Command (? for help): opencase Do you want to use the default product - “Red Hat Enterprise Linux” (y/N)?: y …output omitted… 29 7.4 30 7.5 31 7.6 32 8.0 Beta Please select a version (or ‘q’ to exit): 32 Please enter a summary (or ‘q’ to exit): yum fails to install apache Please enter a description (Ctrl-D on an empty line when complete): yum cannot find correct repo 1 Urgent 2 High 3 Normal 4 Low Please select a severity (or ‘q’ to exit): 4 Would you like to use the default (Ungrouped Case) Case Group (y/N)? : y Would you like to see if there’s a solution to this problem before opening a support case? (y/N) N
Support case 010355678 has successfully been opened.
Anexar informações de diagnóstico a um caso de suporte
A inclusão de informações de diagnóstico pode levar a uma resolução mais rápida. Anexe o sosreport quando o caso for aberto. O comando sosreport gera um arquivo tar compactado com informações de diagnóstico extraídas do sistema em execução. O redhat-support-tool solicitará a inclusão do arquivo compactado se este tiver sido criado anteriormente:
Please attach a SoS report to support case 01034421. Create a SoS report as the root user and execute the following command to attach the SoS report directly to the case: redhat-support-tool addattachment -c 01034421 path to sosreport
Would you like to attach a file to 01034421 at this time? (y/N) N Command (? for help):
Se não houver um relatório SoS atual, um administrador poderá gerar e anexar um posteriormente. Use o comando redhat-support-tool addattachment para anexar o relatório.
Casos de suporte também podem ser visualizados, modificados e fechados pelo assinante:
Command (? for help): listcases
Type the number of the case to view or ’e’ to return to the previous menu. 1 [Waiting on Red Hat] System fails to run without power No more cases to display Select a Case: 1
Type the number of the section to view or ’e’ to return to the previous menu. 1 Case Details 2 Modify Case 3 Description 4 Recommendations 5 Get Attachment 6 Add Attachment 7 Add Comment End of options. Option: q
Select a Case: q
Command (? for help):q
[user@host ~]$ redhat-support-tool modifycase –status=Closed 01034421 Successfully updated case 01034421 [user@host ~]$
A Ferramenta de Suporte da Red Hat tem capacidades avançadas de análise e diagnóstico de aplicativos. Usando arquivos principais de despejo de falha do kernel, o redhat-support-tool pode criar e extrair um backtrace. Um backtrace é um relatório dos quadros de pilha ativos no ponto de um despejo de falha e fornece diagnósticos no local. Uma das opções do redhat-support-tool é abrir um caso de suporte.
A ferramenta também fornece a análise do arquivo de log. Usando o comando analyze da ferramenta, arquivos de registro de vários tipos, incluindo os do sistema operacional, JBoss, Python, Tomcat e oVirt, poderão ser analisados para reconhecer sintomas dos problemas. Os arquivos de log podem ser visualizados e diagnosticados individualmente. O fornecimento de análises pré-processadas, em vez de dados brutos, como o despejo de memória ou os arquivos de log, permite que os casos de suporte sejam abertos e disponibilizados para os engenheiros mais rapidamente. Juntar-se ao Red Hat Developer
Um outro recurso útil disponível no Red Hat é o Red Hat Developer. Hospedado em https://developer.redhat.com, esse programa fornece direitos de subscrição ao software da Red Hat para fins de desenvolvimento, documentação e livros premium de nossos especialistas em microsserviços, computação sem servidor, Kubernetes e Linux. Um blog, links para informações sobre os próximos eventos e treinamentos e outros recursos de ajuda também estão disponíveis, bem como links para o Red Hat Customer Portal.
O registro é gratuito e pode ser concluído em https://developer.redhat.com/register.
Detecção e solução de problemas com o Red Hat Insights
Objetivos
Depois de concluir esta seção, você deverá ser capaz de usar o Red Hat Insights para analisar os servidores quanto a problemas, corrigi-los ou resolvê-los e confirmar se a solução funcionou. Introdução ao Red Hat Insights
O Red Hat Insights é uma ferramenta de análise preditiva para ajudar você a identificar e corrigir ameaças à segurança, desempenho, disponibilidade e estabilidade em sistemas que executam os produtos da Red Hat em sua infraestrutura. O Insights é entregue como um software como serviço (SaaS), para que você possa implantá-lo e dimensioná-lo rapidamente, sem requisitos adicionais de infraestrutura. Além disso, você pode aproveitar imediatamente as recomendações e atualizações mais recentes da Red Hat específicas para seus sistemas implantados.
A Red Hat atualiza regularmente a base de conhecimentos usada pelo Insights, com base em riscos comuns de suporte, vulnerabilidades de segurança, configurações inválidas conhecidas e outros problemas identificados pela Red Hat. Ações para mitigar ou remediar esses problemas são validadas e verificadas pela Red Hat. Esse suporte permite que você identifique, priorize e resolva problemas proativamente antes que eles se tornem um problema maior.
Para cada problema detectado, o Insights fornece estimativas do risco apresentado e recomendações sobre como atenuar ou remediar o problema. Essas recomendações podem fornecer materiais como os playbooks do Ansible ou instruções passo a passo legíveis para ajudar você a resolver o problema.
O Insights personaliza recomendações para cada sistema registrado no serviço. Você instala cada sistema cliente com um agente que coleta metadados sobre a configuração de tempo de execução do sistema. Esses dados são um subconjunto do que você pode fornecer ao Suporte da Red Hat usando o comando sosreport para resolver um tíquete de suporte. Você pode limitar ou ocultar os dados que o cliente envia Isso bloqueia o funcionamento de algumas das regras analíticas, dependendo do que você limitar.
Quase imediatamente depois de registrar um servidor e concluir a sincronização inicial de metadados do sistema, você poderá ver seu servidor e todas as recomendações para ele no console do Insights no Red Hat Cloud Portal.
O Insights atualmente fornece análises preditivas e recomendações para esses produtos da Red Hat:
Red Hat Enterprise Linux 6.4 e posteriores
Red Hat Virtualization 4 e posteriores
Red Hat OpenShift Container Platform
Red Hat OpenStack Platform 7 e posteriores
Descrição da arquitetura do Insights
Quando você registra um sistema com o Insights, ele imediatamente envia metadados sobre sua configuração atual para a plataforma Insights. Após o registro, o sistema atualiza periodicamente os metadados fornecidos ao Insights. O sistema envia os metadados usando criptografia TLS para protegê-los em trânsito.
Quando o Insights recebe os dados, ele os analisa e exibe o resultado no console da web do Insights em https://cloud.redhat.com/insights.
insights-architecture.svg
Instalação de clientes do Insights
O Insights está incluído no Red Hat Enterprise Linux 8 como parte da subscrição. Versões anteriores dos servidores do Red Hat Enterprise Linux exigem a instalação do pacote insights-client no sistema. Importante
O pacote insights-client substitui o pacote redhat-access-insights a partir do Red Hat Enterprise Linux 7.5.
Se o seu sistema estiver registrado para direitos de software através do serviço Customer Portal Subscription Management, você poderá ativar o Insights com um comando. Use o comando insights-client –register para registrar o sistema.
[root@host ~]# insights-client –register
O cliente do Insights atualiza periodicamente os metadados fornecidos ao Insights. Use o comando insights-client para atualizar os metadados do cliente a qualquer momento.
[root@host ~]# insights-client Starting to collect Insights data for host.example.com Uploading Insights data. Successfully uploaded report for host.example.com. View details about this system on cloud.redhat.com: https://cloud.redhat.com/insights/inventory/dc480efd-4782-417e-a496-cb33e23642f0
Registro de um sistema RHEL com o Insights
Para registrar um servidor do RHEL no Insights, o processo geral é o seguinte:
Registre interativamente o sistema com o serviço Red Hat Subscription Management.
[root@host ~]# subscription-manager register --auto-attach
Certifique-se de que o pacote insights-client está instalado no sistema. No RHEL 7, esse pacote está no canal rhel-7-server-rpms.
Nota
Esta etapa não é necessária nos sistemas do Red Hat Enterprise Linux 8.
[root@host ~]# yum install insights-client
Use o comando insights-client --register para registrar o sistema com o serviço Insights e fazer o upload dos metadados iniciais do sistema.
[root@host ~]# insights-client --register
Confirme se o sistema está visível em Inventory no console da web do Insights em https://cloud.redhat.com/insights.
insights-inventory.png
Navegação no console do Insights
O Insights oferece uma família de serviços que você acessa no console da web em https://cloud.redhat.com/insights. Detecção de problemas de configuração usando o serviço Advisor
O serviço Advisor relata os problemas de configuração que afetam seus sistemas. Acesse o serviço no menu Advisor → Recommentations.
insights-advisor.png
Para cada regra, o Insights oferece informações adicionais para ajudar você a entender o problema, priorizar o trabalho para resolvê-lo, determinar qual mitigação ou remediação está disponível e automatizar sua resolução com o Playbook do Ansible. O Insights também fornece links para artigos da base de conhecimentos no portal do cliente.
insights-advisor-details.png
O serviço Advisor avalia o risco que um problema apresenta ao seu sistema em duas categorias.
Risco total
Indica o impacto do problema no seu sistema.
Risco de mudança
Indica o impacto da ação de correção no seu sistema. Por exemplo, talvez seja necessário reiniciar o sistema.
Avaliação da segurança usando o serviço Vulnerability
O serviço Vulnerability relata vulnerabilidades e exposições comuns (CVEs, Common Vulnerabilities and Exposures) que afetam seus sistemas. Acesse o serviço no menu Vulnerability → CVEs.
insights-vulnerability.png
Para cada CVE, o Insights fornece informações adicionais e lista os sistemas expostos. Você pode clicar em Remediate para criar um Playbook do Ansible para correção.
insights-vulnerability-CVE.png
Análise da conformidade usando o serviço Compliance
O serviço Compliance analisa seus sistemas e relata seu nível de conformidade a uma política do OpenSCAP. O projeto OpenSCAP implementa ferramentas para verificar a conformidade de um sistema com um conjunto de regras. O Insights fornece as regras para avaliar seus sistemas em relação a diferentes políticas, como o padrão de segurança de dados da indústria de pagamento com cartão (PCI DSS, Payment Card Industry Data Security Standard). Atualização de pacotes usando o serviço Patch
O serviço Patch lista os avisos de produto da Red Hat aplicáveis aos seus sistemas. Ele também pode gerar um Playbook do Ansible que você possa executar para atualizar os pacotes RPM associados aos avisos aplicáveis. Para acessar a lista de avisos de um sistema específico, use o menu Patch → Systems. Clique em Apply all applicable advisories para um sistema para gerar o Playbook Ansible.
insights-patch.png
Comparação de sistemas usando o serviço Drift
Usando o serviço Drift, você pode comparar sistemas ou um histórico do sistema. Esse serviço pode ajudar você a solucionar problemas de um sistema comparando esse sistema a um sistema semelhante ou a um estado anterior do sistema. Acesse o serviço no menu Drift → Comparison.
insights-drift.png
Gatilhos de alertas usando o serviço Policies
Usando o serviço Policies, você cria regras para monitorar seus sistemas e enviar alertas quando um sistema não está de acordo com suas regras. O Insights avalia as regras toda vez que um sistema sincroniza seus metadados. Acesse o serviço no menu Policies.
insights-policies.png
Acesso ao inventário e aos Playbooks de correção e monitoramento de subscrições
A página Inventory fornece uma lista dos sistemas que você registrou com o Red Hat Insights. A coluna Last seen exibe a hora da atualização de metadados mais recente para cada sistema. Ao clicar em um nome de sistema, você pode revisar seus detalhes e acessar diretamente os serviços Advisor, Vulnerability, Compliance e Patch desse sistema.
A página Remediations lista todos os Playbooks do Ansible que você criou para correção. Você pode fazer o download dos Playbooks nessa página.
Na página Subscription Watch, você pode monitorar o uso da subscrição da Red Hat.
Capítulo 17. Revisão abrangente
Revisão abrangente Objetivos
Depois de concluir esta seção, os alunos deverão ter analisado e atualizado o conhecimento e as habilidades aprendidas em Red Hat System Administration I. Revisão de Red Hat System Administration I
Para iniciar a revisão abrangente deste curso, os alunos precisam estar familiarizados com os tópicos abordados em cada capítulo.
Os alunos podem consultar as seções anteriores do material didático para estudo adicional.
Capítulo 1, Introdução ao Red Hat Enterprise Linux
Descrever e definir open source, Linux, distribuições do Linux e Red Hat Enterprise Linux.
Definir e explicar a finalidade do Linux, open source, distribuições do Linux e Red Hat Enterprise Linux.
Capítulo 2, Acesso à linha de comando
Faça login em um sistema Linux e execute comandos simples utilizando o shell.
Faça login em um sistema Linux em um console de texto local e execute comandos simples utilizando o shell.
Faça login em um sistema Linux usando o ambiente de área de trabalho GNOME 3 e execute comandos a partir de um prompt do shell em um programa do terminal.
Economize tempo usando o preenchimento com Tab, histórico de comandos e atalhos de edição de comandos para executar comandos no shell Bash.
Capítulo 3, Gerenciamento de arquivos na linha de comando
Copie, mova, crie, exclua e organize arquivos trabalhando no shell Bash.
Descrever como o Linux organiza arquivos e os propósitos de vários diretórios na hierarquia do sistema de arquivos.
Especificar o local dos arquivos relativos ao diretório de trabalho atual e por localização absoluta, determinar e alterar seu diretório de trabalho e listar o conteúdo dos diretórios.
Criar, copiar, mover e remover arquivos e diretórios.
Fazer com que vários nomes de arquivos façam referência ao mesmo arquivo usando links físicos e simbólicos (ou "soft").
Executar com eficiência comandos que afetam muitos arquivos usando recursos de correspondência de padrões do shell Bash.
Capítulo 4, Ajuda no Red Hat Enterprise Linux
Resolver problemas usando sistemas de ajuda locais.
Encontrar informações nas páginas de manual do sistema Linux local.
Encontrar informações da documentação local no GNU Info.
Capítulo 5, Criação, visualização e edição de arquivos de texto
Criar, visualizar e editar arquivos de texto na saída do comando ou em um editor de texto.
Salvar a saída do comando ou erros em um arquivo com redirecionamento de shell e processar a saída do comando por meio de vários programas de linha de comando com pipes.
Criara e editar arquivos de texto usando o editor vim.
Usar variáveis shell para ajudar a executar comandos, e editar scripts de inicialização Bash para definir variáveis shell e de ambiente a fim de modificar o comportamento do shell e os programas executados a partir dele.
Capítulo 6, Gerenciamento de usuários e grupos locais
Criara, gerenciar e excluir usuários e grupos locais do Linux e administrar políticas de senha locais.
Descrever o objetivo dos usuários e grupos em um sistema Linux.
Alternar para a conta de superusuário para gerenciar um sistema Linux e conceder acesso de superusuário a outros usuários usando o comando sudo.
Criar, modificar e excluir contas de usuário definidas localmente.
Criar, modificar e excluir contas de grupo definidas localmente.
Definir uma política de gerenciamento de senha para usuários e bloquear e desbloquear manualmente contas de usuário.
Capítulo 7, Controle de acesso a arquivos
Configurar permissões de sistema de arquivos Linux em arquivos e interpretar os efeitos na segurança de diferentes configurações de permissões.
Listar as permissões do sistema de arquivos em arquivos e diretórios e interpretar o efeito dessas permissões no acesso de usuários e grupos.
Alterar as permissões e a propriedade dos arquivos usando ferramentas de linha de comando.
Controlar as permissões padrão de novos arquivos criados pelos usuários, explicar o efeito de permissões especiais e usar permissões especiais e permissões padrão para definir o proprietário do grupo de arquivos criado em um diretório específico.
Capítulo 8, Monitoramento e gerenciamento de processos do Linux
Avaliar e controlar os processos em execução em um sistema Red Hat Enterprise Linux.
Obter informações sobre programas em execução no sistema para poder determinar o status, o uso de recursos e a propriedade deles e para controlá-los.
Usar controle de tarefa do Bash para gerenciar vários processos iniciados na mesma sessão de terminal.
Controlar e encerrar os processos que não estão associados ao seu shell e forçar a conclusão das sessões e dos processos do usuário.
Descrever qual é a média de carga e determinar os processos responsáveis pelo uso elevado de recursos em um servidor.
Capítulo 9, Controle de serviços e daemons
Controlar e monitorar serviços de rede e daemons do sistema utilizando Systemd.
Listar daemons do sistema e serviços de rede iniciados pelo serviço systemd e pelas unidades de soquete.
Controlar daemons do sistema e dos serviços de rede usando systemctl.
Capítulo 10, Configuração e proteção do SSH
Configurar o serviço seguro da linha de comando em sistemas remotos usando OpenSSH.
Fazer login em um sistema remoto e executar comandos usando ssh.
Configurar autenticação baseada em chave para uma conta de usuário a fim de fazer login em sistemas remotos com segurança e sem uma senha.
Restringir logins diretos como root e desativar a autenticação baseada em senha para o serviço OpenSSH.
Capítulo 11, Análise e armazenamento de logs
Localizar e interpretar com precisão os logs de eventos do sistema para fins de solução de problemas.
Descrever a arquitetura básica de registro em log usada pelo Red Hat Enterprise Linux para registrar eventos.
Interpretar eventos em arquivos relevantes do syslog para solucionar problemas ou revisar o status do sistema.
Localizar e interpretar entradas no diário do sistema para solucionar problemas ou revisar o status do sistema.
Configurar o diário do sistema para manter o registro dos eventos quando um servidor for reinicializado.
Manter a sincronização de horário preciso usando NTP e configurar o fuso horário para garantir data e hora corretas nos eventos registrados pelos logs e pelo diário do sistema.
Capítulo 12, Gerenciamento de redes
Definir configurações e interfaces de rede em servidores Red Hat Enterprise Linux.
Descrever os conceitos fundamentais de endereçamento e roteamento de redes de um servidor.
Testar e inspecionar a configuração atual da rede com utilitários de linha de comando.
Gerenciar configurações e dispositivos de rede usando nmcli.
Modificar as configurações da rede editando os arquivos de configuração.
Configurar o nome do host estático de um servidor e sua resolução de nome e testar os resultados.
Capítulo 13, Arquivamento e transferência de arquivos
Arquivar e copiar arquivos de um sistema para outro.
Arquivar arquivos e diretórios em um arquivo compactado usando tar e extrair o conteúdo de um arquivo compactado tar existente.
Transferir arquivos a partir de um sistema remoto ou para ele usando segurança SSH.
Sincronizar o conteúdo de um arquivo ou diretório local com uma cópia no servidor remoto.
Capítulo 14, Instalação e atualização de pacotes de software
Baixar, instalar, atualizar e gerenciar os pacotes de software da Red Hat e os repositórios de pacotes YUM.
Registrar um sistema em sua conta da Red Hat e atribuir direitos a atualizações de software e serviços de suporte usando o Red Hat Subscription Management.
Explicar como o software é fornecido como pacotes RPM e investigar os pacotes instalados no sistema com o YUM e o RPM.
Encontrar, instalar e atualizar pacotes de software com o comando yum.
Ativar e desativar o uso de repositórios YUM da Red Hat ou de terceiros por um servidor.
Explicar como os módulos permitem a instalação de versões específicas de software, listar, ativar e alternar fluxos de módulos, além de instalar e atualizar os pacotes de um módulo.
Capítulo 15, Acesso a sistemas de arquivos Linux
Acessar, inspecionar e usar os sistemas de arquivos existentes no armazenamento conectado a um servidor Linux.
Explicar o que é um dispositivo de blocos, interpretar os nomes de arquivos dos dispositivos de armazenamento e identificar o dispositivo de armazenamento usado pelo sistema de arquivos para um diretório ou arquivo específico.
Acessar os sistemas de arquivos conectando-os a um diretório na hierarquia do sistema de arquivos.
Procurar arquivos em sistemas de arquivos montados usando os comandos find e locate.
Capítulo 16, Análise e obtenção de suporte
Investigar e resolver problemas na interface de gerenciamento baseada na web, obtendo suporte da Red Hat para ajudar a solucionar problemas.
Ativar a interface de gerenciamento do console da web para gerenciar e monitorar remotamente o desempenho de um servidor Red Hat Enterprise Linux.
Descrever os principais recursos disponíveis por meio do Red Hat Customer Portal e encontrar informações da documentação da Red Hat e da base de conhecimento.
Analisar os servidores quanto a problemas, corrigir ou resolvê-los e confirmar a solução com o Red Hat Insights.